
AlphaFold3 是 DeepMind 开发的一款蛋白质结构预测软件,它在AlphaFold2的基础上进行了改进。其中最主要的一个改进就是引入了扩散模型,这使得扩散模型不仅仅可以应用于文生图,其实扩散模型早已经在各个领域中都又所发展,今天我们就来研究一下扩散模型的多元化应用。
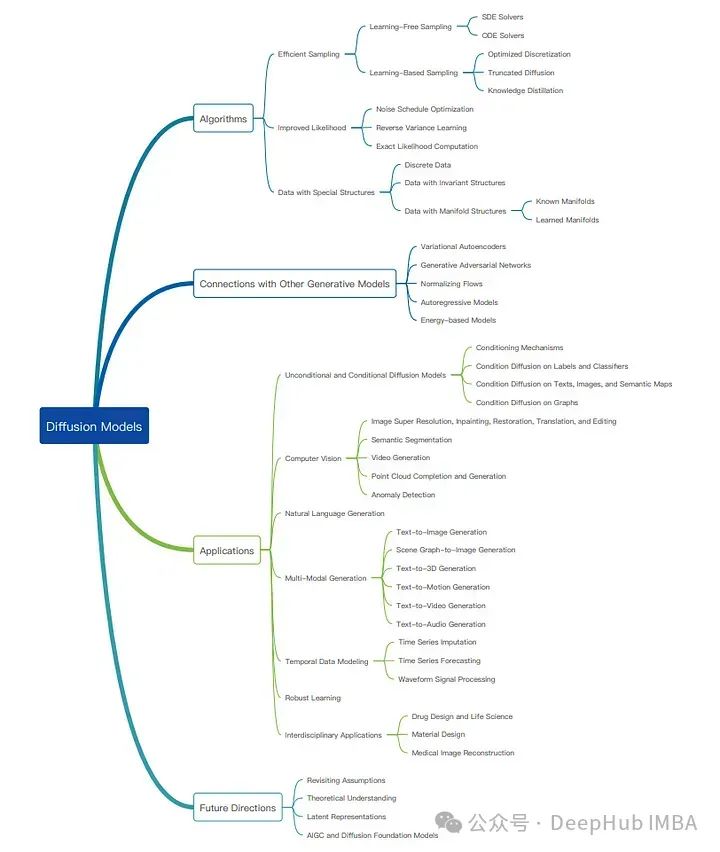
扩散模型
我们先从扩散模型说起,如果你了解扩散模型,可以跳过本节
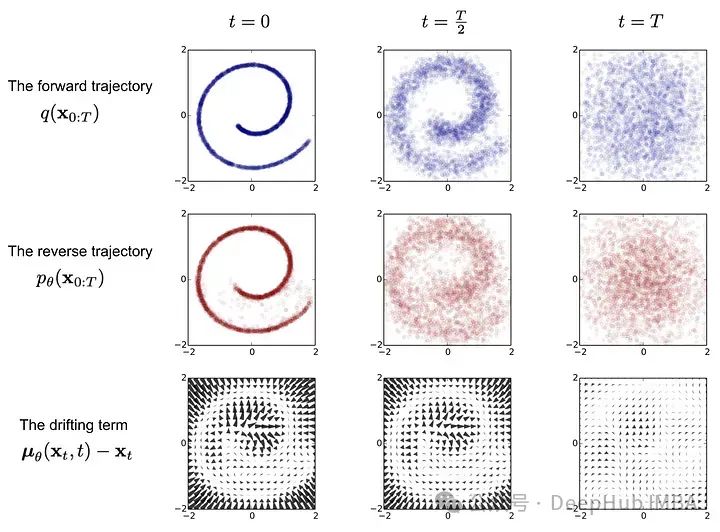
扩散模型是基于噪声和去噪输入。虽然细节各不相同,但我们可以将基于扩散的生成归结为两个步骤-
前向扩散:我们取一个数据样本,如图像,并在每一步中迭代地加入少量的高斯噪声。这慢慢地损坏图像,直到它变成无法识别的噪声。模型学习在每一步中添加的噪声模式,这对于逆过程至关重要。

逆向扩散:我们从第一步的纯噪声开始输入。模型预测前向过程中每一步添加的噪声并将其去除。这逐步去除输入的噪声,逐渐将其转换为有意义的数据样本。

扩散过程有很多重要的数学细节,所以我们这里做了大量的简化,只做最主要的一些细节论述
生成过程的迭代性质,涉及许多去噪步骤,需要大量的计算能力和时间,特别是对于高分辨率数据。这使得它们在实时应用程序或资源受限环境中不太实用。为了提高效率,研究人员正在探索几种途径,包括优化的采样技术,这些技术旨在减少去噪步骤的数量同时保持样本质量。此外,探索潜在空间的扩散可以显著减轻计算负担。

