
在时间序列预测领域中,模型的体系结构通常依赖于多层感知器(MLP)或Transformer体系结构。
基于mlp的模型,如N-HiTS, TiDE和TSMixer,可以在保持快速训练的同时获得非常好的预测性能。基于Transformer的模型,如PatchTST和ittransformer也取得了很好的性能,但需要更多的内存和时间来训练。
有一种架构在预测中仍未得到充分利用:卷积神经网络(CNN)。CNN已经应用于计算机视觉,但它们在预测方面的应用仍然很少,只有TimesNet算是最近的例子。但是CNN已经被证明在处理序列数据方面是有效的,并且它们的架构允许并行计算,这可以大大加快训练速度。
在本文中,我们将详细介绍了BiTCN,这是2023年3月在《Parameter-efficient deep probabilistic forecasting》一文中提出的模型。通过利用两个时间卷积网络(TCN),该模型可以编码过去和未来的协变量,同时保持计算效率。
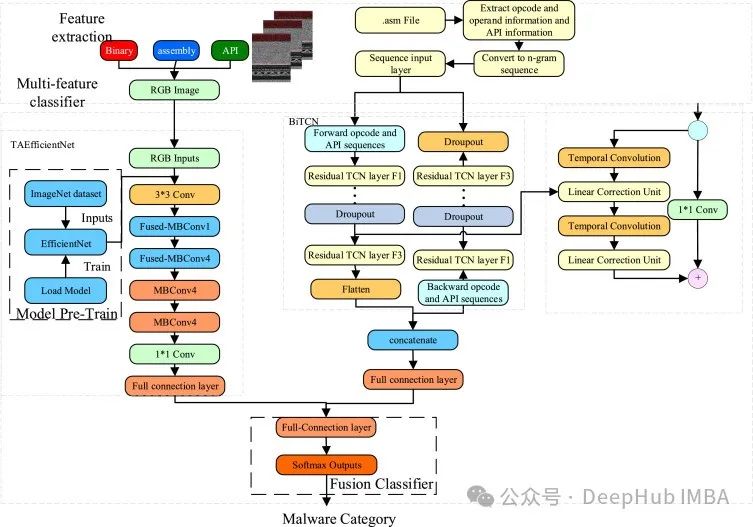
BiTCN
BiTCN使用了两个时间卷积网络,因此被称为BiTCN。一个TCN负责编码未来的协变量,而另一个负责编码过去的协变量和序列的历史值。这样模型可以从数据中学习时间信息,并且卷积的使用保持了计算效率。
让我们仔细看看它的架构,BiTCN的体系结构由许多临时块组成,其中每个块由:
一个扩张卷积,一个GELU激活函数,然后是dropout ,最后紧接着一个全连接的层
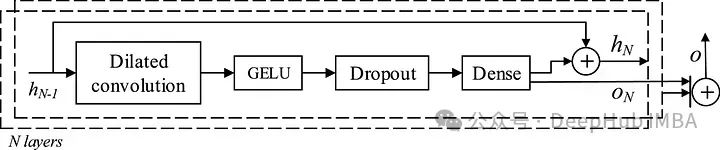
上图中可以看到每个时态块产生一个输出o,最终的预测是将每个块的所有输出叠加在N层中得到的。
虽然dropout层和全连接层是神经网络中常见的组件,所以我们详细地扩张卷积和GELU激活函数。
扩张卷积
为了更好地理解扩展卷积的目的,我们回顾一下默认卷积是如何工作的。
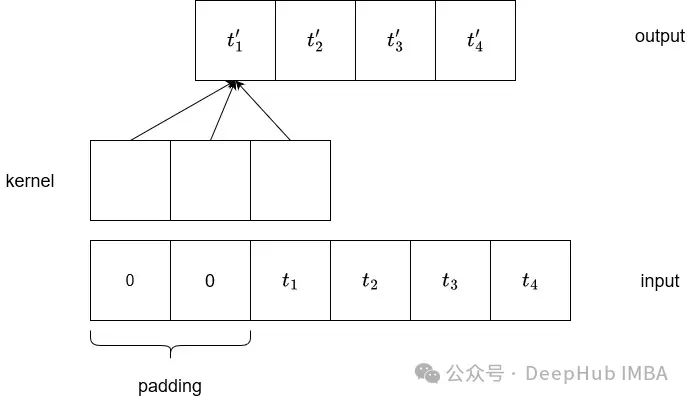
在上图中,我们可以看到一维输入的典型卷积。输入序列左填充零,以确保输出长度相同。
如果核大小为3,步幅为1,,则输出张量的长度也为4。
可以看到,输出的每个元素都依赖于三个输入值。也就是说输出取决于索引处的值和前两个值。
这就是我们所说的感受野。因为我们正在处理时间序列数据,所以增加接受域将是有益的,这样输出的计算可以着眼于更长的历史。
我们可以简单的增加核的大小,或者堆叠更多的卷积层。但增加内核大小并不是最好的选择,因为可能会丢失信息,并且模型可能无法学习数据中的有用关系。那么叠加更多的卷积如何呢?
