
之前写过两篇YOLOv5+各种注意力机制的文章,收到了大家很多的反馈,这篇博文就简单针对这些问题讨论一下:
- 为什么我添加了注意力模块以后精度反而下降了?
- 在什么位置添加注意力模块比较好?
- 同一种或者不同的注意力模块可以添加多个吗?
- 我的数据集应该使用那种注意力模块?
- 添加注意力模块以后还能用权重吗?
- 个别注意力模块的参数如何设置?
首先说一下我本人在刚接触注意力时也搞不懂为什么精度不升反降,明明人家论文里都证实了显著涨点的,到我这咋就不行了呢?
所以我做了大量的实验,数据集也用了好几个,我尝试了很多种加法,拿YOLOv5s举例,我刚开始尝试在SPPF上一层添加单层的注意力,但是实验结果几乎都不尽如人意,随后我尝试了在主干的4个C3模块后都添加注意力,很多都取得了很好的效果(大多数都是精确度上升,召回率下降,mAP下降),然后我又尝试在C3模块里融合注意力模块,有的也取得了很好的效果,还有在Neck部分加等等加法。
一个模型精度是否提高会受到很多因素影响,需要考虑的因素包括模型的参数量、训练策略、用到的超参数、网络架构设计、硬件以及软件使用、pytorch版本等等
虽然大家都认为神经网络是一个黑盒子,但是我觉得有些地方还是可以用理论知识解释一下的,在看了很多大佬文章后发现,他们主要是从两个方面解释这个问题:
一、从模型是否过拟合或欠拟合角度
大部分注意力模块是有参数的,添加注意力模块会导致模型的复杂度增加。
- 如果添加attention前模型处于欠拟合状态,那么增加参数是有利于模型学习的,性能会提高。
- 如果添加attention前模型处于过拟合状态,那么增加参数可能加剧过拟合问题,性能可能保持不变或者下降。
知乎大佬pprp
就为了验证以上猜想做个实验,他使用cifar10数据集中10%的数据进行验证,模型方面选择的是wideresnet,该模型可以通过调整模型的宽度来灵活调整模型的容量。
Norm系列表示没有使用注意力,nd代表宽度CBAM系列表示在ResBlock中使用了注意力norm_8dcbam_8dnorm_32dcbam_32dnorm_64dcbam_64d
具体来说,从上到下模型容量越来越高,下图展示了各个模型在训练集和验证集上的收敛结果。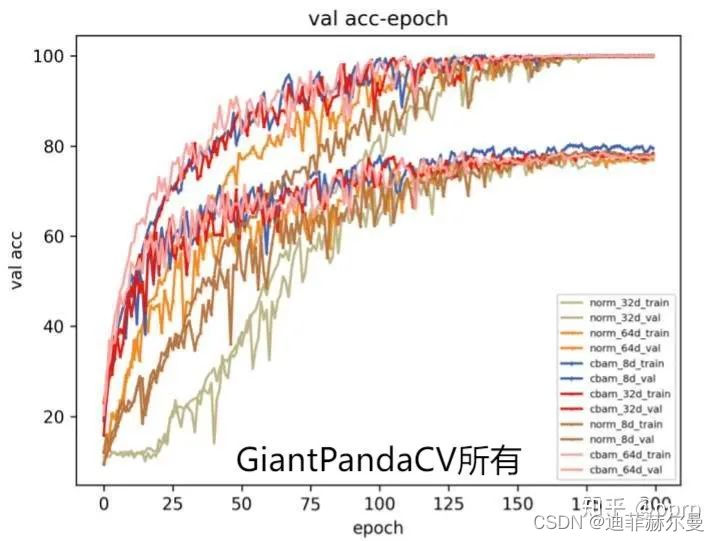
可以发现一下几个现象:
- 随着宽度增加,模型过拟合现象会加剧,具体来说是验证集准确率变低。
- cbam与norm进行比较可以发现,在8d(可能还处于欠拟合)基础上使用cbam可以取得验证集目前最高的结果,而在64d(可能出现过拟合)基础上使用cbam后准确率几乎持平。
- 还有一个有趣的现象,就是收敛速度方面,大体符合越宽的模型,收敛速度越快的趋势(和我们已知结论是相符的,宽的模型loss landscape更加平滑,更容易收敛)
“以上是第一个角度,另外一个角度可能没那么准确,仅提供一种直觉”
二、从模型模型感受野来角度
这点我和
知乎大佬pprp
的看法有点不同,我先放上他的看法
我们知道CNN是一个局部性很强的模型,通常使用的是3x3卷积进行扫描整张图片,一层层抽取信息。而感受野叠加也是通过多层叠加的方式构建,比如两个3x3卷积的理论感受野就是5x5, 但是其实际感受野并没有那么大。
各种注意力模块的作用是什么呢?他们能够弥补cnn局部性过强,全局性不足的问题,从而获取全局的上下文信息,为什么上下文信息重要呢?可以看一张图来自CoConv。

