ReadAgent,一款具有要点记忆的人工智能阅读代理
ReadAgent的工作流程,包括分页、主旨压缩和交互式查找Figure 1展示了 ReadAgent 的工作流程,这是一个模仿人类阅读习惯设计的系统,旨在有效处理和理解长文本。分页(Episode Pagination):系统将长文本分解为一系列较小的、逻辑上连贯的文本块,即“剧集”,类似于将一本
【AI大数据计算原理与代码实例讲解】ElasticSearch
作者:禅与计算机程序设计艺术Artificial Intelligence; 大数据: Big Data; Elasticsearch: 数据检索引擎背景介绍 - Introduction在当今这个数据爆炸的时代,企业及个人越来越依赖于数据分析和处理能力。面对海量的数据集,传统的数据库系统往

使用vLLM在一个基座模型上部署多个lora适配器
在本文中,我们将看到如何将vLLM与多个LoRA适配器一起使用。我将解释如何将LoRA适配器与离线推理一起使用,以及如何为用户提供多个适配器以进行在线推理。
Spark Streaming原理与代码实例讲解
随着大数据时代的到来,对实时数据处理的需求日益增加。传统的批处理模式已经无法满足业务对实时性的要求。Spark Streaming作为一种基于Spark的流式计算框架,能够以接近实时的速度处理大规模的数据流,并提供了丰富的流式计算API,为用户提供了一种简单易用的流式数据处理方案。Spark Str
Spark Stage原理与代码实例讲解
Spark采用DAG(有向无环图)结构来表示计算任务,DAG中的每个节点代表一个操作,边表示数据依赖。Spark Stage划分算法根据DAG结构,将DAG分解为最小的并行可执行单元,即Stage。每个Stage对应一个独立的内存空间,用于存储中间结果和执行计算任务。通过深入研究Spark Stag
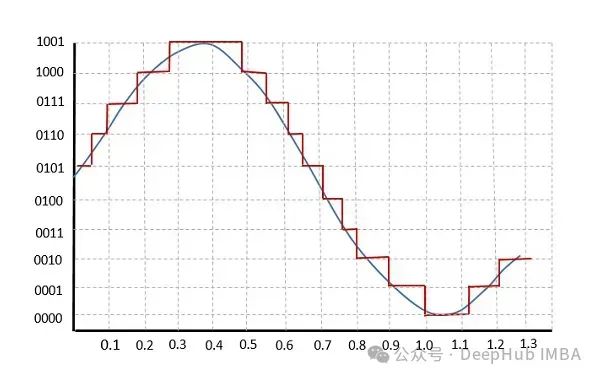
用PyTorch 从零开始构建 BitNet 1.58bit
我们手动实现BitNet的编写,并进行的一系列小实验证实,看看1.58bit 模型是否与全精度的大型语言模型相媲美!
AI:204-使用深度学习改进自然语言生成对话系统【技术、模型与实践】
从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。每一个案例都附带关键代码,详细讲解供大家学习,希望可以帮到大家。正在不断更新中~
Transformer和Mamba强强结合!最新混合架构全面开源,推理速度狂飙8倍
最近发现,,效果会比单独使用好很多,这是因为该方法结合了Mamba的长序列处理能力和Transformer的建模能力,可以显著提升计算效率和模型性能。典型案例如大名鼎鼎的Jamba:Jamba利用Transformer架构的元素增强Mamba 结构化状态空间模型技术,提供了 256K 上下文窗口,吞
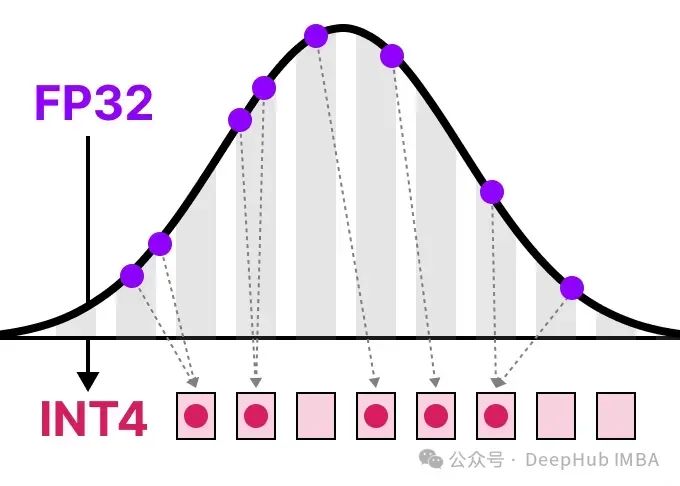
模型量化技术综述:揭示大型语言模型压缩的前沿技术
在这篇文章中,我将在语言建模的背景下介绍量化,并逐一探讨各个概念,探索各种方法论、用例以及量化背后的原理。
Mooncake:LLM服务的KVCache为中心分解架构
24年6月AI公司月之暗面的技术报告“Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving”。
时空预测又爆火了!新SOTA实现零样本精准预测