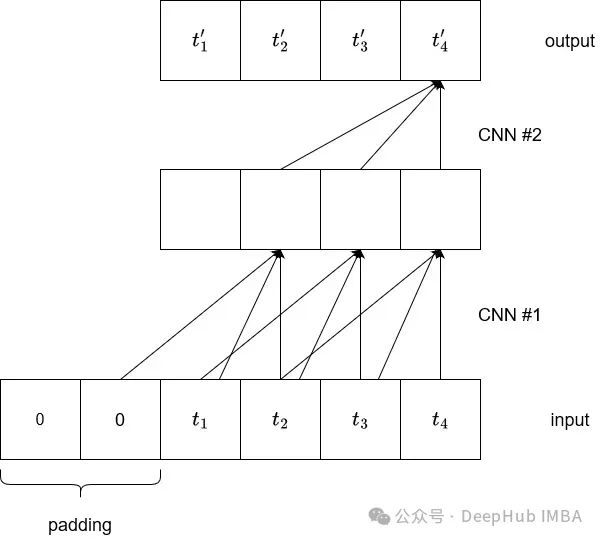
可以看到,通过使用核大小为3的卷积操作堆叠两个卷积,输出的最后一个元素现在依赖于输入的五个元素,感受野从3个增加到5个。
但是以这种方式增加接受野将导致非常深的网络,所以就出现了使用扩展卷积,它可以在增加感受野,同时避免向模型添加太多层

在上图中,我们可以看到运行扩展卷积的结果。每两个元素都会生成一个输出。因此可以看到,我们现在有5个感受野,而不需要堆叠卷积。
为了进一步增加接受野,我们使用膨胀基数(通常设置为2)堆叠许多稀释的核。这意味着第一层将是2¹膨胀的核,然后是2²膨胀的内核,然后是2³,以此类推。
这样模型可以考虑更长的输入序列来生成输出。通过使用膨胀基数可以保持合理的层数。
GELU激活函数
许多深度学习架构采用了ReLU激活函数。

可以看到ReLU只是取0和输入之间的最大值。也就是说如果输入为正,则返回输入。如果输入为负,则返回零。
虽然ReLU有助于缓解梯度消失的问题,但它也会产生所谓的“Dying ReLU”问题。当网络中的某些神经元只输出0时,就会发生这种情况,这意味着它们不再对模型的学习做出贡献。为了应对这种情况,可以使用GELU。
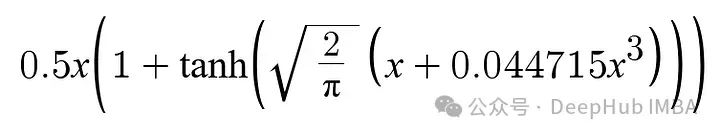
有了这个函数,当输入小于零时,激活函数允许小的负值。
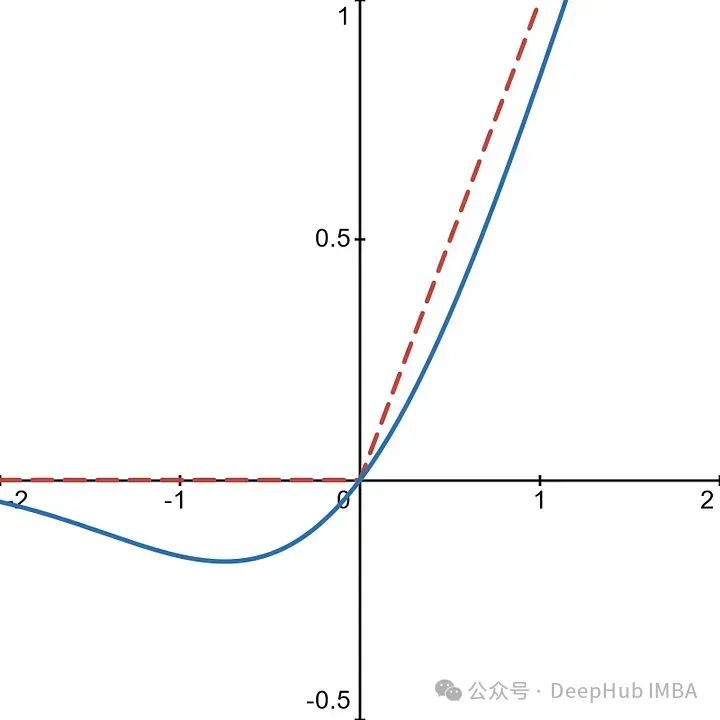
这样神经元就不太可能消亡,因为非零值可以用负输入返回。为反向传播提供了更丰富的梯度,并且我们可以保持模型能力的完整性。
BiTCN完整架构
现在我们了解了BiTCN中临时块的内部工作原理,让我们看看它是如何在模型中组合在一起的。
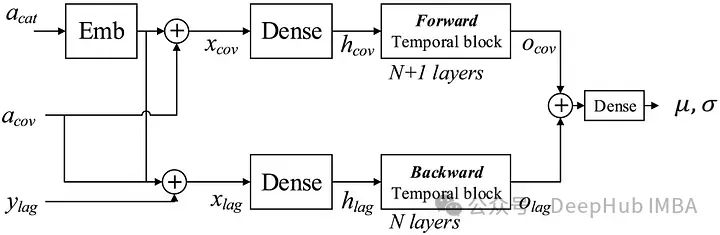
在上图中可以看到滞后值在通过密集层和时间块堆栈之前与所有过去的协变量组合在一起。
我们还看到分类协变量首先被嵌入,然后再与其他协变量组合。这里过去和未来的协变量都组合在一起,如下所示。输出则是来自滞后值和协变量的信息的组合,如下所示。
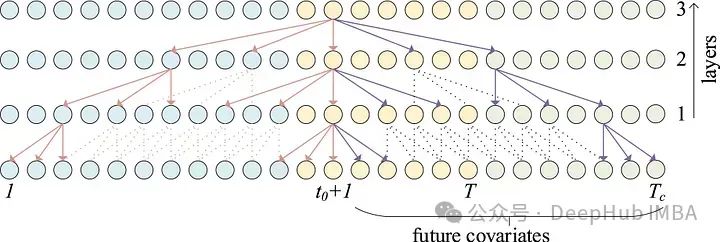
上图额蓝点表示输入序列,黄点表示输出序列,红点表示未来协变量。我们可以看到具有扩展卷积的前瞻性时间块如何通过处理来自未来协变量的信息来帮助告知输出。
最后,BiTCN使用学生t分布来构建预测周围的置信区间。
使用BiTCN进行预测
下面我们将BiTCN与N-HiTS和PatchTST一起应用于长期预测任务。
我们用它来预测一个博客网站的每日浏览量。该数据集包含每日浏览量,以及外生特征,如新文章发表日期的指标,以及美国假期的指标。
我们使用库neuralforecast,因为这是唯一一个提供支持外生特性的BiTCN的即用型实现的库。本文的代码和数据都会在最后提供。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from neuralforecast.core import NeuralForecast
from neuralforecast.models import NHITS, PatchTST, BiTCN
