
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在上一章中,我们学习了如何使用 PyTorch 编写神经网络。我们还了解了神经网络中存在的各种超参数,例如批量大小、学习率和损失优化器。在本章中,我们将学习如何使用神经网络进行图像分类。本质上,我们将学习如何表示图像并调整神经网络的超参数以了解它们的影响。
为了不引入太多的复杂性和混乱,我们在上一章只介绍了神经网络的基本方面。但是,我们在训练网络时会调整更多输入。通常,这些输入被称为超参数。与神经网络中的参数(在训练期间学习)相比,这些输入是由构建网络的人提供的超参数。更改每个超参数的不同方面可能会影响训练神经网络的准确性或速度。此外,一些额外的技术,如缩放、批量归一化和正则化有助于提高神经网络的性能。我们将在本章中学习这些概念。
然而,在我们开始之前,我们将了解图像是如何表示的——只有这样我们才能深入研究超参数的细节。在了解超参数的影响时,我们会将自己限制在一个数据集——FashionMNIST——以便我们可以比较各种超参数变化的影响。通过这个数据集,我们还将了解训练和验证数据,以及为什么拥有两个独立的数据集很重要。最后,我们将了解过度拟合神经网络的概念,然后了解某些超参数如何帮助我们避免过度拟合。
总之,在本章中,我们将涵盖以下主题:
- 表示图像
- 为什么要利用神经网络进行图像分析?
- 为图像分类准备数据
- 训练神经网络
- 缩放数据集以提高模型准确性
- 了解改变批量大小的影响
- 了解改变损失优化器的影响
- 了解改变学习率的影响
- 了解学习率热处理的影响
- 构建更深层次的神经网络
- 了解批量标准化的影响
- 过拟合的概念
让我们开始吧!
表示图像
数字图像文件(通常与扩展名“JPEG”或“PNG”相关联)由像素数组组成。像素是图像的最小构成元素。在灰度图像中,每个像素都是 0 到 255之间的标量(单个)值——0是黑色,255 是白色,介于两者之间的任何东西都是灰色(像素值越小,像素越暗)。另一方面,彩色图像中的像素是三维矢量,对应于可以在其红色、绿色和蓝色通道中找到的标量值。
图像 的高度 x 宽度 xc像素,其中高度是像素的行数,宽度是像素的列数,c是通道数。c对于彩色图像(图像的红色、绿色和蓝色强度各一个通道)为 3,对于灰度图像为 1。此处显示了包含 3 x 3 像素及其相应标量值的示例灰度图像:
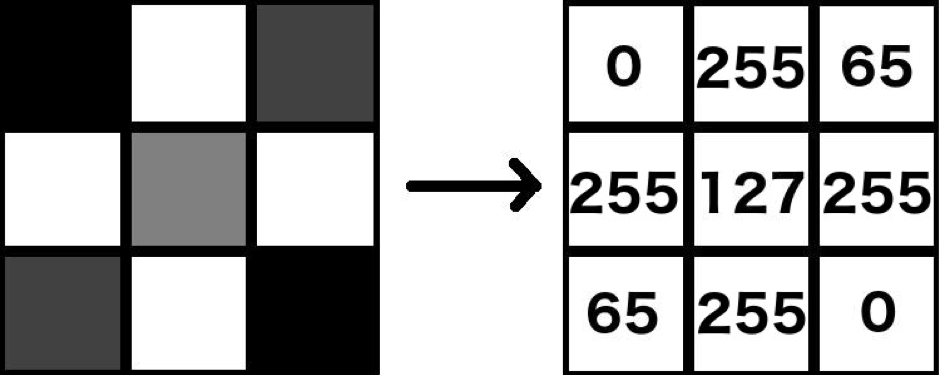
同样,像素值为 0 表示它是漆黑的,而 255 表示它是纯亮度(即,灰度为纯白色,彩色图像在相应通道中为纯红/绿/蓝)。
将图像转换为结构化数组和标量
Python 可以将图像转换为结构化数组和标量,如下所示:
1.下载示例图像:
!wget https://www.dropbox.com/s/l98leemr7r5stnm/Hemanvi.jpeg
2.导入cv2(用于从磁盘读取图像)和matplotlib(用于绘制加载的图像)库并将下载的图像读入 Python 环境:
%matplotlib inline
import cv2, matplotlib.pyplot as plt
img = cv2.imread( 'Hemanvi.jpeg' )
在前面的代码行中,我们使用了读取图像的方法。这会将图像转换为像素值数组。 cv2.imread
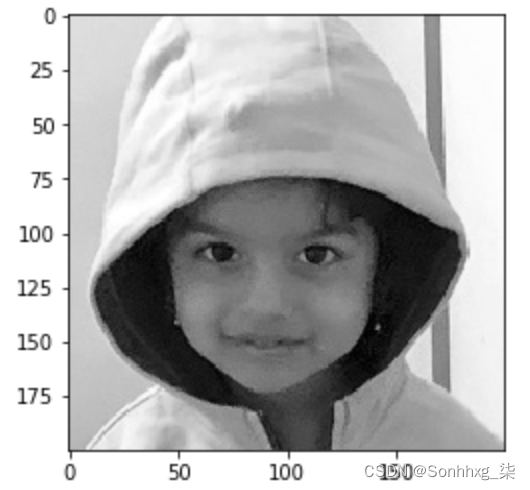
3.我们将在第 50-250 行以及第 40-240 列之间裁剪图像。最后,我们将使用以下代码将图像转换为灰度并绘制它:
# 裁剪图像
img = img[50:250,40:240]
# 将图像转换为灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 显示图像
plt.imshow(img_gray, cmap='gray')
上述步骤序列的输出如下:
您可能已经注意到前面的图像表示为 200 x 200 像素数组。现在,让我们减少用于表示图像的像素数量,以便我们可以在图像上叠加像素值(如果我们要在 200 x 200 数组上可视化像素值,这将更难做到) 25 x 25 阵列)。
4.将图像转换为 25 x 25 数组并绘制它:
img_gray_small = cv2.resize(img_gray,( 25 , 25 ))
plt.imshow(img_gray_small, cmap='gray')
这将产生以下输出:
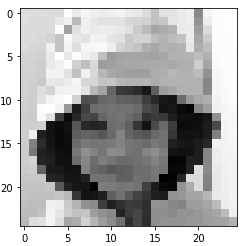
自然地,用更少的像素来表示相同的图像会导致输出更模糊。
5.让我们检查像素值。请注意,在以下输出中,由于空间限制,我们仅粘贴了前四行像素值:
print(img_gray_small)
这将产生以下输出:

将同一组像素值复制并粘贴到 Excel 中并按像素值进行颜色编码时,如下所示:

正如我们之前提到的,标量值接近 255 的像素看起来更亮,而接近 0 的像素看起来更暗。
前面的步骤也适用于彩色图像,它们表示为 3 维向量。最亮的红色像素表示为 (255,0,0)。类似地,三维矢量图像中的纯白色像素表示为 (255,255,255)。考虑到这一点,让我们为彩色图像创建一个结构化的像素值数组* *
1.下载彩色图像:
!wget https://www.dropbox.com/s/l98leemr7r5stnm/Hemanvi.jpeg
2.导入相关包并加载镜像:
import cv2, matplotlib.pyplot as plt
%matplotlib inline
img = cv2.imread( 'Hemanvi.jpeg' )
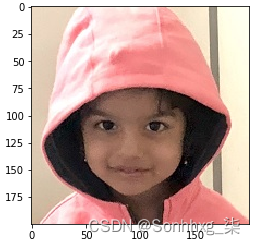
3.裁剪图像:
img = img[50:250,40:240,:]
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
请注意,在前面的代码中,我们使用 方法对通道进行了cv2.cvtcolor 重新排序。我们这样做是因为当我们 使用 cv2 导入图像时,通道的顺序是 首先是蓝色,其次是绿色,最后是红色;通常,我们习惯于查看 RGB 通道中的图像,其中的顺序是红色、绿色和蓝色。
4.绘制获得的图像(请注意,如果您正在阅读印刷书籍并且尚未下载彩色图像包,它将以灰度显示):
plt.imshow(img)
print(img.shape)
# (200,200,3)
这将产生以下输出:
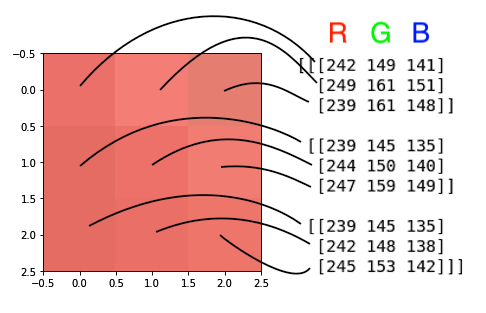
5.右下角的 3 x 3 像素阵列可以通过如下方式获得:
crop = img[-3:,-3:]
6.打印并绘制像素值:
print(crop)
plt.imshow(crop)
前面的代码产生以下输出:
现在我们可以将每个图像表示为标量数组(在灰度图像的情况下)或数组数组(在彩色图像的情况下),我们基本上已经将磁盘上的文件转换为结构化数组格式,现在可以使用多种技术进行数学处理。将图像转换为结构化的数字数组(即将图像读入 Python 内存)使我们能够对图像(表示为数字数组)执行数学运算。我们可以利用这种数据结构来执行各种任务,例如分类、检测和分割,所有这些都将在后面的章节中详细讨论。
现在我们已经了解了图像的表示方式,让我们了解利用神经网络进行图像分类的原因。
为什么要利用神经网络进行图像分析?