单纯看图a可能完全不知道该目标是什么,但是有了图b的时候,知道这是厨房以后,就可以识别出该目标是厨房用手套。因此注意力模块具有让模型看的更广的能力,近期vision transformer的出现和注意力也有一定关联,比如Non Local Block模块就与ViT中的self-attention非常类似。vision transformer在小数据集上性能不好的也可以从这个角度解释,因为太关注于全局性(并且参数量比较大),非常容易过拟合,其记忆数据集的能力也非常强,所以只有大规模数据集预训练下才能取得更好的成绩。(感谢李沐老师出的系列视频!)再回到这个问题,注意力模块对感受野的影响,直观上来讲是会增加模型的感受野大小。理论上最好的情况应该是模型的实际感受野(不是理论感受野)和目标的尺寸大小相符。
- 如果添加注意力模块之前,模型的感受野已经足够拟合数据集中目标,那么如果再添加注意力模块有些画蛇添足。但是由于实际感受野是会变化的,所以可能即便加了注意力模块也可以自调节实际感受野在目标大小附近,这样模型可能保持性能不变。
- 如果添加注意力模块之前,模型的感受野是不足的,甚至理论感受野都达不到目标的大小(实际感受野大小<理论感受野大小),那么这个时候添加注意力模块就可以起到非常好的作用,性能可能会有一定幅度提升。
从这个角度来分析,题主只用了两个卷积层,然后就开始使用CBAM模块,很有可能是感受野不足的情况。但是为什么性能会下降呢,可能有其他方面因素影响,可以考虑先构建一个差不多的baseline,比如带残差的ResNet20,或者更小的网络,然后再在其基础上进行添加注意力模块。以上结论并不严谨,欢迎评论探讨。
以下是我的个人看法,并不严谨🙈,大家理性看待
我觉得注意力机制的原理不就是为了合理利用有限的视觉信息处理资源嘛,那肯定是需要选择视觉区域中的特定的那部分,然后集中关注它,这样的话不也就导致了模型仅关注他认为重要的那部分,从而忽略了其它部分信息。(换句话说也就是注意力太“强”了)
因为我在实验中发现,注意力机制几乎都会带来精确度的上升和召回率的下降,我觉得这种现象可以一定程度上解释我的想法。
当然这是我个人推测的结果,没有经过证实,大家理性的看待,如果有其它想法欢迎大家评论区讨论。
看过这篇文章,大家对这些问题应该都有了一定的了解了,下面我再简单回答一下
- 在什么位置添加注意力模块比较好?
我觉得没有说加在哪里一定好的,还是要实验多尝试,我会在我的Github里更新一些注意力的加法的配置文件,大家可以参考一下,没准哪种加法就在你的数据集上涨点了呢
- 同一种或者不同的注意力模块可以添加多个吗?
可以,几个互补的注意力模块会带来更好的效果的,同一种注意力的不同数量效果也是不一样的
- 我的数据集应该使用那种注意力模块?
实验出真知吧
- 添加注意力模块以后还能用权重吗?
能!YOLOv5会自动匹配一部分能用的,别管怎么改,权重路径那写上就行了,用上一点也比不用强
- 个别注意力模块的参数如何设置?
这个我也不太好说,多实验吧
最后感谢大家支持,觉得我哪里说的不对的欢迎大家指正👍
欢迎大家关注我改进YOLOv5的Github项目:https://github.com/1579093407/Yolov5_Magic
版权归原作者 迪菲赫尔曼 所有, 如有侵权,请联系我们删除。