将数据读入DataFrame。
df = pd.read_csv('https://raw.githubusercontent.com/marcopeix/time-series-analysis/master/data/medium_views_published_holidays.csv')
df['ds'] = pd.to_datetime(df['ds'])
可以先看看数据
published_dates = df[df['published'] == 1]
holidays = df[df['is_holiday'] == 1]
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(df['ds'], df['y'])
ax.scatter(published_dates['ds'], published_dates['y'], marker='o', color='red', label='New article')
ax.scatter(holidays['ds'], holidays['y'], marker='x', color='green', label='US holiday')
ax.set_xlabel('Day')
ax.set_ylabel('Total views')
ax.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()

我们可以清楚地看到每周的季节性,工作日的访问量比周末要多。
访问高峰通常伴随着新文章的发布(用红点表示),因为新内容通常会带来更多的流量。最后还可以看到美国的节假日(用绿色十字标记)通常意味着流量较低。
所以我们可以确定,这是一个受外生特征影响明显的数据,它可以成为BiTCN的一个很好的用例。
数据处理
我们将数据分成训练集和测试集。我们保留最后28个条目进行测试。
train = df[:-28]
test = df[-28:]
然后,我们创建一个DataFrame,其中包含预测范围的日期,以及外生变量的未来值。
提供外生变量的未来值是有意义的,因为未来的美国假期日期是提前知道的,并且文章的发布也是可以有计划的。
future_df = test.drop(['y'], axis=1)
建模
我们在这个项目中使用了N-HiTS(基于mlp), BiTCN(基于cnn)和PatchTST(基于transformer)。
N-HiTS和BiTCN都支持外生特征建模,但PatchTST不支持。
这个实验的步长被设置为28,因为这覆盖了我们测试集的整个长度。
horizon = len(test)
models = [
NHITS(
h=horizon,
input_size = 5*horizon,
futr_exog_list=['published', 'is_holiday'],
hist_exog_list=['published', 'is_holiday'],
scaler_type='robust'),
BiTCN(
h=horizon,
input_size=5*horizon,
