
构建无与伦比的深度学习环境:在CentOS上实现GPU资源管理容器的终极指南
大家好 我是寸铁👊
构建无与伦比的深度学习环境:在CentOS上实现GPU资源管理容器的终极指南✨
喜欢的小伙伴可以点点关注 💝
前言
这篇博文将深入探讨在
CentOS操作系统上创建高度优化的深度学习环境的完整过程。我们将从零开始,逐步指导读者完成配置,并重点介绍如何有效地管理
GPU资源,以及如何运用容器技术来提高环境的灵活性和可维护性。
本文旨在为初学者提供一站式的解决方案,无论你是否有经验,都能够轻松地搭建出功能强大、高效稳定的深度学习环境。
Nvidia驱动安装
由于需要跑深度学习程序,需要用到
GPU也就是显卡,所以需要安装
Nvidia驱动来进行操作。
又需要部署到容器上跑,所以需要安装nvidia-docker指定具体的
GPU跑程序。
安装驱动
- 先下载
ELRepo仓库的GPG密钥
rpm--import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
- 再安装
ELRepo仓库
rpm-Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
- 在
ELRepo仓库中安装nvidia软件包
yum install kmod-nvidia
这个命令使用yum包管理器从ELRepo仓库中安装kmod-nvidia软件包,这个软件包通常是NVIDIA显卡的内核模块驱动程序。安装这个软件包可以让系统支持NVIDIA显卡,并提供相应的驱动程序支持。
- 再进行重启
reboot
检测安装情况
- 显示显卡的基本情况
ls-la /dev |grep nvidia

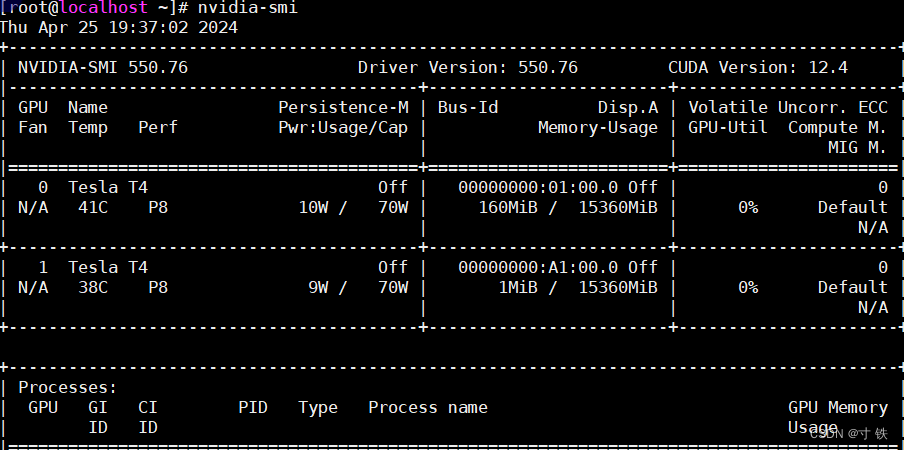
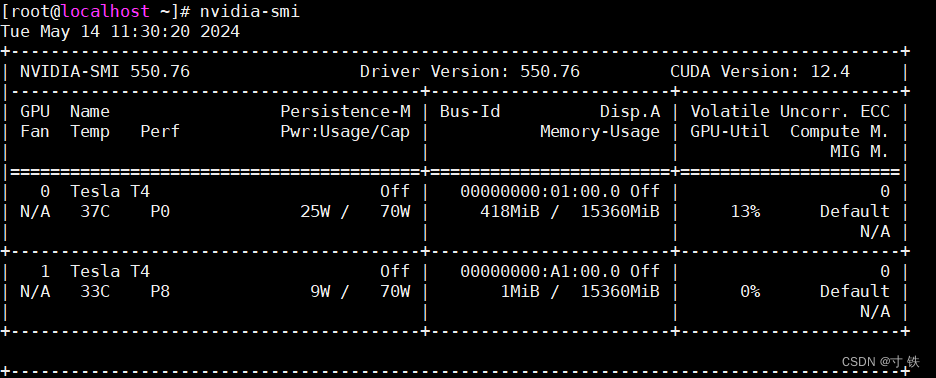
- 显示GPU的使用情况和性能信息
nvidia-smi
Nvidia-docker安装
安装步骤
- 如果您还没有安装 Docker,可以使用以下命令在
CentOS上安装 Docker:
sudo yum installdocker
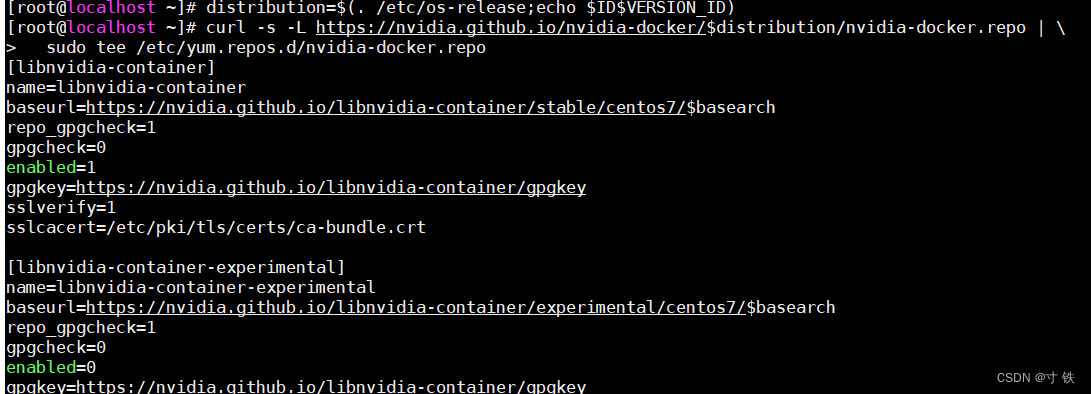