时空预测又有新突破啦!港大、华南理工等提出了时空大模型UrbanGPT,在性能上猛超现有SOTA,实现零样本即可时空预测!另外还有清华的首个通用城市时空预测模型UniST、能即插即用快速适配的时空提示调整机制FlashST...这些效果非常nice的研究都被ICML等各大顶会顶刊收录,可见目前有关时
【PyTorch】多对象分割项目
对象分割任务的目标是找到图像中目标对象的边界。实际应用例如自动驾驶汽车和医学成像分析。这里将使用PyTorch开发一个深度学习模型来完成多对象分割任务。多对象分割的主要目标是自动勾勒出图像中多个目标对象的边界。对象的边界通常由与图像大小相同的分割掩码定义,在分割掩码中属于目标对象的所有像素基于预定义
【传知代码】LAD-GNN标签注意蒸馏(论文复现)
在当今的数据科学领域,Graph Neural Networks (GNNs) 已成为处理图结构数据的强大工具。然而,传统的GNN在图分类任务中面临一个重要挑战——嵌入不对齐问题。本文将介绍一篇名为“Label Attentive Distillation for GNN-Based Graph C
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
本文对transformers之pipeline的图像分割(image-segmentation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用计算机视觉中的图像分割(image-segmentation
Transformer预测模型及其Python和MATLAB实现
通过将输入的查询、键和值线性变换为多个不同的头部,然后并行计算每个头的注意力,最后将所有头的结果拼接后经过线性变换。- **查询(Query)、键(Key)和值(Value)**:对输入的词嵌入进行线性变换,得到查询、键和值。- **解码器**:解码器结构类似于编码器,但在每个层中加入了对先前生成的
【AI大数据计算原理与代码实例讲解】Hadoop
【AI大数据计算原理与代码实例讲解】Hadoop作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming关键词:Hadoop, 分布式计算, 大数据, 数据处理框架, YARN, MapReduce1
Pyinstaller打包OSError: could not get source code【终极解决】
pyinstaller 打包报错 torch.jit.script
探索LLaMA模型:架构创新与Transformer模型的进化之路
LLaMA模型代表了一种先进的人工智能技术,能够在自然语言处理(NLP)任务上表现出卓越的能力,如文本生成、问答、对话交互、机器翻译以及其他基于语言的理解和生成任务。LLaMA模型家族的特点在于包含了不同参数规模的多个模型版本,参数量从70亿(7B)至650亿(65B)不等。这些模型设计时借鉴了Ch
【机器学习】基于3D CNN通过CT图像分类预测肺炎
本文深入探讨了3D卷积神经网络(3D CNN)在CT图像肺炎分类预测中的应用。通过构建高效的3D CNN模型,结合精确的数据预处理和增强技术,实验结果表明该模型在医学影像诊断中具有显著的潜力。尽管面临数据规模和计算资源的挑战,但通过模型优化和跨学科合作,有望进一步提升性能。未来研究将着眼于扩大数据集
认识神经网络【多层感知器数学原理】
简单认识神经网络,学习多层感知器的数学原理和公式