在传统的计算机视觉中,我们会在使用它们作为输入之前为每张图像创建一些特征。让我们根据以下示例图像来看看一些这样的特征,以了解我们通过训练神经网络避免的努力:

请注意,我们不会引导您了解如何获得这些功能,因为这里的目的是帮助您了解为什么手动创建功能不是最佳练习:
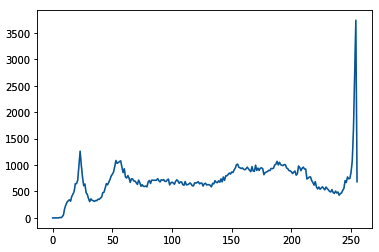
- Histogram feature(直方图特征):对于一些任务,比如自动亮度或夜视,了解图片中的光照很重要;也就是说,亮或暗像素的比例。下图显示了示例图像的直方图。它描绘了图像被很好地照亮,因为在 255 处有一个尖峰:
- Edges and Corners feature(边缘和角落特征):对于图像分割等任务,找到每个人对应的像素集很重要,首先提取边缘是有意义的,因为人的边界只是边缘的集合。在其他任务中,例如图像配准,检测关键地标至关重要。这些地标将是图像中所有角的子集。下图表示可以在我们的示例图像中找到的边缘和角落:

- Color separation feature(颜色分离功能):在自动驾驶汽车的交通信号灯检测等任务中,系统了解交通信号灯上显示的颜色非常重要。下图(最好以彩色方式查看)显示了示例图像的专用红色、绿色和蓝色像素:

- Image gradients feature(图像渐变 功能):更进一步,了解颜色在像素级别如何变化可能很重要。不同的纹理可以给我们不同的梯度,这意味着它们可以用作纹理检测器。事实上,找到梯度是边缘检测的先决条件。下图显示了我们示例图像的一部分的整体梯度,以及梯度的 y 和 x 分量:

这些只是其中的一小部分功能。还有很多,很难涵盖所有这些。创建这些特征的主要缺点是您需要成为图像和信号分析方面的专家,并且应该充分了解哪些特征最适合解决问题。即使满足这两个约束条件,也不能保证这样的专家能够找到正确的输入组合,即使找到了,也不能保证这样的组合在新的、看不见的场景中会起作用。
由于这些缺点,社区已在很大程度上转向基于神经网络的模型。这些模型不仅能自动找到正确的特征,还能学习如何将它们最佳组合以完成工作。正如我们在第一章中已经了解的那样,神经网络既可以作为特征提取器,也可以作为分类器。
现在我们已经了解了一些历史特征提取技术及其缺点的示例,让我们学习如何在图像上训练神经网络。
为图像分类准备我们的数据
鉴于我们在本章中涵盖了多个场景,为了让我们看到一个场景相对于另一个场景的优势,我们将在本章中使用一个数据集——Fashion MNIST 数据集。让我们准备这个数据集:
1.首先下载数据集并导入相关包。该包包含各种数据集——其中一个是我们将在本章中处理的数据集: torchvision FashionMNIST
from torchvision import datasets
import torch
data_folder = '~/data/FMNIST' # 这可以是任何目录
# 你想下载 FMNIST 到
fmnist = datasets.FashionMNIST(data_folder, download=True, \
train=True)
在前面的代码中,我们指定了data_folder要存储下载数据集的文件夹 ( )。接下来,我们从中获取数据并将其存储在. 此外,我们指定我们只想通过指定下载训练图像 fmnist datasets.FashionMNIST data_folder train = True
- 接下来,我们必须存储 as 中可用的图像和fmnist.dataas中可用的tr_images标签(目标):fmnist.targetstr_targets
tr_images = fmnist.data
tr_targets = fmnist.targets
2.检查我们正在处理的张量:
unique_values = tr_targets.unique()
print(f'tr_images & tr_targets:\n\tX -{tr_images.shape}\n\tY \
-{tr_targets.shape}\n\tY-Unique Values : {unique_values}')
print(f'TASK:\n\t{len(unique_values)} class Classification')
print(f'UNIQUE CLASSES:\n\t{fmnist.classes}')
上述代码的输出如下:

在这里,我们可以看到有 60,000 张图像,每张图像的大小为 28 x 28,并且所有图像都有 10 个可能的类别。请注意,其中包含每个类的数值,而为我们提供了与 中的每个数值对应的名称。 tr_targets fmnist.classes tr_targets
3.为所有 10 个可能的类别绘制 10 个图像的随机样本:
- 导入相关包以绘制图像网格,以便您还可以处理 数组:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
- 创建一个图,我们可以在其中显示一个 10 x 10 网格,其中网格的每一行对应一个类,每一列呈现一个属于该行类的示例图像。循环遍历唯一的类号 ( ) 并获取对应于给定类号label_class的行索引 ( ):label_x_rows
R, C = len(tr_targets.unique()), 10
fig, ax = plt.subplots(R, C, figsize=(10,10))
for label_class, plot_row in enumerate(ax):
label_x_rows = np.where( tr_targets == label_class)[0]
请注意,在前面的代码中,我们获取第 0个 索引作为条件的输出,因为np.where 它的长度为 1。它包含目标值 ( tr_targets) 等于的所有索引的数组。 label_class
- 循环 10 次以填充给定行的列。此外,我们需要ix从与先前获得的给定类对应的索引中选择一个随机值 ( ) ( label_x_rows) 并绘制它们:
for plot_cell in plot_row:
plot_cell.grid(False); plot_cell.axis('off')
ix = np.random.choice(label_x_rows)
x, y = tr_images[ix], tr_targets[ix]
plot_cell.imshow(x, cmap='gray')
plt.tight_layout()
这将产生以下 输出:

请注意,在上图中,每一行代表属于同一类的 10 个不同图像的样本。
现在我们已经学习了如何导入数据集,在 下一节中,我们将学习如何使用 PyTorch 训练神经网络,以便它接收图像并预测该图像的类别。此外,我们还将了解各种超参数对预测准确性的影响。
训练神经网络
要训练神经网络,我们必须执行以下步骤:
- 导入相关包。
- 构建一个可以一次获取一个数据点的数据的数据集。
- 从数据集中包装 DataLoader。
- 建立一个模型,然后定义损失函数和优化器。
- 定义两个函数来分别训练和验证一批数据。
- 定义一个函数来计算数据的准确性。
- 在越来越多的时期根据每批数据执行权重更新。
在以下代码行中,我们将执行以下每个步骤:
1.导入相关包和 FMNIST 数据集:
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
device = "cuda" if torch.cuda.is_available() else "cpu"
from torchvision import datasets
data_folder = '~/data/FMNIST' # This can be any directory you
# want to download FMNIST to
fmnist = datasets.FashionMNIST(data_folder, download=True, \
train=True)
tr_images = fmnist.data
tr_targets = fmnist.targets
2.构建一个获取数据集的类。请记住,它是从一个类派生的,并且需要始终定义Dataset三个魔术函数—— __init__、__getitem__和—— : len
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float()
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
请注意,在__init__该方法中,我们将输入转换为浮点数,并将每个图像展平为 28*28 = 784 个数值(其中每个数值对应一个像素值)。我们还在__len__方法中指定了数据点的数量;在这里,它是 x的长度。该__getitem__方法包含当我们请求ixth数据点时应该返回什么的逻辑(将是一个介于0和__len__之间的整数)。
3.创建一个从数据集生成训练 DataLoader 的函数 trn_dl,称为FMNISTDataset. 这将为批量大小随机采样 32 个数据点:
def get_data():
train = FMNISTDataset(tr_images, tr_targets)
trn_dl = DataLoader(train, batch_size=32, shuffle=True)
return trn_dl
在前面几行代码中,我们创建了一个名为的类的对象,并调用了DataLoader,让它随机获取32个数据点,返回训练用的DataLoader;也就是说,.FMNISTDataset train trn_dl
4.定义一个模型,以及损失函数和优化器:
from torch.optim import SGD
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-2)
return model, loss_fn, optimizer
该模型是一个具有一个包含 1,000 个神经元的隐藏层的网络。因为有 10 个可能的类,所以输出是 10 个神经元层。此外,我们正在调用该CrossEntropyLoss函数,因为输出可以属于每个图像的 10 个类中的任何一个。最后,在本练习中要注意的关键方面是我们已将学习率 初始化lr为0.01而不是默认值 0.001,以查看模型将如何学习本练习。
请注意,我们根本没有在神经网络中使用“softmax”。输出范围不受限制,因为值可以具有无限范围,而交叉熵损失通常期望输出为概率(每一行的总和应为 1)。这在此设置中仍然有效,因为nn.CrossEntropyLoss实际上希望我们发送原始 logits(即不受约束的值)。它在内部执行 softmax。
5.定义将在一批图像上训练数据集的函数:
def train_batch(x, y, model, opt, loss_fn):
model.train() # <- 让我们坚持下去,直到我们到达
# dropout 部分
# 像你批次上的任何 python 函数一样调用你的模型
# 输入
prediction = model(x)
# 计算损失
batch_loss = loss_fn(prediction, y)
# 基于 `model(x)` 中的前向传递计算所有
# 'model.parameters()' 的梯度
batch_loss.backward()
# 应用 new-weights= f(old-weights, old-weight-gradients)
# 其中“f”是优化器
optimizer.step()
# 为下一批计算刷新梯度内存
optimizer.zero_grad()
return batch_loss.item()
前面的代码在前向传递中通过模型传递这批图像。它还计算批量损失,然后通过反向传播传递权重并更新它们。最后, 它会刷新梯度的内存, 这样它就不会影响在下一次传递中如何计算梯度。
现在我们已经这样做了,我们可以通过在. batch_loss.item() batch_loss
6.构建一个计算给定 数据集准确性的函数:
# 因为不需要更新权重,
# 我们不妨不计算梯度。
# 在函数之上使用这个 '@' 装饰器
# 将禁用整个函数中的梯度计算
@torch.no_grad()
def accuracy(x, y, model):
model.eval() # <- 让我们等到dropout
# section
# 获取`x`图像张量的预测矩阵
prediction = model(x)
# 计算每行中最大值的位置是否
# coincides with ground truth
max_values, argmaxes = prediction.max(-1)
is_correct = argmaxes == y
return is_correct.cpu().numpy().tolist()
在前面的代码行中,我们明确提到我们不需要通过通过模型前馈输入来提供@torch.no_grad() 和计算prediction值来计算梯度。
接下来,我们调用 prediction.max(-1)以识别对应于每一行的 argmax 索引。
此外,我们正在将我们的结果argmaxes 与基本事实进行比较,以便我们可以检查每一行是否被argmaxes == y正确预测。最后,我们将对象列表is_correct移动到 CPU 并将其转换为 numpy 数组后返回。
7.使用以下代码行训练神经网络:
- 初始化模型、损失、优化器和数据加载器:
trn_dl = get_data()
model, loss_fn, optimizer = get_model()
- 在每个 epoch 结束时调用包含准确率和损失值的列表:
losses, accuracies = [], []
- 定义时期数:
for epoch in range(5):
print(epoch)
- 调用将包含一个时期内每个批次对应的准确率和损失值的列表:
epoch_losses, epoch_accuracies = [], []
- 通过迭代 DataLoader 创建批量训练数据:
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
- 使用该函数训练批次,并将训练结束时的损失值存储在批次之上。此外,将不同批次的损失值存储在列表中: train_batch batch_lossepoch_losses
batch_loss = train_batch(x, y, model, optimizer, \
loss_fn)
epoch_losses.append(batch_loss)
- 我们存储一个时期内所有批次的平均损失值:
epoch_loss = np.array(epoch_losses).mean()
- 接下来,我们在所有批次的训练结束时计算预测的准确性:
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
is_correct = accuracy(x, y, model)
epoch_accuracies.extend(is_correct)
epoch_accuracy = np.mean(epoch_accuracies)
- 将每个 epoch 结束时的损失和准确率值存储在列表中:
losses.append(epoch_loss)
accuracies.append(epoch_accuracy)
可以使用以下代码显示训练损失和准确率随时间增加的变化:
epochs = np.arange(5)+1
plt.figure(figsize=(20,5))
plt.subplot(121)
plt.title('Loss value over increasing epochs')
plt.plot(epochs, losses, label='Training Loss')
plt.legend()
plt.subplot(122)
plt.title('Accuracy value over increasing epochs')
plt.plot(epochs, accuracies, label='Training Accuracy')
plt.gca().set_yticklabels(['{:.0f}%'.format(x*100) \
for x in plt.gca().get_yticks()])
plt.legend()
上述代码的输出如下:
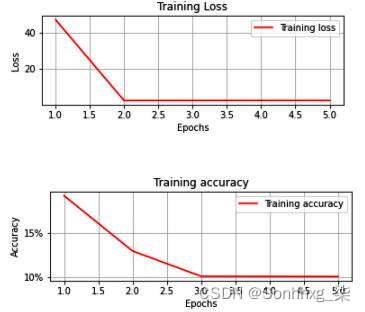
在五个 epoch 结束时,我们的训练准确率为 12%。请注意,随着 epoch 数量的增加,损失值并没有显着降低。换句话说,无论我们等待多长时间,该模型都不太可能提供高精度(例如,超过 80%)。这要求我们了解所使用的各种超参数如何影响我们神经网络的准确性。
请注意,由于我们没有保留torch.random_seed(0),因此执行提供的代码时结果可能会有所不同。然而,你得到的结果也应该让你得出类似的结论。
现在您已经全面了解了如何训练神经网络,让我们研究一些我们应该遵循的良好实践,以实现良好的模型性能以及使用它们的原因。这可以通过微调各种超参数来实现,其中一些我们将在接下来的部分中介绍。
缩放数据集以提高模型准确性
缩放数据集是确保变量被限制在有限范围内的过程。在本节中,我们将通过将每个输入值除以数据集中的最大可能值,将自变量的值限制在 0 和 1 之间。这是一个 255 的值,对应于白色像素:
1.获取数据集,以及训练图像和目标,就像我们在上一节中所做的那样:
from torchvision import datasets
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
device = "cuda" if torch.cuda.is_available() else "cpu"
import numpy as np
data_folder = '~/data/FMNIST' # This can be any directory you
# want to download FMNIST to
fmnist = datasets.FashionMNIST(data_folder, download=True, \
train=True)
tr_images = fmnist.data
tr_targets = fmnist.targets
2.修改,获取数据,使输入图像除以 255(像素的最大强度/值): FMNISTDataset
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float()/255
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
请注意,与上一节相比,我们在此处所做的唯一更改是我们将输入数据除以最大可能的像素值– 255。
假设像素值介于 0 到 255 之间,将它们除以 255 将得到始终介于 0 到 1 之间的值。
3.训练一个模型,就像我们在上一节的步骤 4、5、6和7中所做的那样:
- 获取数据:
def get_data():
train = FMNISTDataset(tr_images, tr_targets)
trn_dl = DataLoader(train, batch_size=32, shuffle=True)
return trn_dl
- 定义模型:
from torch.optim import SGD
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-2)
return model, loss_fn, optimizer
- 定义用于训练和验证一批数据的函数:
def train_batch(x, y, model, opt, loss_fn):
model.train()
# 调用你的模型,就像你的批处理上的任何 python 函数一样
# 输入
prediction = model(x)
# 计算损失
batch_loss = loss_fn(prediction, y)
# 基于 `model(x)` 中的前向传递计算所有
# 'model.parameters()' 的梯度
batch_loss.backward()
# apply new-weights = f(old-weights, old-weight-gradients)
#其中“f”是优化器
optimizer.step()
# 为下一批计算刷新内存
optimizer.zero_grad()
return batch_loss.item()
@torch.no_grad()
def accuracy(x, y, model):
model.eval ()
# 获取 `x` 图像张量的预测矩阵
prediction = model(x)
# 计算每行中最大值的位置是否
# 与地面实况一致
max_values, argmaxes = prediction.max(-1)
is_correct = argmaxes == y
return is_correct.cpu().numpy().tolist()
- 在越来越多的时期训练模型:
trn_dl = get_data()
model, loss_fn, optimizer = get_model()
losses, accuracies = [], []
for epoch in range(5):
print(epoch)
epoch_losses, epoch_accuracies = [], []
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
batch_loss = train_batch(x, y, model, optimizer,
loss_fn)
epoch_losses.append(batch_loss)
epoch_loss = np.array(epoch_losses).mean()
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
is_correct = accuracy(x, y, model)
epoch_accuracies.extend(is_correct)
epoch_accuracy = np.mean(epoch_accuracies)
losses.append(epoch_loss)
accuracies.append(epoch_accuracy)
训练损失和准确率值的变化如下:
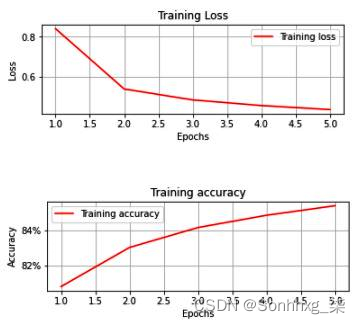
正如我们所看到的,训练损失不断减少,训练精度不断提高,从而将 epochs 提高到约 85% 的精度。
将前面的输出与输入数据未缩放的场景进行对比,其中训练损失没有持续减少,五个 epoch 结束时训练数据集的准确率仅为 12%。
让我们深入探讨缩放在这里有帮助的可能原因。
让我们以如何计算 sigmoid 值为例:
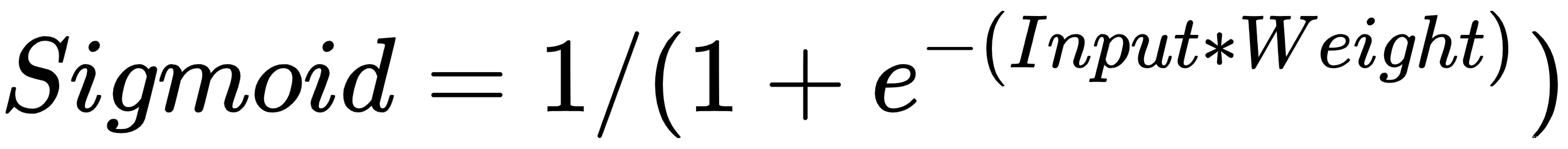
在下表中,我们根据前面的公式计算了Sigmoid列:
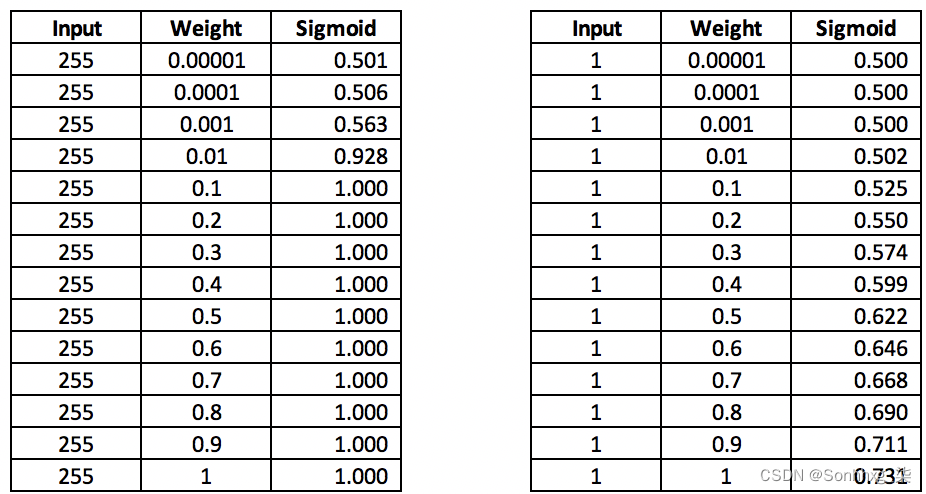
在左侧表格中,我们可以看到当权重值大于 0.1 时,Sigmoid 值不会随着权重值的增加(变化)而变化。此外,当权重极小时,Sigmoid 值变化不大;改变 sigmoid 值的唯一方法是将权重更改为非常非常小的量。
然而,当输入值较小时,右侧表格中的 Sigmoid 值变化很大。
原因是大负值的指数(由权重值乘以一个大数产生)非常接近于 0,而当权重乘以缩放输入时,指数值会发生变化,如右手边的桌子。
既然我们已经了解除非权重值非常小,否则 Sigmoid 值不会发生很大变化,现在我们将了解如何影响权重值以达到最佳值。
缩放输入数据集以使其包含更小范围的值通常有助于实现更好的模型准确性。
接下来,我们将了解任何神经网络的其他主要超参数之一的影响:批量大小。
了解改变批量大小的影响
在上一节中,训练数据集中每批考虑 32 个数据点。这导致每个 epoch 的权重更新次数更多,因为每个 epoch 有 1,875 次权重更新(60,000/32 几乎等于 1,875,其中 60,000 是训练图像的数量)。
此外,我们没有考虑模型在看不见的数据集(验证数据集)上的性能。我们将在本节中对此进行探讨。
在本节中,我们将比较以下内容:
- 当训练批量大小为 32 时,训练和验证数据的损失和准确度值。
- 当训练批量大小为 10,000 时,训练和验证数据的损失和准确度值。
现在我们已经将验证数据引入图片中,让我们重新运行构建神经网络部分中提供的代码,并添加额外的代码来生成验证数据,以及计算验证数据集的损失和准确度值。
批量大小 32
鉴于我们已经构建了一个在训练期间使用 32 批大小的模型,我们将详细说明用于处理验证数据集的附加代码。我们将跳过训练模型的细节,因为这已经出现在构建神经网络部分。让我们开始吧:
1.下载并导入训练图像和目标:
from torchvision import datasets
import torch
data_folder = '~/data/FMNIST' # This can be any directory you
# want to download FMNIST to
fmnist = datasets.FashionMNIST(data_folder, download=True, \
train=True)
tr_images = fmnist.data
tr_targets = fmnist.targets
2.与训练图像类似,我们必须通过在数据集中调用方法train = False时指定来下载和导入验证数据集FashionMNIST:
val_fmnist =datasets.FashionMNIST(data_folder,download=True, \
train=False)
val_images = val_fmnist.data
val_targets = val_fmnist.targets
3.导入相关包并定义device:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
device = 'cuda' if torch.cuda.is_available() else 'cpu'
4.定义数据集类 ( FashionMNIST)、用于训练一批数据的函数 ( train_batch)、计算准确度 ( accuracy),然后定义模型架构、损失函数和优化器 ( get_model)。请注意,获取数据的函数将是唯一与我们在前面部分中看到的函数有偏差的函数(因为我们现在正在处理训练和验证数据集),因此我们将在下一步中构建它:
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float()/255
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
from torch.optim import SGD, Adam
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-2)
return model, loss_fn, optimizer
def train_batch(x, y, model, opt, loss_fn):
model.train()
prediction = model(x)
batch_loss = loss_fn(prediction, y)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
def accuracy(x, y, model):
model.eval()
# this is the same as @torch.no_grad
# at the top of function, only difference
# being, grad is not computed in the with scope
with torch.no_grad():
prediction = model(x)
max_values, argmaxes = prediction.max(-1)
is_correct = argmaxes == y
return is_correct.cpu().numpy().tolist()
5.定义一个将获取数据的函数;也就是说,get_data. 此函数将返回批大小为 32 的训练数据和批大小为验证数据长度的验证数据集(我们不会使用验证数据来训练模型;我们只会使用它来了解模型的未见数据的准确性):
def get_data():
train = FMNISTDataset(tr_images, tr_targets)
trn_dl = DataLoader(train, batch_size=32, shuffle=True)
val = FMNISTDataset(val_images, val_targets)
val_dl = DataLoader(val, batch_size=len(val_images),
shuffle=False)
return trn_dl, val_dl
在前面的代码中,除了我们之前看到的对象之外,我们还创建了一个名为的类的对象。此外,用于验证的DataLoader (. 在本节和下一节中,我们将尝试根据模型的训练时间和准确性来了解变化的影响。FMNISTDataset valtrain val_dl len(val_images) trn_dl batch_size