最后,将dm与其他技术(如压缩和其他生成器)结合起来也可以以提高效率。
扩散模型的功能有哪些呢?
高质量生成:扩散模型能够生成具有异常高质量和现实感的数据,这得益于它们通过迭代去噪过程学习数据分布的能力。
多功能性:扩散模型在处理多种数据类型上显示出惊人的灵活性,包括图像、音频、分子等。
逐步控制:扩散模型的逐步生成过程允许用户在最终输出上施加更大的控制权。
为什么扩散模型如此有效?
扩散模型如此有效的一个原因是其逐步去噪的能力,这类似于自回归模型的逐步生成,但扩散模型在每个时间步重新考虑整个输入,使其能在上下文中进行更好的调整。
扩散模型的应用
1、视觉相关任务
扩散模型在图像合成、编辑和超分辨率方面显示出优越的能力,这个也是我们最长间的方式

在视觉方面提高解析度产生更高解析度的影像。像SR3和CDM这样的扩散模型通过迭代去噪来逐步细化图像,从而获得高质量的升级。
另外扩散不仅可以用来填充图像中缺失或损坏的部分。它可以用来在特定的部分中填写全新的部分。

医学图像重建-医学图像是昂贵的。它们更难注释,因为只有专业人士才能这样做。DMs在医学图像重建方面显示出巨大的前景。
另外扩散模型可以通过添加噪声和重建干净的版本来净化对抗性示例,减轻对抗性扰动的影响。我们还可以基于扩散的预处理步骤来增强模型对对抗性攻击的鲁棒性。