- 启用 NVIDIA 容器运行时仓库:运行以下命令以添加 NVIDIA 的仓库
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)curl-s-L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo |\sudotee /etc/yum.repos.d/nvidia-docker.repo
运行结果如下:
- 安装
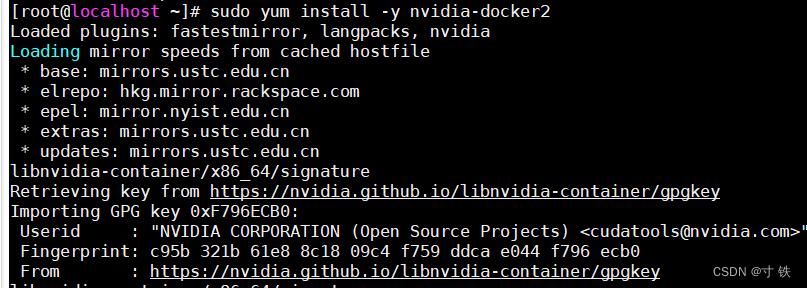
nvidia-docker2:运行以下命令来安装nvidia-docker2:
sudo yum install-y nvidia-docker2
运行结果如下:
- 重启 Docker 服务:以使更改生效
sudo systemctl restart docker
运行结果如下:

验证安装
(1) 先拉取
nvidia
的镜像
docker pull nvidia/cuda:11.4.3-base-centos7
更多的镜像如下网址:
https://hub.docker.com/r/nvidia/cuda/tags?page=7&page_size=&name=&ordering=
(2) 再验证
nvidia-docker2
是否正确安装:
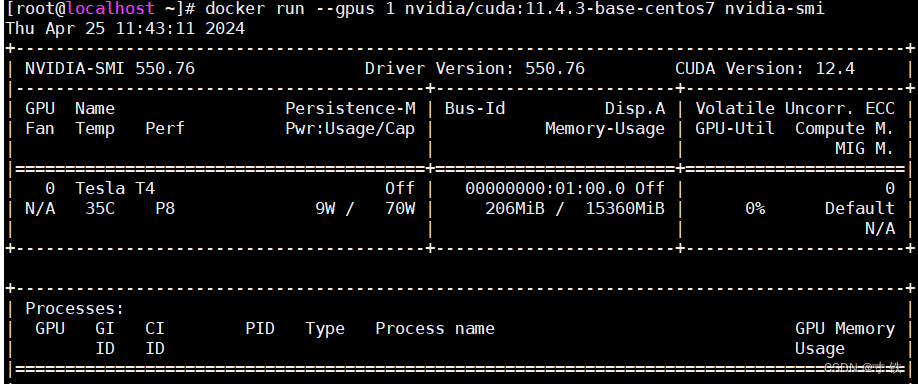
docker run --gpus1 nvidia/cuda:11.4.3-base-centos7 nvidia-smi
这个命令的意思是在一个Docker容器中运行nvidia-smi命令,并且指定使用1个GPU。
具体如下:
docker run
: 运行Docker容器的命令。
--gpus 1
: 指定使用
1个GPU
。这个参数告诉Docker要将一个
GPU分配给容器
。
nvidia/cuda:11.4.3-base-centos7
: 这是要运行的Docker镜像的名称和标签。这个镜像是NVIDIA提供的一个包含
CUDA
工具和运行时的基本镜像,基于
CentOS 7
操作系统。
nvidia-smi
: 在NVIDIA GPU上查看GPU状态和相关信息的命令。在这个命令中,它将在Docker容器内运行。
运行结果如下:
说明安装成功!