6.定义一个计算验证数据损失的函数;也就是说,. 请注意,我们是单独计算的,因为在训练模型时会计算训练数据的损失: val_loss
@torch.no_grad()
def val_loss(x, y, model):
model.eval()
prediction = model(x)
val_loss = loss_fn(prediction, y)
return val_loss.item()
如您所见,我们正在申请,因为我们没有训练模型,只获取预测。此外,我们通过损失函数 ( ) 并返回损失值 ( )。 torch.no_grad prediction loss_fnval_loss.item()
7.获取训练和验证 DataLoaders。此外,初始化模型、损失函数和优化器:
trn_dl, val_dl = get_data()
model, loss_fn, optimizer = get_model()
8.训练模型,如下:
- 初始化包含训练和验证准确性的列表,以及增加时期的损失值:
train_losses, train_accuracies = [], []
val_losses, val_accuracies = [], []
- 循环五个时期并初始化包含给定时期内各批训练数据的准确性和损失的列表:
for epoch in range(5):
print(epoch)
train_epoch_losses, train_epoch_accuracies = [], []
- 遍历一批训练数据并计算一个 epoch 内的准确率 ( train_epoch_accuracy) 和损失值 ( ):train_epoch_loss
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
batch_loss = train_batch(x, y, model, optimizer, \
loss_fn)
train_epoch_losses.append(batch_loss)
train_epoch_loss = np.array(train_epoch_losses).mean()
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
is_correct = accuracy(x, y, model)
train_epoch_accuracies.extend(is_correct)
train_epoch_accuracy = np.mean(train_epoch_accuracies)
- 计算一批验证数据内的损失值和准确率(因为验证数据的批大小等于验证数据的长度):
for ix, batch in enumerate(iter(val_dl)):
x, y = batch
val_is_correct = accuracy(x, y, model)
validation_loss = val_loss(x, y, model)
val_epoch_accuracy = np.mean(val_is_correct)
请注意,在前面的代码中,验证数据的损失值是使用函数计算的val_loss ,并存储在变量validation_loss 中。此外,所有验证数据点的准确性都存储在列表val_is_correct 中,而平均值存储在变量中。 val_epoch_accuracy
- 最后,我们将训练和验证数据集的准确度和损失值附加到包含时代级别聚合验证和准确度值的列表中。我们这样做是为了在下一步中查看 epoch 级别的改进:
train_losses.append(train_epoch_loss)
train_accuracies.append(train_epoch_accuracy)
val_losses.append(validation_loss)
val_accuracies.append(val_epoch_accuracy)
9.可视化训练和验证数据集中的准确性和损失值在增加的 时期内的改进:
epochs = np.arange(5)+1
import matplotlib.ticker as mtick
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
%matplotlib inline
plt.subplot(211)
plt.plot(epochs, train_losses, 'bo', label='Training loss')
plt.plot(epochs, val_losses, 'r', label='Validation loss')
plt.gca().xaxis.set_major_locator(mticker.MultipleLocator(1))
plt.title('Training and validation loss \
when batch size is 32')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()
plt.subplot(212)
plt.plot(epochs, train_accuracies, 'bo', \
label='Training accuracy')
plt.plot(epochs, val_accuracies, 'r', \
label='Validation accuracy')
plt.gca().xaxis.set_major_locator(mticker.MultipleLocator(1))
plt.title('Training and validation accuracy \
when batch size is 32')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.gca().set_yticklabels(['{:.0f}%'.format(x*100) \
for x in plt.gca().get_yticks()])
plt.legend()
plt.grid('off')
plt.show()
前面的代码为我们提供了以下输出:
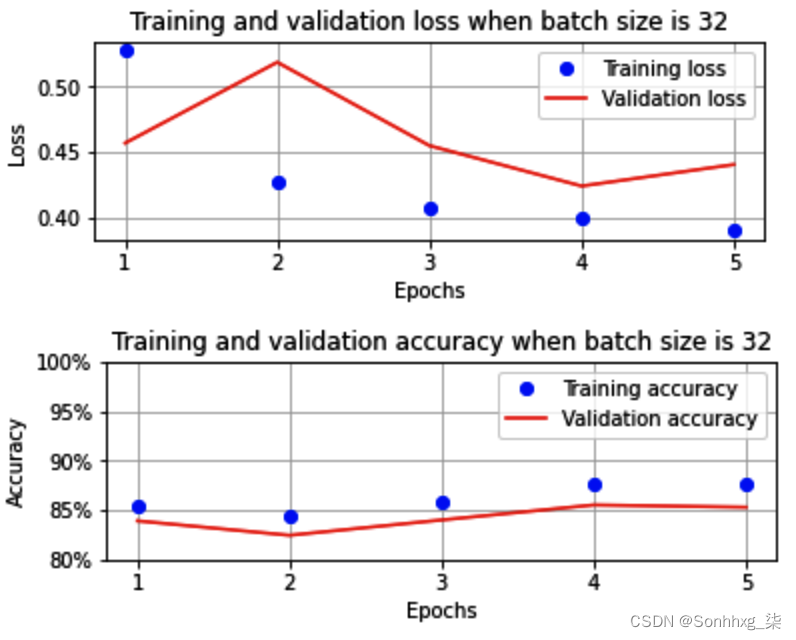
如您所见,当批大小为 32 时,到五个 epoch 结束时,训练和验证的准确率约为 85%。接下来,我们batch_size 将在 get_data函数中训练 DataLoader 时改变参数batch_size ,看看它对最后准确率的影响五个时代。
批量大小为 10,000
在本节中,我们将每批次使用 10,000 个数据点,以便我们了解改变批次大小的影响。
请注意,Batch size of 32部分中提供的代码在此处保持完全相同,除了第 5 步中的代码。在这里,我们将在get_data 函数中为训练和验证数据集指定 DataLoaders 。
在从训练数据集中获取训练 DataLoader 时,我们将对其进行修改,使其批量大小为 10,000,如下所示: get_data
def get_data():
train = FMNISTDataset(tr_images, tr_targets)
trn_dl = DataLoader(train, batch_size=10000, shuffle=True)
val = FMNISTDataset(val_images, val_targets)
val_dl = DataLoader(val, batch_size=len(val_images), \
shuffle=False)
return trn_dl, val_dl
通过仅在步骤 5中进行必要的更改,并在执行所有步骤直到步骤 9之后,当批量大小为 10,000 时,训练和验证的准确性和损失在增加的时期内的变化如下:
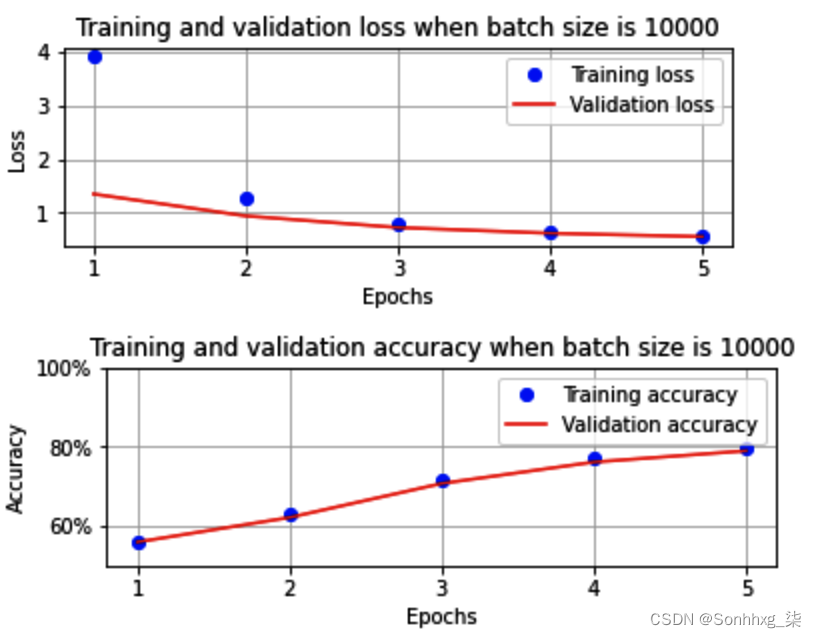
在这里, 我们可以看到准确率和损失值没有达到与前一个场景相同的水平,即批量大小为 32,因为当批量大小为 32 (1875) 时,时间权重的更新次数较少。在批量大小为 10,000 的场景中,每个 epoch 有 6 次权重更新,因为每个批次有 10,000 个数据点,这意味着总训练数据大小为 60,000。
到目前为止,我们已经学习了如何缩放数据集,以及改变批大小对模型训练时间的影响,以达到一定的准确性。在下一节中,我们将了解改变损失优化器对同一数据集的影响。
当您的 epoch 数量较少时,具有较低的批量大小通常有助于实现最佳准确度,但它不应该太低以至于影响训练时间。
了解改变损失优化器的影响
到目前为止,我们一直在基于 Adam 优化器优化损失。在本节中,我们将执行以下操作:
- 修改优化器,使其成为随机梯度下降( SGD ) 优化器
- 在 DataLoader 中获取数据时恢复为 32 的批处理大小
- 将 epoch 数增加到 10(以便我们可以比较 SGD 和 Adam 在更长的 epoch 数上的性能)
进行这些**更改意味着在Batch size of 32部分中只有一步会改变(因为在Batch size of 32部分中批量大小已经是 32);也就是说,我们将修改优化器,使其成为 SGD 优化器。
让我们修改Batch size of 32部分的**第 4 步中的get_model函数,以修改优化器,以便我们使用 SGD 优化器,如下所示:
1.修改优化器,以便在函数中使用 SGD 优化器,get_model 同时确保其他所有内容保持不变:
from torch.optim import SGD, Adam
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-2)
return model, loss_fn, optimizer
现在,让我们在第 8 步中增加 epoch 的数量,同时保持其他每一步(除了第4 步和第 8步)与它们在32 的批量大小部分中的相同。
2.增加我们将用于训练模型的 epoch 数:
train_losses, train_accuracies = [], []
val_losses, val_accuracies = [], []
for epoch in range(10):
train_epoch_losses, train_epoch_accuracies = [], []
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
batch_loss = train_batch(x, y, model, optimizer, \
loss_fn)
train_epoch_losses.append(batch_loss)
train_epoch_loss = np.array(train_epoch_losses).mean()
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
is_correct = accuracy(x, y, model)
train_epoch_accuracies.extend(is_correct)
train_epoch_accuracy = np.mean(train_epoch_accuracies)
for ix, batch in enumerate(iter(val_dl)):
x, y = batch
val_is_correct = accuracy(x, y, model)
validation_loss = val_loss(x, y, model)
val_epoch_accuracy = np.mean(val_is_correct)
train_losses.append(train_epoch_loss)
train_accuracies.append(train_epoch_accuracy)
val_losses.append(validation_loss)
val_accuracies.append(val_epoch_accuracy)
进行这些更改后,一旦我们按顺序执行Batch size of 32部分中的所有剩余步骤,训练和验证数据集的准确度和损失值随时间增加的变化如下:
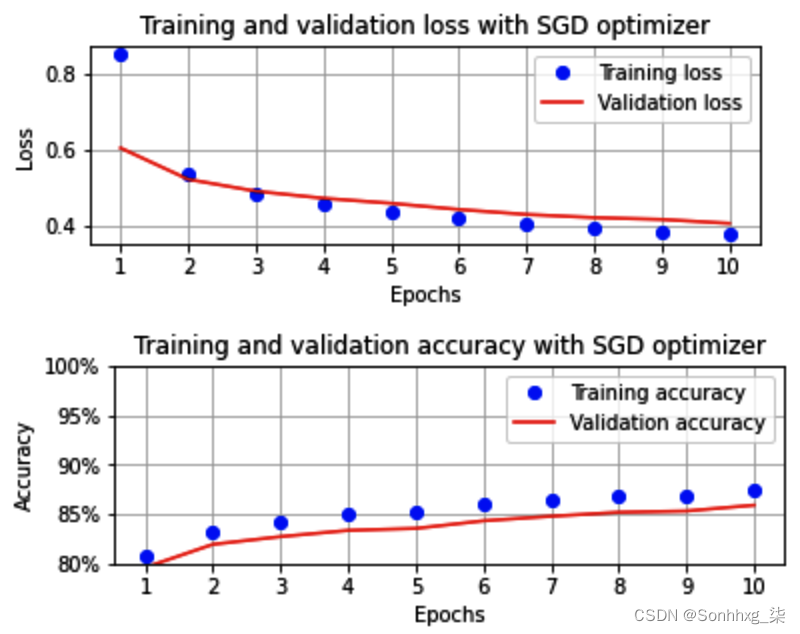
在优化器是 Adam 的情况下,让我们为训练和验证损失以及精度变化获取相同的输出。这需要我们将第 4 步中的优化器更改为 Adam。
进行此更改并执行代码后,训练和验证数据集的准确性和损失值的变化如下:
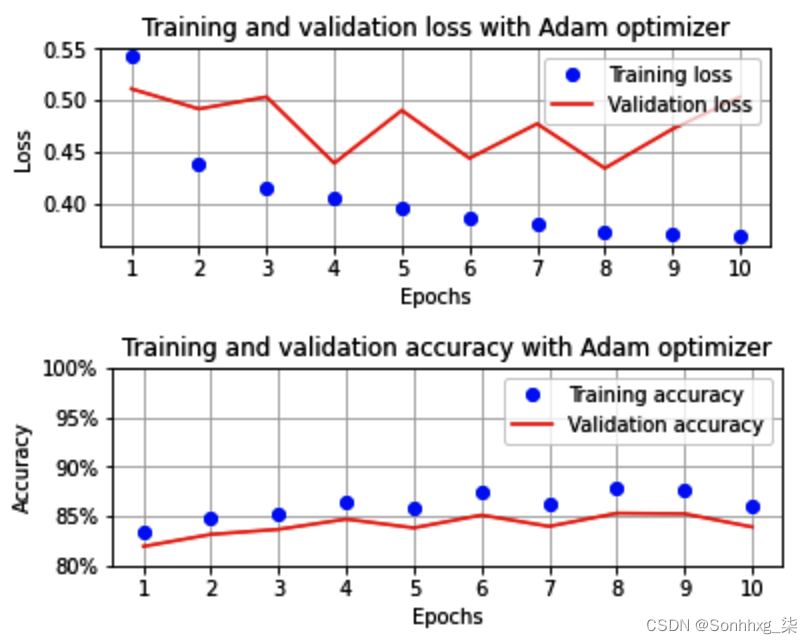
如您所见,当我们使用 Adam 优化器时,准确率仍然非常接近 85%。但是请注意,到目前为止,学习率一直是 0.01。
在下一节中,我们将了解学习率对验证数据集准确性的影响。
与其他优化器相比,某些优化器可以更快地实现最佳精度。Adam 通常更快地达到最佳准确度。其他一些可用的著名优化器包括 Adagrad、Adadelta、AdamW、LBFGS 和 RMSprop。
了解改变学习率的影响
到目前为止,我们在训练模型时一直使用 0.01 的学习率。在第 1 章“人工神经网络基础”中,我们了解到学习率在获得最优权重值方面起着关键作用。这里,当学习率较小时,权重值会逐渐向最优值移动,而当学习率较大时,权重值会在非最优值处振荡。我们在第 1 章“人工神经网络基础”中研究了一个玩具数据集,因此我们将在本节中研究一个现实场景。
为了理解不同学习率的影响,我们将经历以下场景:
- 缩放数据集上的更高学习率 (0.1)
- 缩放数据集上的较低学习率 (0.00001)
- 在非缩放数据集上降低学习率 (0.001)
- 非缩放数据集上的更高学习率 (0.1)
总的来说,在本节中,我们将了解各种学习率值对缩放和非缩放数据集的影响。
在本节中,我们将了解学习率对非缩放数据的影响,尽管我们已经确定它有助于缩放数据集。我们再次这样做是因为我们希望您直观地了解权重分布在模型能够适应数据的情况与模型无法适应数据的情况之间如何变化。
现在,让我们了解模型如何在缩放数据集上学习。
学习率对缩放数据集的影响
在本节中,我们将训练和验证数据集的准确性与以下内容进行对比:
- 高学习率
- 中等学习率
- 学习率低
以下三个小节的代码可Varying_learning_rate_on_scaled_data.ipynb 在Chapter03本书 GitHub 存储库的文件夹中找到- https://tinyurl.com/mcvp-packt。请注意,为简洁起见,我们并未提供所有步骤;下面的代码将只讨论与我们在Batch size of 32部分中经历的代码相比发生变化的步骤。我们鼓励您在执行代码时参考本书 GitHub 存储库中的相应笔记本。
让我们开始吧!