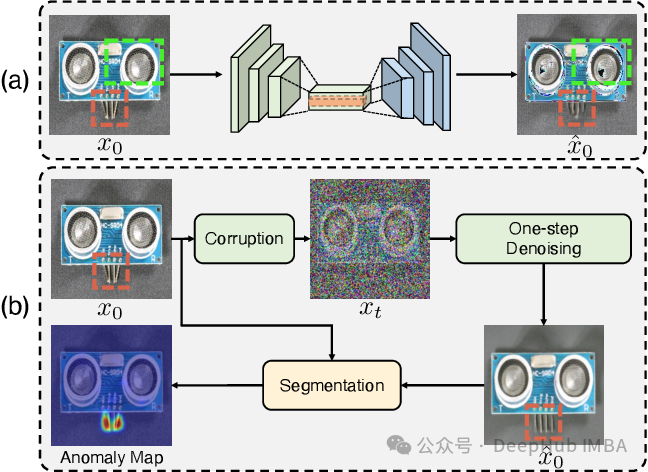
扩散模型可用于识别图像中的异常或意外模式。“这些方法可能比基于对抗性训练的替代方法表现得更好,因为它们可以通过有效的采样和稳定的训练方案更好地模拟较小的数据集。”
2、文本处理
尽管在机器翻译方面稍显逊色,扩散模型在代码合成和问答任务中表现出色,甚至超过自动回归模型。
《Transfer Learning for Text Diffusion Models》这篇论文发布了一个AR2Diff的轻量级模型
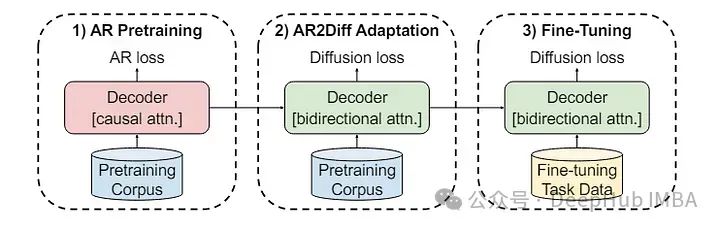
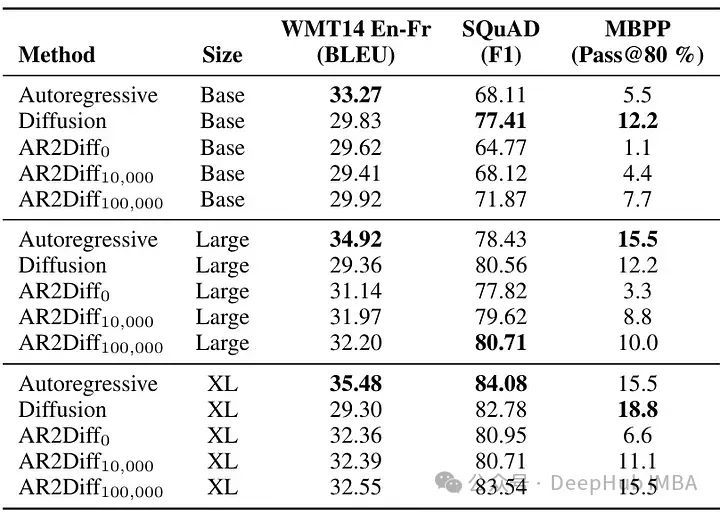
虽然文本扩散在机器翻译中落后,但它在代码合成和问题回答方面显示出前景,甚至优于自回归模型。这些发现表明,对于长文本来说,文本传播速度更快。
微软的GENIE在论文《Text generation with diffusion language models: a pre-training approach with continuous paragraph denoise》中介绍,是LLM的另一个有趣的扩散模型的例子。
GENIE是一个大规模预训练的扩散语言模型,由一个编码器和一个基于扩散的解码器组成,它可以通过逐步将随机噪声序列转换成连贯的文本序列来生成文本。实验结果表明,在这些基准测试中,GENIE达到了与最先进的自回归模型相当的性能,并且生成了更多样化的文本样本。
Text Diffusion似乎是基于编码器和基于解码器的lm的桥梁,这个方向的研究应该很有意思,当然也和有挑战。
3、音频+视频生成
许多高质量的音频和视频生成器也依赖于扩散模型。“Grad-TTS提出了一种新的文本-语音模型,该模型具有基于分数的解码器和扩散模型。它逐渐变换编码器预测的噪声,并通过单调对齐搜索(Monotonic Alignment Search)的方法进一步与文本输入对齐。Grad-TTS2以自适应方式改进了Grad-TTS。Diffsound提出了一种基于离散扩散模型的非自回归解码器,它在每一步中预测所有的梅尔谱图标记,然后在接下来的步骤中对预测的标记进行细化。EdiTTS利用基于分数的文本到语音模型来改进粗略修改的mel谱图。ProDiff不是估计数据密度的梯度,而是通过直接预测干净数据来参数化去噪扩散模型。
4、时域数据建模
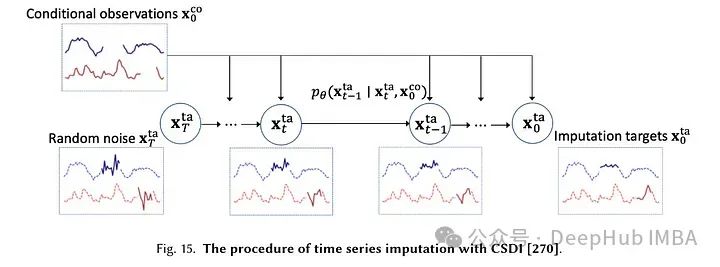
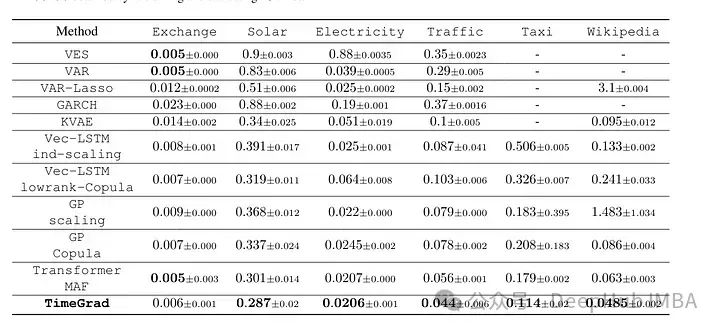
对于基于时间序列的数据来说,缺少数据可能是一个巨大的问题,DMs可以处理TS的数据输入。CSDI利用基于分数的扩散模型,以自监督的方式训练来捕获时间相关性,以实现有效的时间序列输入。“与现有的基于分数的方法不同,条件扩散模型经过明确训练,可以利用观测值之间的相关性。在医疗保健和环境数据方面,CSDI在流行的性能指标上比现有的概率估算方法提高了40-65%。与目前最先进的确定性归算方法相比,CSDI的确定性归算误差降低了5-20%。CSDI还可以应用于时间序列插值和概率预测,并且与现有基线具有竞争力。”
预测时间序列中的未来值,对于各种预测任务都很重要。以TimeGrad为例,它是一种自回归模型,使用扩散概率模型来估计数据分布的梯度。作者表明,该方法“是对具有数千个相关维度的真实数据集的最新的最先进的多元概率预测方法”。
可以看到扩散模型不仅仅是简单的图像生成器。它在各个方面都有着不同的用途
总结
扩散模型作为一种先进的生成技术,已经超越了其最初的图像生成应用范围。这种模型通过在数据上添加和逐步去除噪声的方法,可以生成高质量、高逼真度的数据样本。在图像处理领域,扩散模型已经显示出了卓越的能力,如在高分辨率图像合成、图像编辑和医学图像重建等方面的应用。然而,其应用领域并不仅限于此。
随着技术的发展,扩散模型已经开始在其他多个领域显示出其独特的潜力,尤其是在自然语言处理中。在这一领域,扩散模型通过逐步改进文本生成过程,展现出与传统自回归模型相媲美甚至优于的性能。此外它们在音频和视频生成、时间序列预测和处理,以及更广泛的数据分析和模型鲁棒性提高等方面也具有重要应用。
扩散模型的这种多样化应用不仅展示了它们在技术上的灵活性,也预示着这种模型将继续扩展其影响力,可能会改变更多科技领域的未来。随着研究的深入和技术的改进,扩散模型无疑将在AI发展中扮演越来越重要的角色
作者:Devansh