使用YOLOv5实现人脸口罩佩戴检测(详细)
获取人脸口罩的数据集有两种方式:第一种就是使用网络上现有的数据集labelImg 使用教程 图像标定工具注意!
【语义分割】1、语义分割超详细介绍
图像分割是机器视觉任务的一个重要基础任务,在图像分析、自动驾驶、视频监控等方面都有很重要的作用。图像分割可以被看出一个分类任务,需要给每个像素进行分类,所以就比图像分类任务更加复杂。此处主要介绍 DL-based 方法。encoder:输入图像→resize到特定大小→输入 backbone→得到特
【CV】第 3 章:使用 PyTorch 构建深度神经网络
在上一章中,我们学习了如何使用 PyTorch 编写神经网络。我们还了解了神经网络中存在的各种超参数,例如批量大小、学习率和损失优化器。在本章中,我们将学习如何使用神经网络进行图像分类。本质上,我们将学习如何表示图像并调整神经网络的超参数以了解它们的影响。为了不引入太多的复杂性和混乱,我们在上一章只
BraTS2021脑肿瘤分割实战
脑肿瘤分割是MICCAI所有比赛中历史最悠久的,到2021年已经连续举办了10年,参赛人数众多,是学习医学图像分割最前沿的平台之一。简介: 胶质母细胞瘤和具有胶质母细胞瘤分子特征的弥漫性星形细胞胶质瘤(WHO 4 级星形细胞瘤)是成人中枢神经系统最常见和最具侵袭性的恶性原发性肿瘤,在外观、形状和组
OpenCV-眼睛控制鼠标
另外,如果在整个数据收集过程中,你们在屏幕的特定区域(例如边缘)都没有拍摄任何图像,则该模型不太可能在该区域内进行预测。在此项目中,每次单击鼠标时,我们都会编写代码来裁剪你们的眼睛图像。使用这些数据,我们可以反向训练模型,从你们您的眼睛预测鼠标的位置。但是,作为概念证明,你们会注意到,实际上只有20
MMPose姿态估计+人体关键点识别效果演示
MMPose开源姿态估计算法库,进行了人体关键点的效果演示。(包括肢体,手部和全身的关键点,还尝试了MMPose实时效果)
人工智能——大白话熟悉目标检测基本流程
一篇关于快速熟悉目标检测流程的博客,如果你还不太明白目标检测是如何检测的,更不清楚整个流程,那希望你花几分钟读一下这篇入门级博客,我用自己的理解简化目标检测流程方便大家快速了解什么是目标检测
OpenCV人脸识别,训练模型为cv2.face.LBPHFaceRecognizer_create()
OpenCV内部自带有三种人脸检测方式LBPH人脸识和其他两种方法(Eigen人脸识别,FisherFace人脸识别)本次主要说明第一种方式LBPH检测。
coco数据集解析及读取方法
RLE所占字节的大小和边界上的像素数量是正相关的。其中size是这幅图片的宽高,然后在这幅图像中,每一个像素点要么在被分割(标注)的目标区域中,要么在背景中。每个对象(不管是iscrowd=0还是iscrowd=1)都会有一个矩形框bbox ,矩形框左上角的坐标和矩形框的长宽会以数组的形式提供,数组
【多目标跟踪与计数】(三)DeepSORT实战车辆和行人跟踪计数
一、DeepSort介绍论文地址:https://arxiv.org/pdf/1703.07402.pdf参考文章:DeepSort讲解代码地址:https://github.com/mikel-brostrom/Yolov5_DeepSort_OSNet(可参考这个源代码,如果需要我这边的源代码可

Stable Diffusion的入门介绍和使用教程
Stable Diffusion是一个文本到图像的潜在扩散模型,本文将介绍如何使用Stable Diffusion以及它具体工作的原理
学习Transformer:自注意力与多头自注意力的原理及实现
自从Transformer[3]模型在NLP领域问世后,基于Transformer的深度学习模型性能逐渐在NLP和CV领域(Vision Transformer)取得了令人惊叹的提升。本文的主要目的是介绍经典Transformer模型和Vision Transformer的技术细节及基本原理,以方便
YOLO V5源码详解
首先读取图片以及标签路径,并将标签存入缓存,对单标签情况、特定类别、以及是否保持长方形等情况分别进行处理。如果需要进行mosaic 数据增强,首先找到中心点,将图片分别放置于四个位置,进行裁剪或者拼接以适应,并对labels进行调整。同时,对进行过mosaic数据增强过的图像,再进行copy_pas
Vision Transformer 论文 + 详解( ViT )
Vision Transformer 论文 + 详解
超详细!手把手带你轻松用 MMSegmentation 跑语义分割数据集
本文主要讲解了数据集相关的内容,包括目前学术界主流的语义分割数据集在 MMSegmentation中的实现,以及如何用 MMSegmentation 跑自己的数据集。希望可以帮助大家快速上手使用 MMSegmentation 代码库进行实验。.........