高学习率
在本节中,我们将采用以下策略:
- 当我们使用 Adam 优化器时,我们需要执行的步骤将与Batch size of 32部分完全相同。
- 唯一的变化optimizer是我们定义get_model函数时的学习率。在这里,我们将学习率 (lr ) 更改为 0.1。
请注意,所有代码都与Batch size of 32部分中的相同,除了我们将在本节中对 get_model函数进行的修改。
要修改学习率,我们必须在函数的定义中进行修改 optimizer,可以在get_model函数中找到,如下:
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-1)
return model, loss_fn, optimizer
请注意,在前面的代码中,我们修改了优化器,使其学习率为 0.1 ( lr=1e-1)。
一旦我们执行了 GitHub 中提供的所有剩余步骤,对应于训练和验证数据集的准确率和损失值将如下所示:
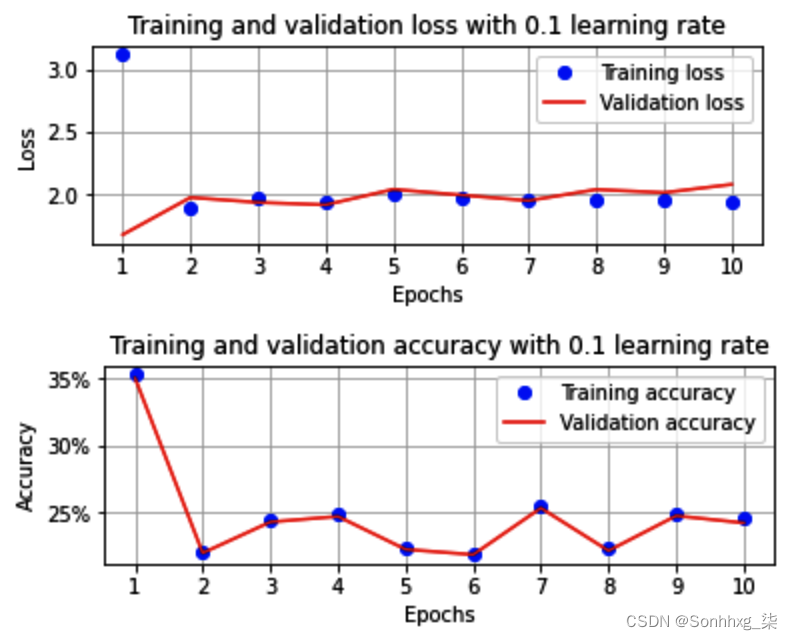
请注意,验证数据集的准确度约为 25%(将此准确度与我们在学习率为 0.01 时获得的约 85% 准确度进行对比)。
在下一节中,我们将了解在学习率中等(0.001)时验证数据集的准确性。
中等学习率
在本节中,我们将通过修改函数并从头开始重新训练模型,将优化器的学习率降低到 0.001 。 get_model
修改后的get_model 函数代码如下:
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
请注意,在前面的代码中,由于我们修改了参数值,因此学习率已降低到一个较小的值。 lr
一旦我们执行了 GitHub 中提供的所有剩余步骤,对应于训练和验证数据集的准确率和损失值将如下所示:
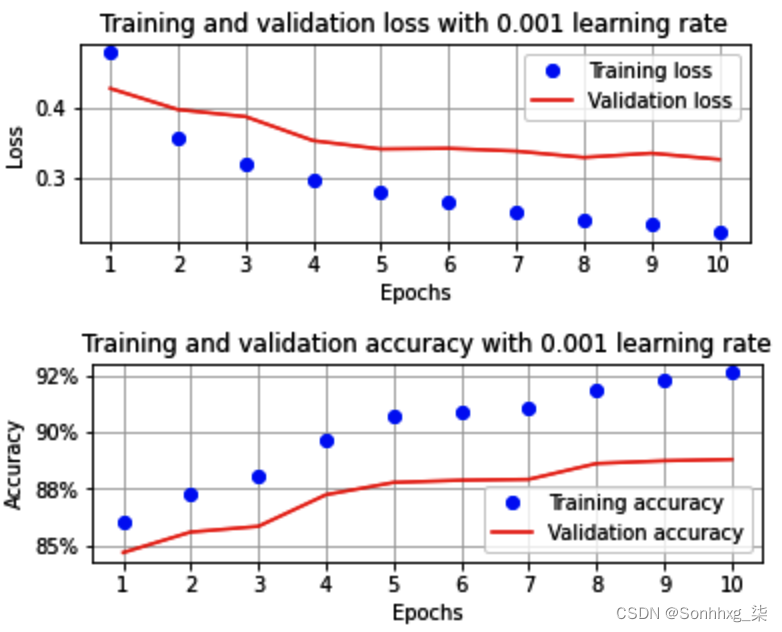
从前面的输出可以看出,当学习率 ( or) 从 0.1 降低到 0.001时,模型训练成功
在下一节中,我们将进一步降低学习率。
学习率低
在本节中,我们将通过修改函数并从头开始重新训练模型,将优化器的学习率降低到 0.00001 。此外,我们将运行模型更长的时期(100)。 get_model
我们将用于该get_model 函数的修改后的代码如下:
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-5)
return model, loss_fn, optimizer
请注意,在前面的代码中,由于我们修改了参数值,学习率已经降低到一个非常小的值。 lr
一旦我们执行了 GitHub 中提供的所有剩余步骤,对应于训练和验证数据集的准确率和损失值将如下所示:
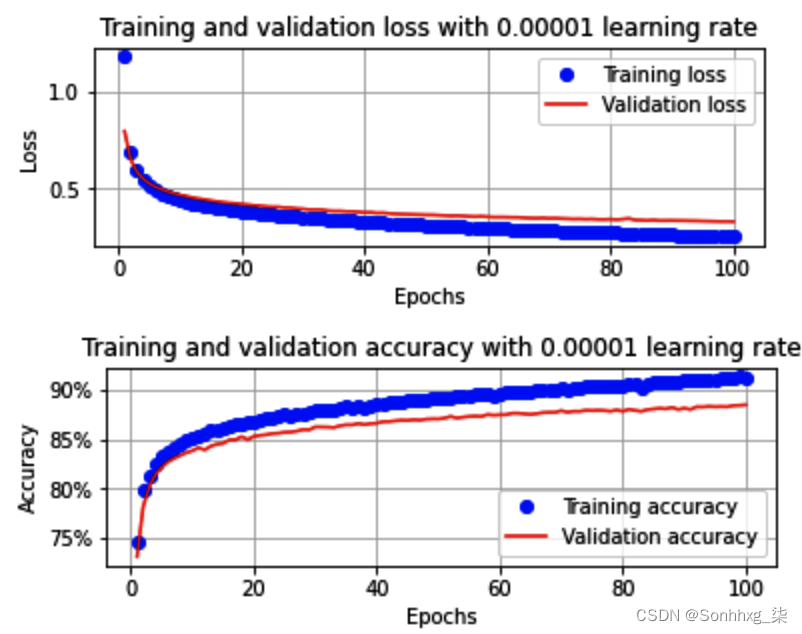
从上图中,我们可以看到模型的学习速度比之前的场景慢得多(中等学习率)。在这里,与学习率为 0.001 时的 8 个 epoch 相比,需要 100 个 epoch 才能达到约 89% 的准确度。
此外,我们还应该注意到,与之前的场景相比,当学习率较低时,训练和验证损失之间的差距要小得多(在 epoch 4 结束时存在类似的差距)。这样做的原因是,当学习率低时,权重更新要低得多,这意味着训练和验证损失之间的差距并没有迅速扩大。
到目前为止,我们已经了解了学习率对训练和验证数据集准确性的影响。在下一节中,我们将了解不同学习率值的权重值分布在各层之间如何变化。
不同学习率的跨层参数分布
在前面的部分中,我们了解到,在高学习率(0.1)的情况下,模型无法被训练(模型欠拟合)。但是,我们可以训练模型,使其在学习率中等(0.001)或低(0.00001)时具有不错的准确性。在这里,我们看到中等学习率能够快速过拟合,而低学习率需要更长的时间才能达到与中等学习率模型相媲美的准确度。
在本节中,我们将了解参数分布如何成为模型过拟合和欠拟合的良好指标。
到目前为止,我们的模型中有四个参数组:
