
这篇论文提出了一种高稀疏性基础大型语言模型(LLMs)的新方法,通过有效的预训练和部署,实现了模型在保持高准确度的同时,显著提升了处理速度。

论文主要内容
- 稀疏预训练(Sparse Pretraining):作者提出了一种新的稀疏预训练方法,该方法可以在高达70%的稀疏度下实现准确度的完全恢复。这种方法结合了SparseGPT一次性剪枝方法和在SlimPajama和The Stack数据集子集上对模型进行稀疏预训练。这种组合使得模型在精细调整后达到了比当前最先进技术更高的恢复水平,特别是在对话、代码生成和指令执行等复杂任务上。
- 实用加速(Practical Speedups):在训练和推理阶段,展示了稀疏模型带来的加速效果。使用Cerebras CS-3 AI加速器进行稀疏训练显示出接近理想的加速比,同时通过Neural Magic的DeepSparse引擎和nm-vllm引擎在CPU和GPU上部署,实现了高达3倍和1.7倍的推理加速。
- 量化复合增益(Compounding Gains with Quantization):展示了如何通过进一步量化稀疏基础模型来维持准确度,从而实现性能的复合增益。例如,通过量化和稀疏化,模型在CPU上的速度提升了多达8.6倍。
- 对比以往工作:与传统的在微调过程中剪枝的方法相比,这篇论文的方法在高稀疏度下保持高准确率上表现得更好,特别是在需要广泛知识的复杂任务中。
这项工作不仅提高了模型的运行效率,也通过开源代码和模型,推动了研究的可复现性和进一步的扩展。这为快速创建更小、更快且不牺牲准确性的大型语言模型铺平了道路。
指标评价
论文中关于性能提升的量化数据包括准确率、训练和推理速度提升等,具体包括:
准确率恢复:
- 在高达70%的稀疏度下,通过结合SparseGPT剪枝方法和稀疏预训练,实现了完全的准确率恢复,这在复杂任务(如对话、代码生成和指令执行)中特别有效。与传统的在微调过程中进行剪枝相比,该方法在高稀疏度下保持较高的准确率更加有效。
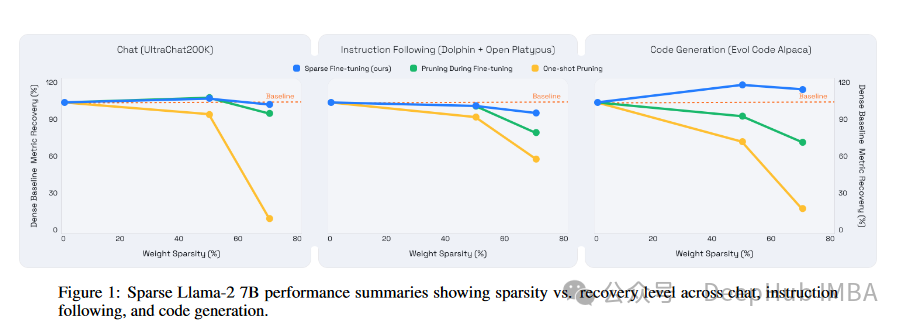
训练和推理速度提升:
- 使用Cerebras CS-3 AI加速器进行稀疏训练,实现了接近理论的加速比。
- 在CPU上使用Neural Magic的DeepSparse引擎,实现了高达3倍的推理加速。
- 在GPU上通过Neural Magic的nm-vllm引擎,实现了1.7倍的推理加速。
- 通过使用稀疏化和量化的方法,模型在CPU上的处理速度提升了最多8.6倍。
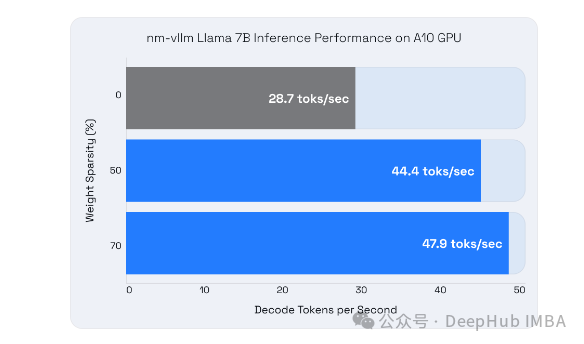
与以前研究的比较:
- 相比于之前的研究,该论文中的方法在保持模型准确率的同时,能够实现更高级别的稀疏度和更快的处理速度。以往的研究中,高稀疏度往往与准确率损失相关联,或者在处理复杂任务时难以维持高准确率。
- 本研究中的稀疏预训练和精细调整的结合,特别是在复杂的大背景任务上,显示了优于传统方法的准确率恢复能力,这表明作者提出的方法能够有效克服以往技术的限制。
这些改进不仅表明了稀疏模型在保持高准确率的同时,还能大幅度提升运算效率,这对于需要在资源受限环境中部署大型语言模型的实际应用非常重要。
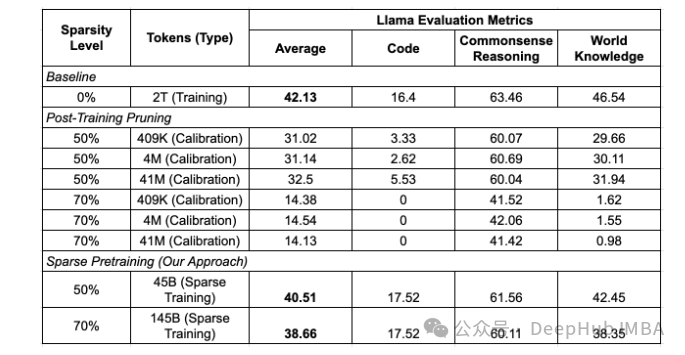
主要论点
1、将SparseGPT剪枝与稀疏预训练相结合

