
这是4月发表的论文《Better & Faster Large Language Models via Multi-token Prediction》,作者们提出了一种创新的多词元预测方法,该方法在提高大型语言模型(LLMs)的样本效率和推理速度方面展示了显著优势。本文将对该论文进行详细的推荐和分析,探讨其理论贡献、实验设计以及对未来研究的启示。

理论贡献和技术创新
这篇论文的主要创新点在于提出了一种新的多词元预测框架,用于训练大型语言模型(LLMs),并通过一系列实验验证了其有效性
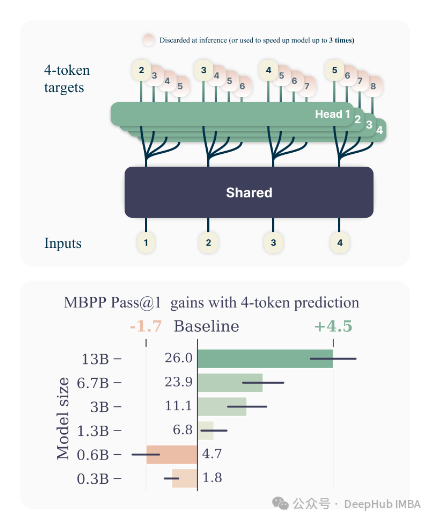
- 多词元预测架构:与传统的单词元预测模型相比,该研究提出的多词元预测方法要求模型在训练过程中一次预测接下来的多个词元,而非仅预测下一个词元。这种方法通过在共享模型主干上增加多个独立的输出头来实现,并且没有增加训练时间和内存消耗。
- 改善样本效率和推理速度:研究表明,多词元预测方法不仅提高了模型处理自然语言和编程语言任务的能力,还显著加快了模型的推理速度。特别是在编程相关的生成任务中,多词元模型相较于传统模型表现出更高的问题解决能力和更快的执行效率。
- 实验验证:论文中进行了大规模的实验验证,使用不同参数规模的模型(高达13B参数)和多种数据集。实验结果显示,多词元预测方法在多个编程和自然语言处理基准上优于现有的单词元预测模型。
- 自我推测解码:为了提高推理速度,研究引入了自我推测解码技术,允许在解码过程中并行处理多个输出头,从而进一步提高解码效率。
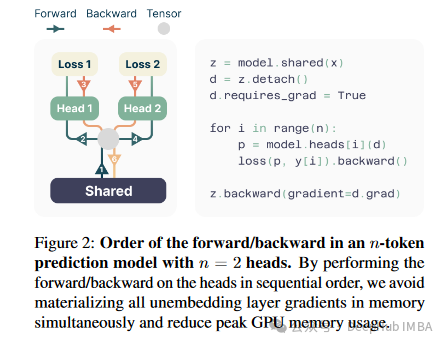
这些创新不仅提高了模型的性能和效率,也为未来的语言模型训练方法提供了新的研究方向。与以往工作相比,这种多词元预测方法在提高模型学习效率和加速模型推理方面展现了明显的优势。
实验设计与评估
论文中提到了多个关于性能提升的量化数据,主要包括模型在不同任务上的表现提升、推理速度的加快等。
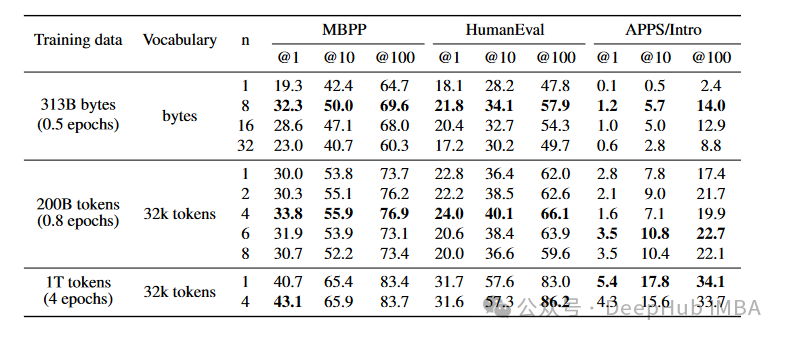
- 问题解决能力提升:- 在编程任务HumanEval上,使用13B参数的多词元预测模型解决的问题数量比传统单词元预测模型多12%。- 在MBPP任务上,提升了17%。
- 推理速度提升:- 使用多词元预测训练的模型在推理时速度提高了最多3倍,尤其是在使用大批量大小时。
- 编码任务上的性能提升:- 多词元预测方法在MBPP代码任务中的pass@1表现随着模型规模的增加而显著提升,尤其是在较大的模型中更为明显。
- 推理效率:- 在实际数据上,通过自我推测解码,最佳的4词元预测模型在代码完成提示上的推理速度提高了3.0倍,平均从3个建议中接受2.5个。