- 连接输入层和隐藏层的层中的权重
- 隐藏层中的偏差
- 连接隐藏层和输出层的层中的权重
- 输出层的偏差
让我们使用以下代码来看看每个参数的分布情况(我们将为每个模型执行以下代码):
for ix, par in enumerate(model.parameters()):
if(ix==0):
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of weights conencting \
input to hidden layer')
plt.show()
elif(ix ==1):
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of biases of hidden layer')
plt.show()
elif(ix==2):
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of weights conencting \
hidden to output layer')
plt.show()
elif(ix ==3):
plt.hist(par.cpu().detach().numpy().flatten())
plt.title('Distribution of biases of output layer')
plt.show()
请注意model.parameters,这会因我们绘制分布的模型而异。上述代码跨三种学习率的输出如下:
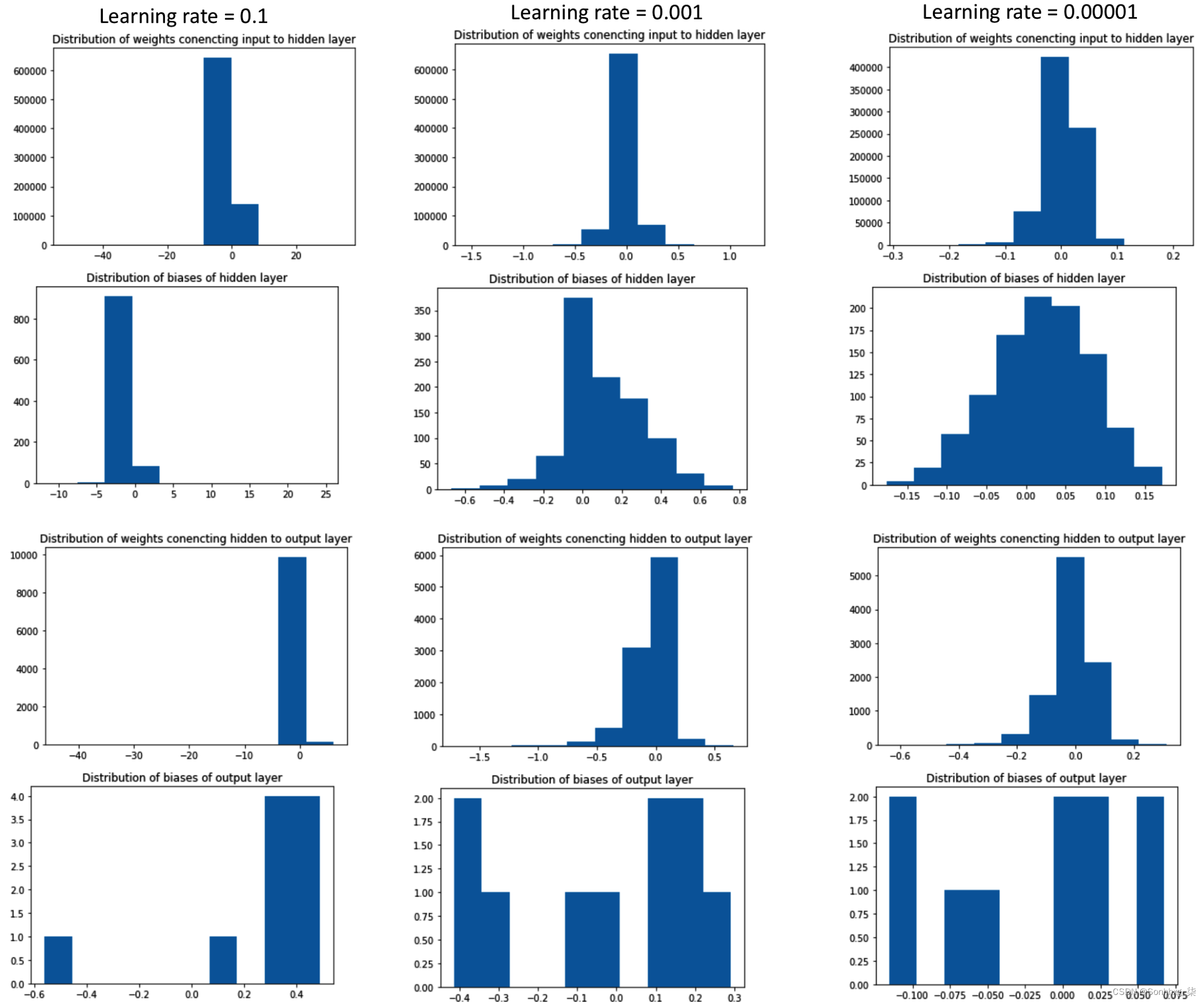
在这里,我们可以看到以下内容:
- 当学习率高时,与中低学习率相比,参数的分布要大得多。
- 当参数分布较大时,就会发生过拟合。
到目前为止,我们已经研究了改变学习率对在缩放数据集上训练的模型的影响。在下一节中,我们将了解改变学习率对使用非缩放数据进行训练的模型的影响。
请注意,即使我们已经确定始终缩放输入值会更好,但我们将继续确定在非缩放数据集上训练模型的影响。
改变学习率对非缩放数据集的影响
在本节中,我们将通过在定义数据集的类中不执行除以 255 来恢复处理数据集。这可以这样做:
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float() # Note that the data is not scaled in this
# scenario
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
请注意,在前面代码 ( x = x.float()) 中突出显示的部分中,我们没有除以 255,这是我们在缩放数据集时执行的。
通过改变跨时期的准确率和损失值来改变学习率的结果 如下:
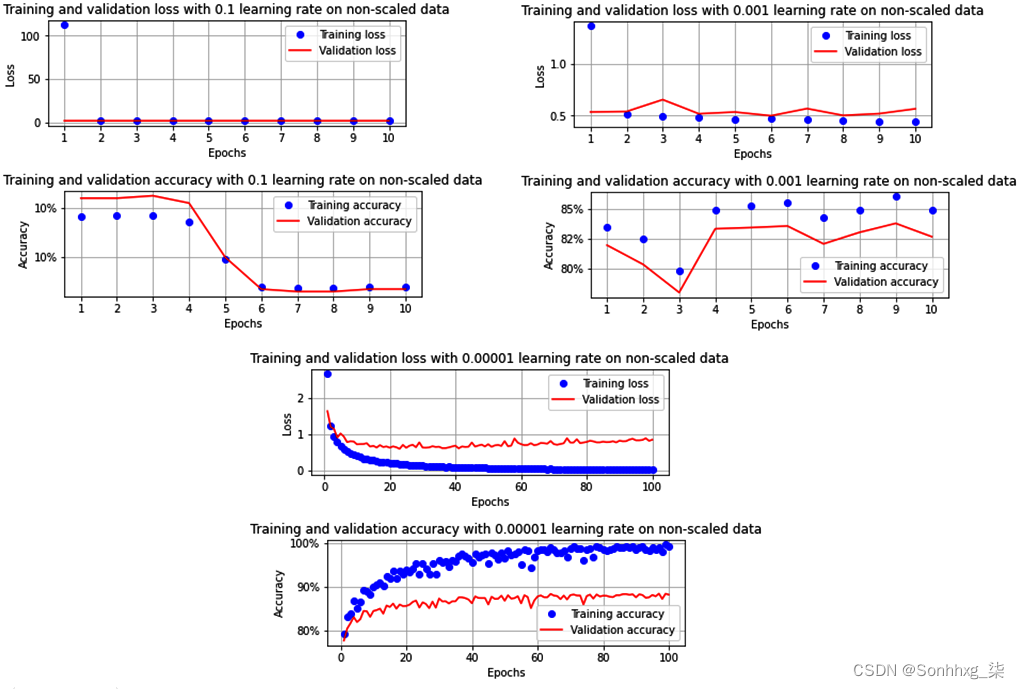
正如我们所看到的,即使数据集是非缩放的,当学习率为 0.1 时,我们也无法训练出准确的模型。此外,当学习率为 0.001 时,准确率没有上一节中的那么高。
最后,当学习率非常小时(0.00001)时,模型能够像前面几节一样学习,但这次在训练数据上过度拟合。让我们通过跨层的参数分布来理解为什么会发生这种情况,如下所示:
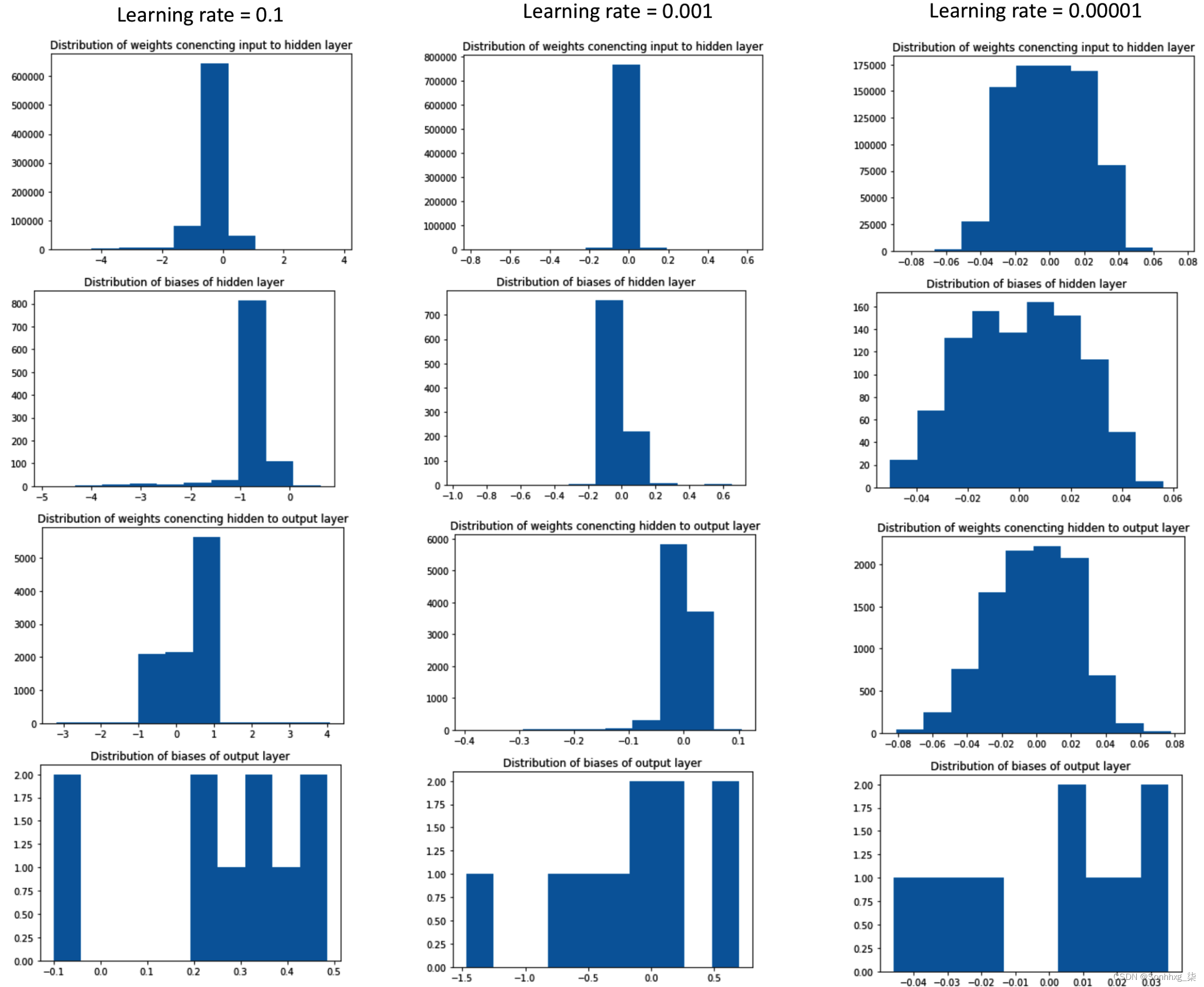
在这里,我们可以看到,与学习率高时相比,当模型精度高时(即学习率为 0.00001 时),权重的范围要小得多(在这种情况下通常在 -0.05 到 0.05 之间) .
由于学习率很小,因此可以将权重调整为较小的值。请注意,在非缩放数据集上学习率为 0.00001 的场景等价于在缩放数据集上学习率为 0.001 的场景。这是因为权重现在可以向一个非常小的值移动(因为梯度 * 学习率是一个非常小的值,因为学习率很小)。
既然我们已经确定,高学习率不太可能在缩放和非缩放数据集上产生最佳结果,在下一节中,我们将学习如何在模型开始过度拟合时自动降低学习率.