相比于传统剪枝方法,具有以下主要优势:
更高的准确率恢复:结合SparseGPT剪枝与稀疏预训练的方法能够在高达70%的稀疏度下实现完全的准确率恢复。这种方法尤其适用于处理复杂的任务,如对话、代码生成和指令执行,其中传统的剪枝方法往往难以保持高准确率。
更有效的模型压缩:通过预训练的稀疏模型,可以在不牺牲性能的前提下,实现更高程度的模型压缩。这种方法不仅减少了模型的存储需求,还降低了推理阶段的计算需求。
简化的超参数调整:稀疏预训练为模型提供了一个更健壮的基础,通常可以减少在剪枝微调过程中所需的广泛超参数调整。这简化了模型开发过程,减少了模型优化所需的时间和资源。
减少的计算需求:使用预训练的稀疏模型可以在单次微调运行中达到收敛,与传统的“在微调过程中进行剪枝”的路径相比,这种方法通常涉及将一个密集模型收敛,然后进行剪枝和额外的微调,因此可以显著减少计算需求。
广泛的任务适用性:由于高稀疏度下的准确率保持,这种结合方法使得模型可以广泛应用于各种NLP任务,包括那些对模型精度要求较高的场景。
将SparseGPT剪枝与稀疏预训练相结合,不仅提高了模型在复杂任务中的表现,还通过减少所需的计算资源和简化模型优化过程,为大型语言模型的高效部署提供了新的可能性。
2、Cerebras CS-3 AI加速器提高了稀疏预训练的效率
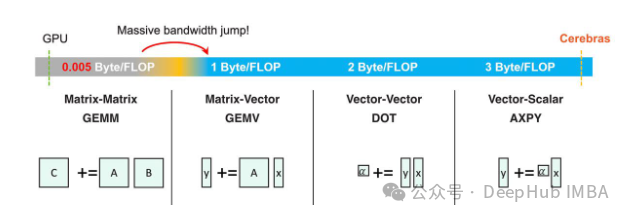
原生支持非结构化稀疏性:Cerebras CS-3 设计时就考虑到了非结构化稀疏性的需求。这意味着它能够有效处理大量的稀疏数据,无需将它们转化为密集格式,从而避免了额外的计算和内存消耗。
高带宽内存架构:CS-3 利用其独特的片上内存架构,提供了高内存带宽。这对于执行稀疏矩阵乘法(Sparse GEMM)这类内存密集型操作尤其重要,因为这些操作在稀疏训练中非常常见。高内存带宽确保数据可以快速地在处理单元之间移动,减少了延迟和瓶颈。
细粒度数据流执行:CS-3 的数据流执行模式能够有效利用数据稀疏性。在这种模式下,只有非零数据触发计算,从而减少了不必要的计算步骤。这种方法不仅节省了功耗,还提高了性能,因为处理器可以跳过那些不会对结果产生影响的零值计算。
与PyTorch的无缝集成:Cerebras CS-3 能够与流行的机器学习框架如PyTorch无缝集成,使开发者可以轻松利用其硬件优势而无需对现有代码进行大量修改。这降低了技术门槛,加速了从原型到生产的过程。
理论性能与实际性能接近:在论文中提供的实验中,Cerebras CS-3 的实际性能与理论性能非常接近,表明其硬件设计和执行模型高度优化,能够实现预期的稀疏操作加速。
通过这些特性,Cerebras CS-3 AI加速器显著提高了稀疏预训练的效率,使其在处理大型稀疏语言模型时更为高效和可行。这对于需要处理大量数据和复杂模型的现代NLP任务来说是一大优势。
3、稀疏度和提高CPU上的推理性能

高稀疏度意味着模型中有70%的权重被设为零,这大幅减少了模型的存储和运行时内存需求,使得模型更适合部署在资源受限的设备上,如移动设备和嵌入式系统。由于计算需求减少,可以更快地完成推理任务,这对实时处理和响应需求高的应用场景(如语音识别和在线翻译服务)非常关键。
位掩码扩展技术通过存储非零值及其对应的位掩码来优化内存使用。这种方法减少了内存占用,因为只存储有用的信息(非零值),并通过掩码指示这些值在矩阵中的位置。在CPU上执行推理时,位掩码可以快速扩展成完整的数据结构,使得计算单元(如SIMD指令)可以高效地处理数据。这一点特别适用于现代CPU架构,它们支持并行处理多个数据点。
总结
通过有效的预训练和部署,在高达70%的稀疏度下实现了准确率的完全恢复。这一方法结合了SparseGPT剪枝与稀疏预训练,特别适用于处理复杂的任务,如对话、代码生成和指令执行。相较于传统的剪枝方法,这种结合方法在保持高准确率的同时,还能大幅提升模型的处理速度和效率。
Cerebras CS-3 AI加速器在此过程中扮演了关键角色,它通过原生支持非结构化稀疏性和高带宽内存架构,大幅提高了稀疏预训练的效率。此外,通过位掩码扩展技术,这种方法还优化了CPU上的稀疏推理性能,利用SIMD指令集加快了数据处理速度,显著提高了推理效率。
这些技术的应用使得模型在维持高性能的同时,显著减少了计算需求和能耗,提高了部署的灵活性和经济性,为资源受限设备提供了实用的解决方案。这不仅推动了大型语言模型的技术进步,也为其在实际应用中的广泛部署开辟了新的可能性。
论文同时还提供了代码和已经训练好的模型,还有部署文档
https://arxiv.org/abs/2405.03594