这些数据显示,多词元预测不仅提高了模型在特定任务上的性能,而且显著加快了推理速度。与之前的研究相比,这种新方法在处理自然语言和编程语言的生成任务中表现出了更高的效率和效果,这主要得益于其能够同时预测多个未来词元的能力,这在传统单词元预测模型中是不可能实现的。这不仅改善了样本效率,还通过减少必须执行的推理步骤数量来加速了模型的推理过程。
讨论与未来方向
作者提到了多词元预测方法的多项优势,包括提高样本效率和加快推理速度等。他们也指出了该方法的局限性,例如在较小模型中的性能提升不如在大模型中显著。推理过程中多输出头的管理和优化可能增加系统的复杂性。
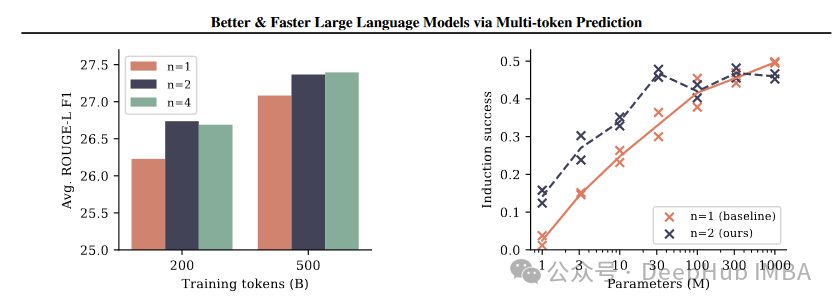
- 优势:- 提高样本效率和推理速度:作者强调,多词元预测方法通过同时预测未来的多个词元,相较于传统的单词元预测,显著提高了模型的样本效率和推理速度。- 在大规模模型中表现更佳:实验结果显示,这种方法在较大的模型(如13B参数)中特别有效,能够更好地利用大模型的能力,解决更多的问题。
- 局限性:- 小模型中的性能不佳:多词元预测方法在较小的模型中效果不如大模型明显,这表明该方法对模型规模有一定的依赖性。- 推理复杂性:虽然推理速度提高,但多输出头的管理和优化在实际应用中可能增加系统的复杂性。
- 改进空间:- 自动选择最优的n值:目前的方法需要手动选择预测未来词元的数量(n),未来的工作可能会探索自动选择最优n值的方法。- 优化词汇大小和计算成本:作者提出,多词元预测的最优词汇大小可能与单词元预测不同,调整这一点可能会进一步提高效率和性能。
- 与先前研究的对比:- 效率和性能的提升:与先前的单词元预测方法相比,多词元预测在效率和性能上都有明显提升,特别是在大规模模型和编程语言任务上的应用。- 新的推理技术:通过利用多词元预测,作者引入了自我推测解码等新技术,这在先前的研究中较少见,为未来的研究提供了新的方向。
总体而言,作者对本研究的自我评估清晰地指出了其方法的创新点和优势,同时也诚实地讨论了存在的局限性和未来的改进方向,这种全面的讨论有助于推动该领域的进一步研究和发展。
总结
《Better & Faster Large Language Models via Multi-token Prediction》这篇论文为大型语言模型的训练方法带来了革命性的改进。通过多词元预测,不仅显著提高了模型的推理速度和性能,还扩展了模型在实际应用中的可能性。
论文地址:
https://arxiv.org/abs/2404.19737
最后说明:为了统一概念,以后我们会将Token统一翻译成 “词元”。我认为这样会比翻译成“令牌”更加贴切,因为令牌这个词在不同系统中的含义会有所区别,所以针对于NLP,“词元”更加贴切。