通常,0.001 的学习率是有效的。学习率非常低意味着训练模型需要很长时间,而学习率高会导致模型变得不稳定。
了解学习率热启动的影响
到目前为止,我们已经初始化了一个学习率,并且在训练模型时它在所有时期都保持不变。但是,最初,将权重快速更新到接近最佳的场景是很直观的。从那时起,它们应该非常缓慢地更新,因为最初减少的损失量很高,而在后来的时期减少的损失量会很低。
这要求最初具有高学习率,然后随着模型达到接近最佳的准确度逐渐降低它。这需要我们了解何时必须降低学习率。
我们可以解决这个问题的一种潜在方法是持续监控验证损失,如果验证损失没有减少(比如说,在之前的 x 个时期),那么我们降低学习率。
PyTorch 为我们提供了工具,当验证损失在之前的“x”个时期没有减少时,我们可以使用这些工具来降低学习率。在这里,我们可以使用lr_scheduler方法:
from torch import optim
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.5,patience=0,
threshold = 0.001,
verbose=True,
min_lr = 1e-5,
threshold_mode = 'abs')
在前面的代码中,我们指定如果某个值在接下来的 n 个时期(在本例中 n 为 0)没有提高a (在本例中为为 0.001)。最后,我们指定学习率(假设它减少了 0.5 倍)不能低于 1e-5,并且应该是绝对的,以确保超过 0.001 的最小阈值。 optimizer factor threshold min_lr threshold_mode
现在我们已经了解了调度器,让我们在训练我们的模型时应用它。
与前面的部分类似,所有代码都与Batch size of 32部分相同,除了此处显示的粗体代码,已添加用于计算验证损失:
from torch import optim
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.5, patience=0,
threshold = 0.001,
verbose=True,
min_lr = 1e-5,
threshold_mode = 'abs')
train_losses, train_accuracies = [], []
val_losses, val_accuracies = [], []
for epoch in range(30):
#print(epoch)
train_epoch_losses, train_epoch_accuracies = [], []
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
batch_loss = train_batch(x, y, model, optimizer, \
loss_fn)
train_epoch_losses.append(batch_loss)
train_epoch_loss = np.array(train_epoch_losses).mean()
for ix, batch in enumerate(iter(trn_dl)):
x, y = batch
is_correct = accuracy(x, y, model)
train_epoch_accuracies.extend(is_correct)
train_epoch_accuracy = np.mean(train_epoch_accuracies)
for ix, batch in enumerate(iter(val_dl)):
x, y = batch
val_is_correct = accuracy(x, y, model)
validation_loss = val_loss(x, y, model)
scheduler.step(validation_loss)
val_epoch_accuracy = np.mean(val_is_correct)
train_losses.append(train_epoch_loss)
train_accuracies.append(train_epoch_accuracy)
val_losses.append(validation_loss)
val_accuracies.append(val_epoch_accuracy)
在前面的代码中,我们指定只要验证损失在连续的时期内没有减少,就应该激活调度程序。在这些情况下,学习率会降低 0.5 倍当前学习率。
在我们的模型上执行此操作的输出如下:

让我们了解训练和验证数据集的准确性和损失值在增加的时期内的变化:
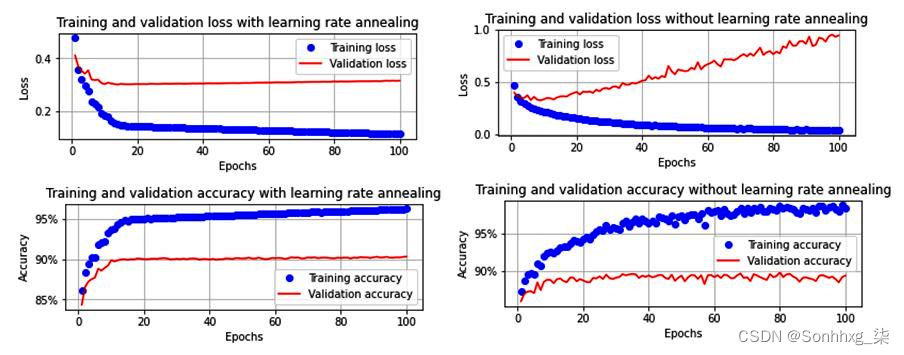
请注意,每当验证损失在增加的时期增加至少 0.001 时,学习率就会降低一半。这发生在第 5、8、11、12、13、15 和 16 时期。
此外,即使我们对模型进行了 100 个 epoch 的训练,我们也没有任何严重的过拟合问题。这是因为学习率变得如此之小,以至于权重更新非常小,导致训练和验证准确度之间的差距更小(与我们有 100 个 epoch 没有学习率退火的情况相比,训练准确度接近到 100%,而验证准确度接近 ~89%)。
到目前为止,我们已经了解了各种超参数对模型准确性的影响。在下一节中,我们将了解神经网络中的层数如何影响其准确性。
构建更深层次的神经网络
到目前为止,我们的神经网络架构只有一个隐藏层。在本节中,我们将对比有两个隐藏层和没有隐藏层(没有隐藏层是逻辑回归)的模型的性能。
一个网络中有两层的模型可以如下构建(请注意,我们将第二个隐藏层中的单元数设置为 1,000)。修改后的get_model函数(来自Batch size of 32部分的代码),其中有两个隐藏层,如下所示:
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Linear(1000, 1000),
nn.ReLU(),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
类似地,*没有隐藏层*的get_model函数如下:
def get_model():
model = nn.Sequential(
nn.Linear(28 * 28, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
请注意,在前面的函数中,我们将输入直接连接到输出层。
一旦我们像在Batch size of 32部分中那样训练模型,训练和验证数据集的准确度和损失将 如下所示:
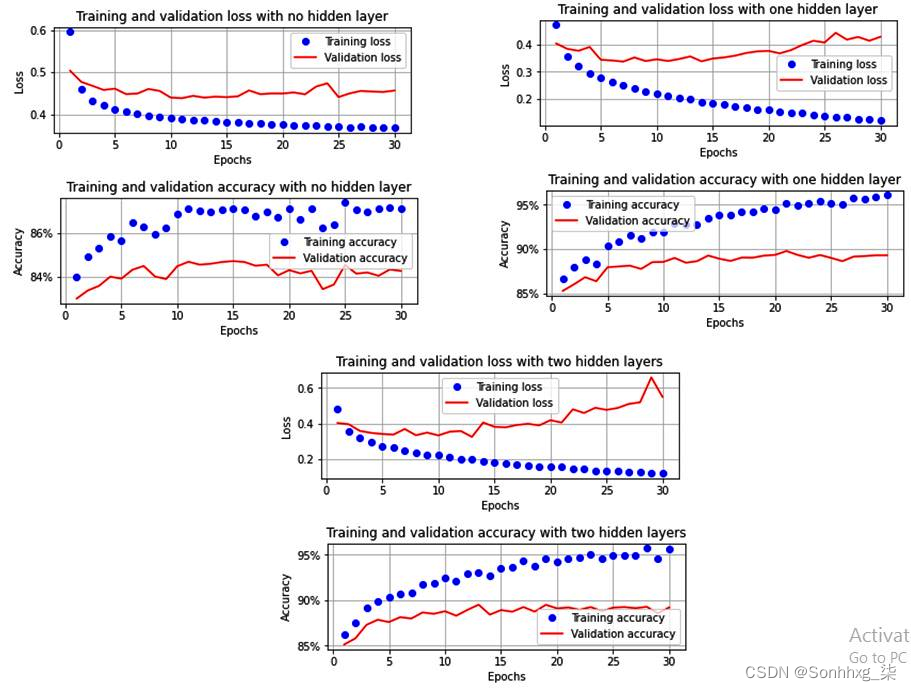
在这里,请注意以下几点:
- 当没有隐藏层时,模型无法学习。
- 与一个隐藏层相比,当有两个隐藏层时,模型的过度拟合量更大(与具有一层的模型相比,具有两层的模型中的验证损失更高)。
到目前为止,在不同的部分中,我们已经看到当输入数据没有缩放(缩小到一个小范围)时,模型无法很好地训练。由于矩阵乘法涉及获取隐藏层中节点的值,因此非缩放数据(具有更高范围的数据)也可能出现在隐藏层中(尤其是当我们有具有多个隐藏层的深度神经网络时)。在下一节中,我们将学习如何在中间层处理此类非缩放数据。
了解批量标准化的影响
之前我们了解到,当输入值很大时,当权重值发生较大变化时,Sigmoid 输出的变化并没有太大的区别。
现在,让我们考虑相反的情况,输入值非常小:
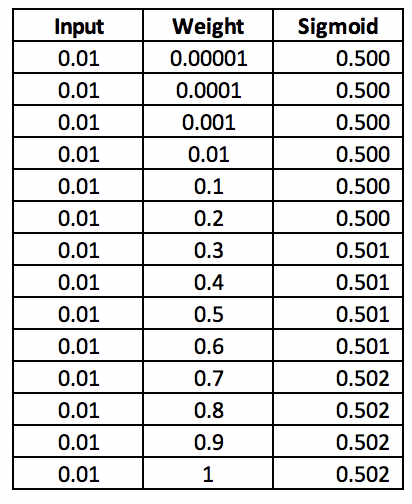
当输入值非常小时,Sigmoid 输出会发生轻微的变化,对权重值做出很大的改变。
此外,在缩放输入数据部分,我们看到大输入值对训练准确性有负面影响。这表明我们的输入既不能有非常小的值,也不能有非常大的值。
除了输入中的非常小或非常大的值外,我们还可能遇到隐藏层中一个节点的值可能导致非常小的数字或非常大的数字的情况,导致我们看到的相同问题之前的权重将隐藏层连接到下一层。
在这种情况下,批量标准化就派上用场了,因为它标准化了每个节点的值,就像我们缩放输入值时一样。
通常,批处理中的所有输入值都按 如下方式缩放:
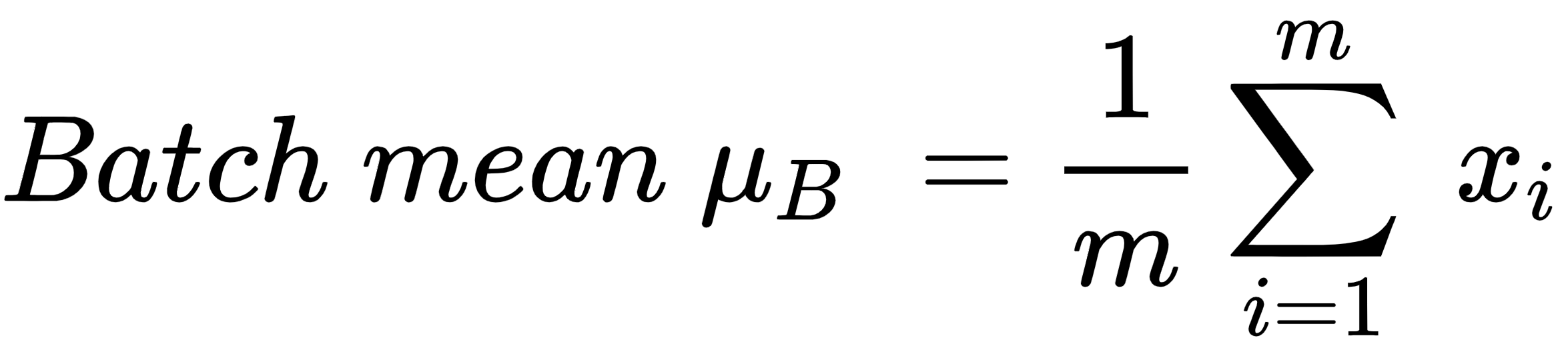

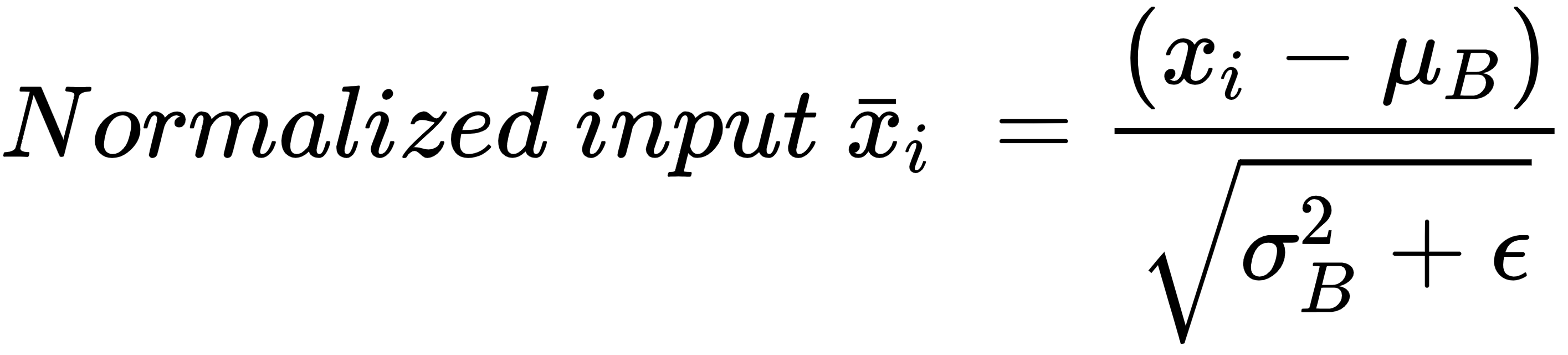
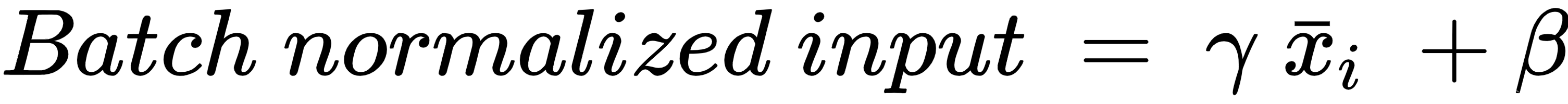
通过从批次均值中减去每个数据点,然后将其除以批次方差,我们将一个节点处批次的所有数据点归一化到一个固定范围。
虽然这被称为硬归一化,但通过引入 γ 和 β 参数,我们让网络识别最佳归一化参数。
要了解批量标准化过程如何提供帮助,让我们看一下以下场景中训练和验证数据集的损失和准确率值,以及隐藏层值的分布:
- 没有批量标准化的非常小的输入值
- 带有批量标准化的非常小的输入值
让我们开始吧!