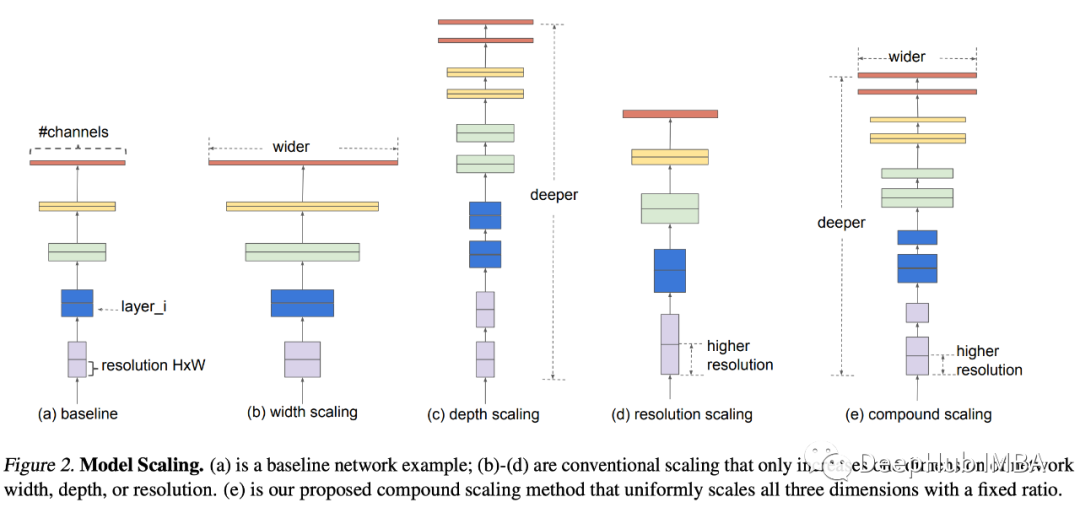
经典CNN设计演变的关键总结:从VGGNet到EfficientNet
卷积神经网络设计史上的主要里程碑:模块化、多路径、因式分解、压缩、可扩展
GANs系列:DCGAN原理简介与基础GAN的区别对比
参考了DCGAN论文,对论文逐步解读,将论文精华部分进行了概括提取,包括原理、应用以及训练过程。在基础的生成式对抗神经网络的基础上,进一步介绍DCGAN深度卷积生成对抗神经网络。
图像风格迁移
风格迁移指的是两个不同域中图像的转换,具体来说就是提供一张风格图像,将任意一张图像转化为这个风格,并尽可能保留原图像的内容
世界坐标系、相机坐标系、图像坐标系、像素坐标系
四个坐标系都是什么?图像处理、立体视觉等等方向常常涉及到四个坐标系:世界坐标系、相机坐标系、图像坐标系、像素坐标系 构建世界坐标系只是为了更好的描述相机的位置在哪里,在双目视觉中一般将世界坐标系原点定在左相机或者右相机或者二者X轴方向的中点。接下来的重点,就是关于这几个坐标系的转换。
Faster-RCNN详解(个人理解)
这是我在学习Faster-RCNN的原理时做的学习总结,个人感觉还是比较详细的。



