
在深度学习或神经网络中,"循环编码"(Cyclical Encoding)是一种编码技术,其特点是能够捕捉输入或特征中的周期性或循环模式。这种编码方法常用于处理具有周期性行为的任务,比如时间序列预测或理解展示周期性特征的序列。

循环编码的核心思想是将数据的周期性特征转化为网络能够理解的形式。例如,在处理时间数据时,比如小时、日、月等的循环模式,可以使用循环编码来帮助模型识别和利用这些周期性的变化。
当涉及到训练时间序列模型时,通常会使用以下时间特征:
小时、星期、月、周或年中的一天
将时间戳列转换为这些类型的特性是相当容易的。在确保将时间列转换为datetime对象(使用pd.to_datetime)之后,可以使用.dt提取一系列时间序列特征。
df['Hour']=df['Datetime'].dt.hour
df['Month']=df['Datetime'].dt.month
df['Dayofweek']=df['Datetime'].dt.dayofweek
能源消耗数据集通常是时间序列,其最终目标是使用过去的数据预测未来的消耗,因此这是一个很好的用例。虽然其他外部特征,如温度、湿度和风速也会影响能耗,但本文将重点关注时间序列特征的提取和转换。

在能源消耗方面,一天中有一定的高峰时段,更有可能出现更高的消耗。也有一些特定的时间往往消耗较少。从某种意义上说,每个小时都有自己的范畴。
放大该数据集的特定部分就可以展示这一点。全天都有明确的消费模式——使用量在同一时间(下午5 - 6点)达到峰值,在早上5 - 7点达到最低。

这些模式与其他特征有复杂的交互,例如一年中的时间/月份和一周中的一天,这就是为什么我们希望在模型中包含尽可能多的信息的原因。
传统编码的问题
那么我们怎么做呢?如果你像大多数人一样,你早就知道分类特征需要以其他格式编码,以便模型正确地理解它们是什么。最著名的方法是one-hot编码。
One-hot编码简单且易于实现。对于一天(或一个月、一天等)中的任何一个小时,“它是小时/天/月n吗?”然后用二进制0或1来回答这个问题。它对每种类别都这样做。因此,对于1 day_of_week原始特征,您将有7个编码特征(表示一周中的7天):
- is_day_1
- is_day_2
- is_day_3
- is_day_4
- is_day_5
- is_day_6
- is_day_7
在Python中,最简单的方法是使用pd.get_dummies:
columns_to_encode = ['Hour', 'Month', 'Dayofweek']
df = pd.get_dummies(df, columns=columns_to_encode)
这将产生新的特性集。

我们从3个特征(小时、月、日)得到了40多个特征。随着添加越来越多需要编码的时间序列特征,这会变得越来越混乱。
循环编码
这时候就可以到我们提到的循环编码,因为时间序列特征本质上是周期性的。以时间为例当时钟敲响24:00(凌晨12点),新的一天开始,下一个小时是1:00(凌晨1点)。虽然数字1和24实际上是距离最远的数字,但1和23一样接近24,因为它们在一个循环中。
另一种用数字表示时间序列特征的方法是将时间戳转换成正弦和余弦变换。这种方式会告诉你一天中的时间,一周中的时间,或者一年中的时间。
我们需要的编码不是将日期时间值转换为分类特征(就像我们使用one-hot编码一样),而是将它们转换为数值特征,其中一些值更接近(例如12AM和1AM),而其他值则更远(例如12AM和12PM)。但当我们用One-hot编码时,这种信息就丢失了。
正弦和余弦来自单位圆,可以映射时间戳在这个圆上的位置,用正弦和余弦坐标表示。将圆圈的右侧视为起点(在下面的图表中以0表示)或真正的24小时时间刻度上的00:00 (12AM),我们将其划分为4个6小时的地标,以便能够将小时映射到圆上。
当你在单位圆上逆时针移动时,它增加到/2(或90度),这相当于6:00AM,(180度)或12:00PM, 3 /2或6:00PM,最后在12:00 am回到0。这些时间点都有自己独特的坐标。这样就可以用正弦和余弦表示24小时的每日周期。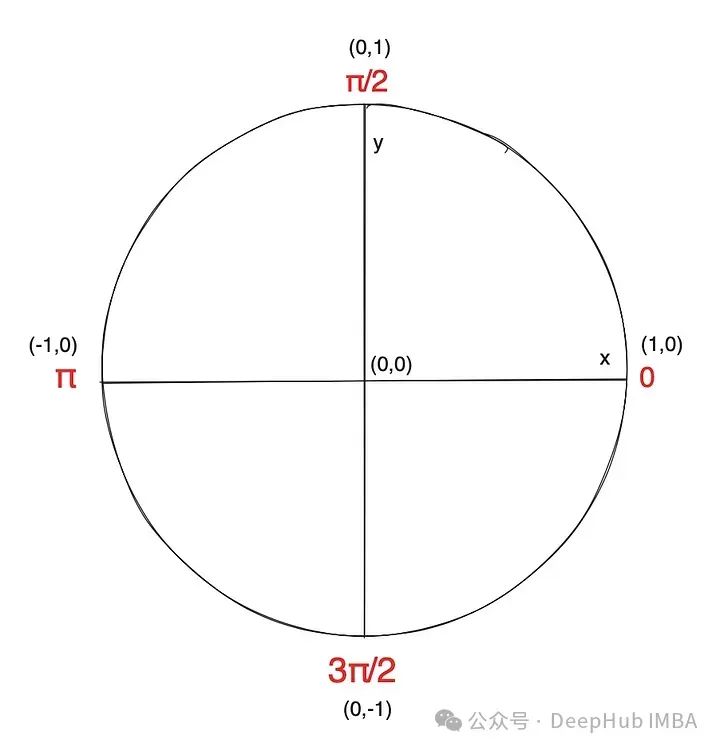
其他周期也可以这样做,比如一周或一年的时间,一般的公式如下:

要在Python中完成此操作,需要首先将datetime(在我的示例中是小时时间戳)转换为数值变量。通过将该列转换为pd.Timestamp.timestamp对象,将每个时间戳转换为unix时间(自1970年1月1日以来经过的秒数)。然后把这个数值列变换成正弦和余弦的特征。
# Convert datetime into a numerical seconds timestamp object
# (tells you the date/time in seconds)
timestamp_s = df['Datetime'].map(pd.Timestamp.timestamp)
# Get the number of seconds for each time period
day = 24*60*60
week = day*7
year = day*(365.2425)
# Transform using sin and cos
# Time of day
df['Day_sin'] = np.sin(timestamp_s * (2 * np.pi / day))
df['Day_cos'] = np.cos(timestamp_s * (2 * np.pi / day))
# Time of week
df['Week_sin'] = np.sin(timestamp_s * (2 * np.pi / week))
df['Week_cos'] = np.cos(timestamp_s * (2 * np.pi / week))
# Time of year
df['Year_sin'] = np.sin(timestamp_s * (2 * np.pi / year))
df['Year_cos'] = np.cos(timestamp_s * (2 * np.pi / year))
上面的代码解释如下:首先将时间戳从秒转换为弧度。2 * np.pi 是因为一个完整的圆/周期有2pi的弧度。转换后除以的周期持续时间(以秒为单位)(日、周或年)。然后就可以将每个时间戳映射到一个唯一的角度,该角度通过乘以弧度数来表示它在周期中的位置。
如果周期是day,那么一天开始的时间戳将被映射到0弧度,一天中间的时间戳将被映射到np.pi,一天结束时的时间戳将被映射为2 * np.pi 。
最后对计算结果进行sin和cos,得到单位圆上实际的x和y坐标值。这些值总是在-1到1之间。
通过这种方法,每个原始时间序列特征(例如一天中的小时,一周中的一天,一年中的月份)现在只映射到2个新特征(原始特征的sin和cos),而不是24,7,12等。
缺点和注意事项
使用这种方法时一定要小心。虽然它非常方便和高效,但也有一些缺点和注意事项:
1、One-hot编码可以更好地用于基于特定时间、月份等具有更一致的不同值的数据集-例如,数据集在中午12点或某个月份达到峰值。而在时间范围更大的数据集(12PM-2PM)中,循环编码等方法一般会更准确。
2、这种类型的编码适用于深度学习/神经网络,但可能不适用于随机森林这样的树分割算法。因为通常表示一个特征的单个时间戳被分割成两个特征,而基于树的算法每次只分割一个特征。这两个特征是对应于一个原始特征的坐标对,而树形模型可能将它们分开处理。
但是这并不是说你永远不能对基于树的算法使用循环编码。我实际上在随机森林模型中使用了这种类型的编码,并取得了很好的效果。还是我们的老生常谈,这将取决于数据集,所以在交叉验证和最终hold out测试集上运行测试是很重要的。
这种编码方式在各种应用中都非常有用,尤其是在预测和分析涉及明确周期或重复模式的数据时。但是在决定使用哪种编码之前,将编码结果进行比较是非常重要的。
本文的数据集:
https://www.kaggle.com/datasets/robikscube/hourly-energy-consumption
作者:Haden P