GPU命令
查看显卡情况
ls-la /dev |grep nvidia

使用GPU
# 使用所有GPUdocker run --gpus all nvidia/cuda:11.4.3-base-centos7 nvidia-smi
# 使用两个GPUdocker run --gpus2 nvidia/cuda:11.4.3-base-centos7 nvidia-smi
# 指定GPU运行docker run --gpus'"device=0"' nvidia/cuda:11.4.3-base-centos7 nvidia-smi
docker run --gpus'"device=0,1"' nvidia/cuda:11.4.3-base-centos7 nvidia-smi
docker run --gpus'"device=UUID-ABCDEF,1"' nvidia/cuda:11.4.3-base-centos7 nvidia-smi
其中
11.4.3-base-centos7替换为你操作系统对应的镜像,如
CentOs、
Ubantu等等安装的各种版本的镜像,根据安装的镜像进行替换即可。镜像也可以是自己其他打包好的镜像源。
测试GPU运行情况
- 编写
docker File文件 - 使用打包好的
docker File镜像进行测试 - 在容器中分配GPU运行
具体如下:
- 指定第一个
GPU运行深度学习的pytorch程序
docker run -it--rm--gpus'"device=0"'--entrypoint /bin/bash gcn_tsa_image

-it:允许与容器的标准输入进行交互,并分配一个伪终端。
--rm:容器退出后自动删除。
'"device=0"'指定具体是哪个
GPU来跑程序,这里指定显卡
0来跑
'"device=0,1"'指定具体多个
GPU来跑程序,这里指定显卡
0、1来跑
--gpus all:指定容器可以访问所有可用的 GPU 设备。您还可以使用 --gpus device=<GPU_ID> 来指定特定的 GPU 设备。
--entrypoint /bin/bash:设置容器的入口点为 /bin/bash,这样当容器启动时会直接进入交互式的 bash shell。
- 查看是否真正运用到显卡
nvidia-smi
确实是使用到显卡来跑
Pytorch
程序了~
看到这里的小伙伴,恭喜你又掌握了一个技能👊
希望大家能取得胜利,坚持就是胜利💪
我是寸铁!我们下期再见💕
往期好文💕
保姆级教程
【保姆级教程】Windows11下go-zero的etcd安装与初步使用
【保姆级教程】Windows11安装go-zero代码生成工具goctl、protoc、go-zero
【Go-Zero】手把手带你在goland中创建api文件并设置高亮
报错解决
【Go-Zero】Error: user.api 27:9 syntax error: expected ‘:‘ | ‘IDENT‘ | ‘INT‘, got ‘(‘ 报错解决方案及api路由注意事项
【Go-Zero】Error: only one service expected goctl一键转换生成rpc服务错误解决方案
【Go-Zero】【error】 failed to initialize database, got error Error 1045 (28000):报错解决方案
【Go-Zero】Error 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)报错解决方案
【Go-Zero】type mismatch for field “Auth.AccessSecret“, expect “string“, actual “number“报错解决方案
【Go-Zero】Error: user.api 30:2 syntax error: expected ‘)‘ | ‘KEY‘, got ‘IDENT‘报错解决方案
【Go-Zero】Windows启动rpc服务报错panic:context deadline exceeded解决方案
Go面试向
【Go面试向】defer与time.sleep初探
【Go面试向】defer与return的执行顺序初探
【Go面试向】Go程序的执行顺序
【Go面试向】rune和byte类型的认识与使用
【Go面试向】实现map稳定的有序遍历的方式
版权归原作者 寸 铁 所有, 如有侵权,请联系我们删除。