futr_exog_list=['published', 'is_holiday'],
hist_exog_list=['published', 'is_holiday'],
scaler_type='robust'),
PatchTST(
h=horizon,
input_size=2*horizon,
encoder_layers=3,
hidden_size=128,
linear_hidden_size=128,
patch_len=4,
stride=1,
revin=True,
max_steps=1000
)
]
然后,我们简单地在训练集上拟合我们的模型。
nf = NeuralForecast(models=models, freq='D')
nf.fit(df=train)
使用外生特征的未来值来生成预测。
preds_df = nf.predict(futr_df=future_df)
评估模型
首先将预测值和实际值连接到一个DataFrame中。
test_df = pd.merge(test, preds_df, 'left', 'ds')
根据实际值绘制预测图,结果如下图所示。

在上图中,我们可以看到所有模型似乎都过度预测了实际流量。让用MAE和sMAPE来看看模型的实际对比
from utilsforecast.losses import mae, smape
from utilsforecast.evaluation import evaluate
evaluation = evaluate(
test_df,
metrics=[mae, smape],
models=["NHITS", "BiTCN", "PatchTST"],
target_col="y",
)
evaluation = evaluation.drop(['unique_id'], axis=1)
evaluation = evaluation.set_index('metric')
evaluation.style.highlight_min(color='blue', axis=1)
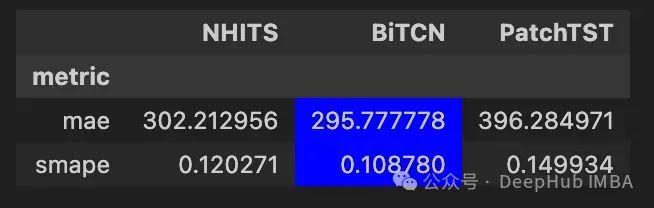
可以看到BiTCN实现了最好的性能,因为该模型的MAE和sMAPE是最低的。
虽然这个实验本身并不是BiTCN的稳健基准,但是可以证明它在具有外生特征的预测环境中取得了最佳结果。
总结
BiTCN模型利用两个时间卷积网络对协变量的过去值和未来值进行编码,以实现有效的多变量时间序列预测。
在我们的小实验中,BiTCN取得了最好的性能,卷积神经网络在时间序列领域的成功应用很有趣,因为大多数模型都是基于mlp或基于transformer的。
BiTCN:Parameter-efficient deep probabilistic forecasting
https://www.sciencedirect.com/science/article/pii/S0169207021001850
最后本文的代码:
https://github.com/marcopeix/time-series-analysis/blob/master/bitcn_blog.ipynb
作者:Marco Peixeiro