强得离谱,AI音乐的 Stable Diffusion: MusicGen
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。Meta 推出了一个基于深度学习的AI音频处理库 AudioCraft,其中包含了
【AI大数据与人工智能】Spark SQL 原理与代码实例讲解
在大数据时代,数据处理和分析成为了一项关键的任务。Apache Spark 作为一个开源的大数据处理框架,凭借其高效的内存计算能力和通用性,已经成为了大数据领域中最受欢迎的技术之一。Spark SQL 作为 Spark 的一个重要模块,为结构化数据处理提供了强大的功能支持。Spark SQL 不仅支
【大模型应用开发 动手做AI Agent】基于大模型的Agent技术框架
随着人工智能技术的快速发展,特别是自然语言处理和大模型技术的突破,基于大模型的Agent(代理)技术正在成为人工智能应用的新热点。Agent技术旨在创建能够自主执行任务、与人交互的智能软件系统,在客户服务、个人助理、智能教育等领域具有广阔的应用前景。本文将深入探讨基于大模型的Agent技术框架,阐述
毕业设计:基于深度学习的图像去噪算法 人工智能
毕业设计:基于深度学习的图像去噪算法通过深度学习模型的训练和优化,能够准确还原图像的真实信息,并有效去除图像中的噪声。本研究为计算机毕业设计提供了一个创新的方向,结合了深度学习和计算机视觉技术,为毕业生提供了一个有意义的研究课题。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,提
AI:175-使用Python进行深度学习模型的训练和部署
我们将使用MNIST数据集,这是一个手写数字识别的标准数据集。它包含60,000个训练样本和10,000个测试样本,每个样本是28x28像素的灰度图像。本文详细介绍了如何使用Python进行深度学习模型的训练和部署。通过实战案例,我们展示了从数据预处理、模型构建、训练、优化到部署的整个过程。同时,我
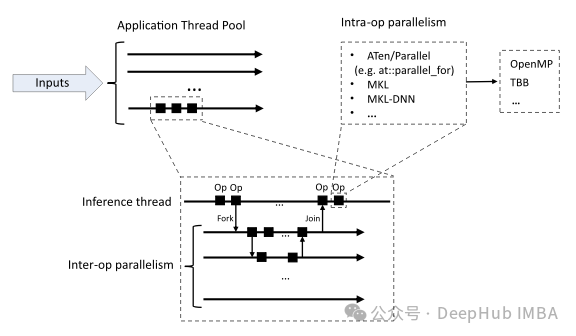
PyTorch中的多进程并行处理
这篇文章我们将介绍如何利用torch.multiprocessing模块,在PyTorch中实现高效的多进程处理。
Kafka Producer原理与代码实例讲解
Kafka Producer原理与代码实例讲解1.背景介绍Apache Kafka 是一个分布式流处理平台,广泛应用于实时数据流处理、日志收集、事件源系统等场景。Kafka 的核心组件之一是 Producer,它负责将数据发布到 Kafka 主题中。理解 Kafka Pro
人工智能--循环神经网络
循环神经网络是一类具有反馈连接的神经网络,能够处理任意长度的序列数据,通过在隐藏层中引入循环连接,使得网络能够记住过去的信息,并将其用于当前的计算。
2024年6月后2周重要的大语言模型论文总结:LLM进展、微调、推理和对齐
本文总结了2024年6月后两周发表的一些最重要的大语言模型论文。这些论文涵盖了塑造下一代语言模型的各种主题,从模型优化和缩放到推理、基准测试和增强性能。
stable diffusion无限贴近真人的调教方法,助力AI变现(下)
做漫画效果时,看用户想要哪种效果:1、完全根据原图画面来出,则直接使用 linear 线稿进行控制即可,现在大部分产品的人转漫画,就是这个方式。2、想用一张真人图参考,最大还原发型,随意变换姿势,可使用 controlnet 的 IP Adapter 模型。但这个方法比较适用于人转漫,如果想出比较写
基于Docker的PyTorch深度学习环境配置(Ubuntu 22.04)
在个人主机上面配置基于docker的pytorch深度学习环境,并配置了pycharm可以直接调用docker中的环境。
Keras深度学习框架实战(6):使用CNN-RNN架构实现视频分类
视频分类任务是将视频按内容分类的重要计算机视觉任务,常用于推荐系统和安全监控等领域。常使用CNN-RNN混合模型处理视频的空间和时间特征。在UCF101数据集上训练模型,通过预训练CNN提取帧特征,RNN处理时序信息,最终通过全连接层进行分类。实验结果通过准确率评估,模型可用于视频推荐和异常检测。为
【AI开发:音频】一、GPT-SoVITS整合工具包的部署问题解决(GPU版)
目前GPT-SoVITS的合成效果比较不错,相比较其他厂商的产品要规整的多。众多厂家中也是国内使用最多的一款了,并且这个整合包里携带了,除背景音、切割、训练、微调、合成、低成本合成等一些列完整的工具,也可以作为API进行使用。本文中,使用GPT-SoVITS-beta0306fix2说了下在部署过程
开源模型应用落地-FastAPI-助力模型交互-WebSocket篇(四)
使用FastAPI提高AI应用程序的开发效率和用户体验,为 AI 模型的部署和交互提供全方位的支持。

RouteLLM:高效LLM路由框架,可以动态选择优化成本与响应质量的平衡
该论文提出了一个新的框架,用于在强模型和弱模型之间进行查询路由选择。通过学习用户偏好数据,预测强模型获胜的概率,并根据成本阈值来决定使用哪种模型处理查询 。该研究主要应用于大规模语言模型(LLMs)的实际部署中,通过智能路由在保证响应质量的前提下显著降低成本。
MLP多层感知器:AI人工智能神经网络的基石
MLP 是指多层感知器(Multilayer Perceptron),是一种基础人工神经网络模型(ANN,Artificial Neural Network)。MLP 能够将信息逐层重新组合,每层重组的信息经过激活函数的放大或抑制后进入下一层的数据重组,从而实现特征提取和知识获取。
AI人工智能深度学习算法:深度学习代理的安全与隐私保护
1.背景介绍随着人工智能(AI)技术的发展,深度学习代理作为AI的一个关键组成部分,在游戏、机器人、自动驾驶汽车等领域得到了广泛应用。然而,这些代理在实际应用中面临着安全性和隐私保护的挑战。本文将探讨深度学习代理的安全性问题、隐私保护需求以及相应的解决方案。2.核心概念与联系深度学习代理
【专利】一种光伏产品缺陷检测AI深度学习算法
本发明公开一种光伏产品缺陷检测AI深度学习算法,涉及AI算法领域。该光伏产品缺陷检测AI深度学习算法,采用深度卷积神经网络作为预训练模型,使用特征金字塔网络结构FPN对预训练模型得到的不同尺度的特征图进行融合,采用区域提议网络RPN在特征图上生成候选框,该光伏产品缺陷检测AI深度学习算法通过使用预训
Flink的实时教育数据分析与优化
Flink的实时教育数据分析与优化作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming关键词:Apache Flink, 实时数据流处理, 教育数据分析, 数据仓库优化, 实时反馈机制1.背景介绍
FlinkAsyncI_O的最佳实践
FlinkAsyncI/O的最佳实践1. 背景介绍在现代数据处理系统中,异步I/O操作扮演着至关重要的角色。由于数据源通常是外部系统(如数据库、消息队列或Web服务),因此I/O操作往往是整个数据处理管道中的瓶颈。传统的同步I/O方式会导致大量线程被阻塞,从而浪费宝贵的计算资源。相比