没有批量标准化的非常小的输入值
到目前为止,当我们必须缩放输入数据时,我们将其缩放到 0 到 1 之间的值。在本节中,我们将进一步将其缩放到 0 到 0.0001 之间的值,以便我们了解缩放数据的影响。正如我们在本节开头所看到的,即使权重值变化很大,小的输入值也无法改变 Sigmoid 值。
为了缩放输入数据集以使其具有非常低的值,我们将通过将输入值的范围从 0 减少到 0.0001 来更改通常在类中执行的缩放,如下FMNISTDataset 所示:
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float()/(255*10000) # Done only for us to
# understand the impact of Batch normalization
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
请注意,在代码 ( x = x.float()/(255*10000)) 的粗体部分中,我们通过将输入像素值除以 10,000 缩小了输入像素值的范围。
接下来,我们必须重新定义函数,以便我们可以获取模型的预测以及隐藏层的值。我们可以通过指定一个神经网络类来做到这一点,如下所示: get_model
def get_model():
class neuralnet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Linear(784,1000)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(1000,10)
def forward(self, x):
x = self.input_to_hidden_layer(x)
x1 = self.hidden_layer_activation(x)
x2= self.hidden_to_output_layer(x1)
return x2, x1
model = neuralnet().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
在前面的代码中,我们定义了 neuralnet 类,它返回输出层值 (x2 ) 和隐藏层的激活值 (x1 )。请注意,网络的架构没有改变。
鉴于该函数现在返回两个输出,我们需要通过将输入传递给模型来修改和进行预测的函数。在这里,我们只会获取输出层的值,而不是隐藏层的值。鉴于输出层值位于模型返回的第 0个索引中,我们将修改函数,使其仅获取第 0个预测索引,如下所示: get_model train_batch val_loss
def train_batch(x, y, model, opt, loss_fn):
model.train()
prediction = model(x)[0]
batch_loss = loss_fn(prediction, y)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
def accuracy(x, y, model):
model.eval()
with torch.no_grad():
prediction = model(x)[0]
max_values, argmaxes = prediction.max(-1)
is_correct = argmaxes == y
return is_correct.cpu().numpy().tolist()
请注意,前面代码中的粗体部分是我们确保仅获取模型输出的第 0个 索引的地方(因为第 0个 索引包含输出层的值)。
*现在,当我们运行Scaling *the data部分中提供的其余代码时,我们将看到训练和验证数据集中的准确率和损失值在增加的时期内的变化如下:
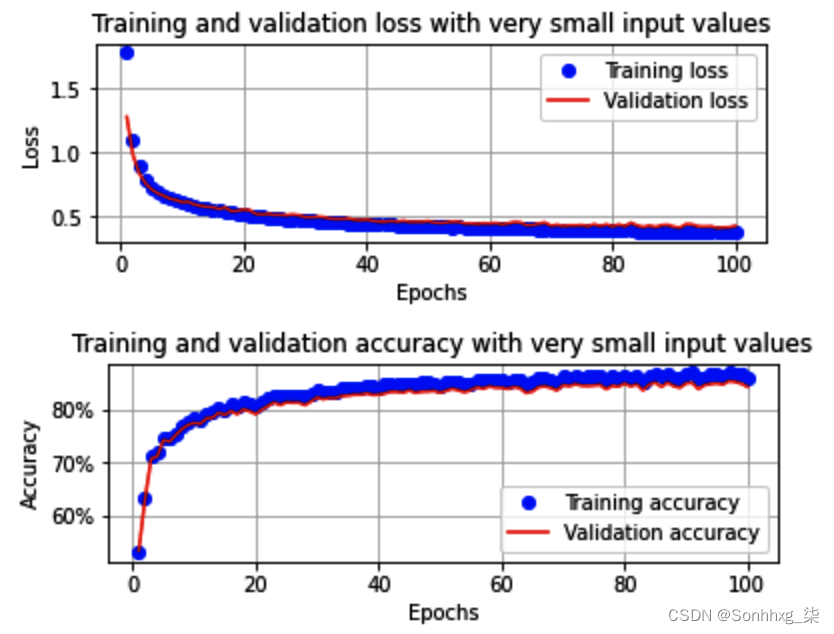
请注意,在前面的场景中,即使在 100 个 epoch 之后,模型也没有很好地训练(在前面的部分中,模型在 10 个 epoch 内的验证数据集上训练的准确度约为 90%,而当前模型只有 ~ 85% 的验证准确率)。
让我们通过探索隐藏值的分布以及参数分布来了解当输入值具有非常小的范围时模型不能很好地训练的原因:
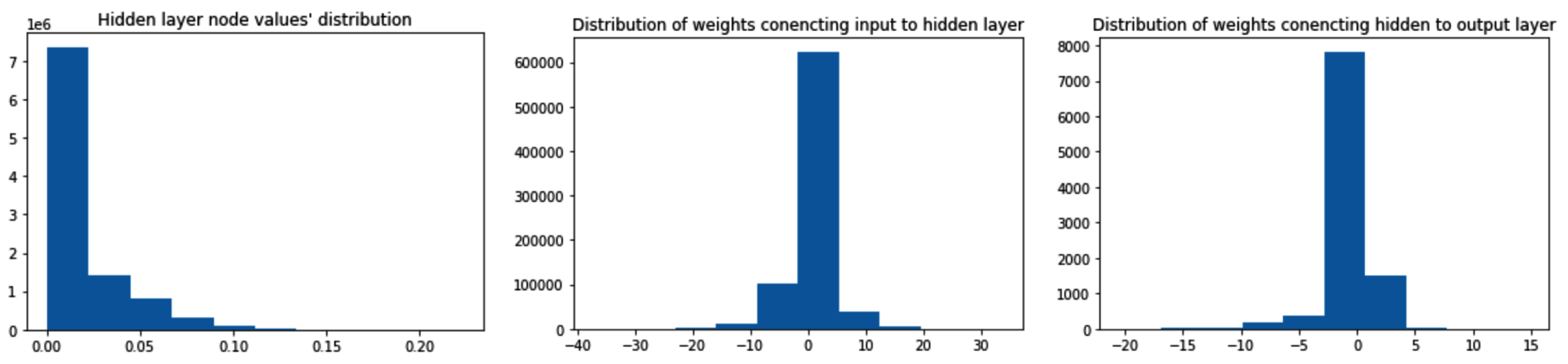
请注意,第一个分布表示隐藏层中值的分布(我们可以看到这些值的范围非常小)。此外,鉴于输入和隐藏层值的范围都非常小,权重必须有很大的变化(对于将输入连接到隐藏层的权重和连接隐藏层的权重到输出层)。
既然我们知道当输入值的范围非常小时,网络就不能很好地训练,让我们了解批量归一化如何帮助增加隐藏层内的值范围。
带有批量标准化的非常小的输入值
在本节中,我们只会对上一小节中的代码进行一次更改;也就是说,我们将在定义模型架构时添加批量标准化。
修改后的功能如下: get_model
def get_model():
class neuralnet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Linear(784,1000)
self.batch_norm = nn.BatchNorm1d(1000)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(1000,10)
def forward(self, x):
x = self.input_to_hidden_layer(x)
x0 = self.batch_norm(x)
x1 = self.hidden_layer_activation(x0)
x2= self.hidden_to_output_layer(x1)
return x2, x1
model = neuralnet().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
请注意,在前面的代码中,我们声明了一个batch_norm执行批量标准化 ( ) 的变量 ( nn.BatchNorm1d)。我们执行的原因nn.BatchNorm1d(1000)是因为每个图像的输出维度为 1,000(即隐藏层的一维输出)。
此外,在该方法中,我们在 ReLU 激活之前通过批量归一化传递隐藏层值的输出。 forward
训练和验证数据集的准确率和损失值随时间增加的变化如下:
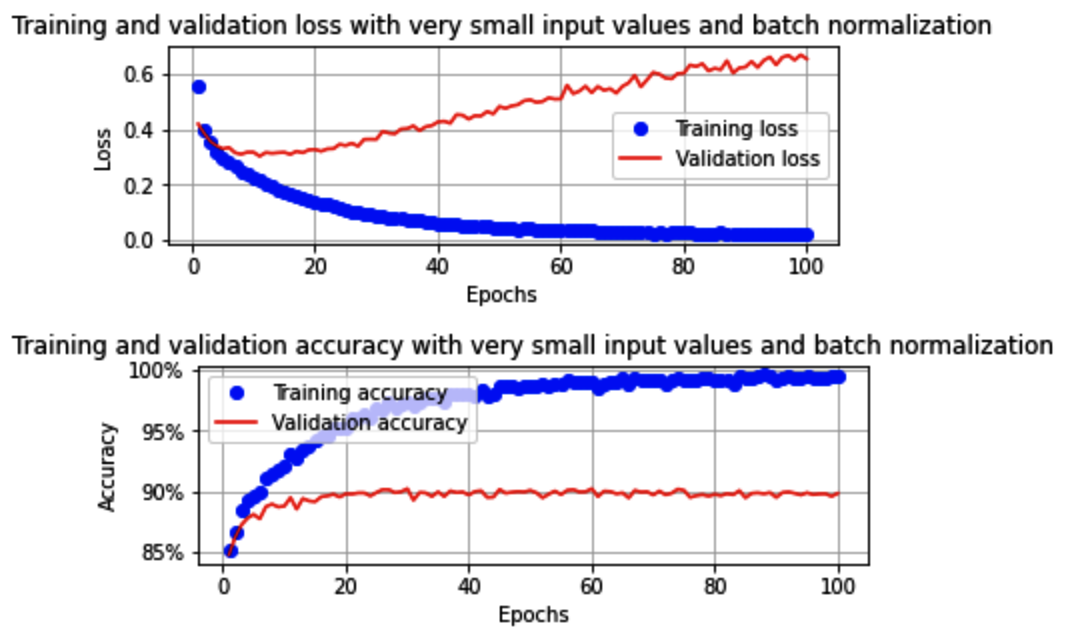
在这里,我们可以看到模型的训练方式与输入值范围不是很小时的训练方式非常相似。
让我们了解隐藏层值的分布和权重分布,如上一节所示:
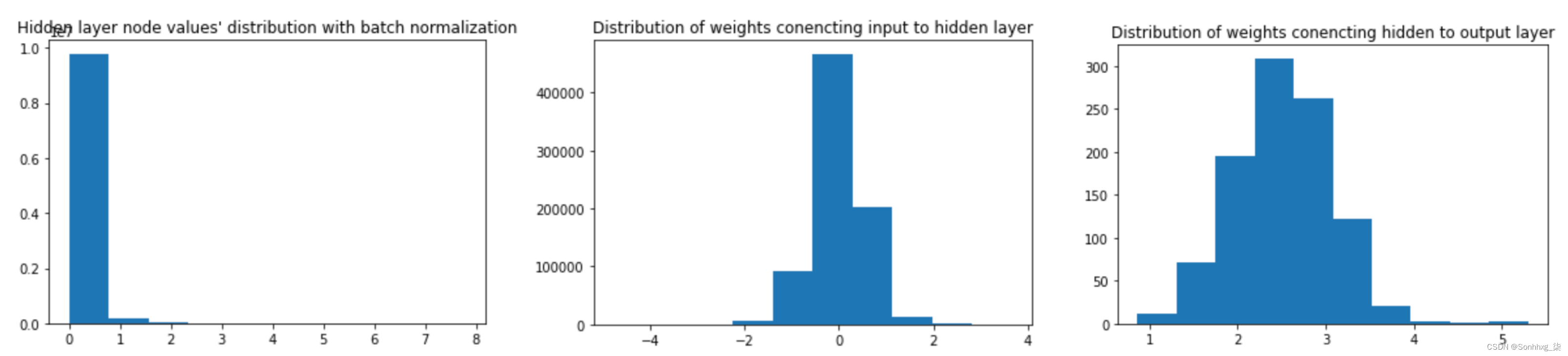
在这里,我们可以看到,当我们进行批量归一化时,隐藏层值的分布更大,而连接隐藏层和输出层的权重分布更小。模型学习的结果与前几节一样有效。
批量归一化在训练深度神经网络时有很大帮助。它帮助我们避免梯度变得太小以至于权重几乎没有更新。
请注意,在前面的场景中,我们比根本没有批量标准化时更快地获得了高验证准确度。这可能是对中间层进行归一化的结果,从而减少了权重发生饱和的机会。但是,过拟合的问题还有待解决。我们接下来会看看这个。
过拟合的概念
到目前为止,我们已经看到训练数据集的准确率通常超过 95%,而验证数据集的准确率约为 89%。
从本质上讲,这表明该模型在未见数据集上的泛化程度不高,因为它可以从训练数据集中学习。这也表明模型正在学习训练数据集的所有可能的边缘情况;这些不能应用于验证数据集。
在训练数据集上具有高准确度而在验证数据集上具有相当低的准确度是指过度拟合的情况。
用于减少过度拟合影响的一些典型策略如下:
- Dropout
- Regularization
我们将在以下部分中了解它们的影响。
添加 dropout 的影响
我们已经了解到,无论何时计算,都会发生权重更新。通常,我们在网络中有数十万个参数和数千个数据点来训练我们的模型。这使我们有可能虽然大多数参数有助于合理地训练模型,但某些参数可以针对训练图像进行微调,从而导致它们的值仅由训练数据集中的少数图像决定。反过来,这会导致训练数据具有高精度,但验证数据集不能泛化。 loss.backward()
Dropout 是一种随机选择指定百分比的激活并将其降至 0 的机制。在下一次迭代中,另一组随机隐藏单元被关闭。这样,神经网络不会针对边缘情况进行优化,因为网络没有太多机会调整权重来记忆边缘情况(假设权重在每次迭代中都没有更新)。
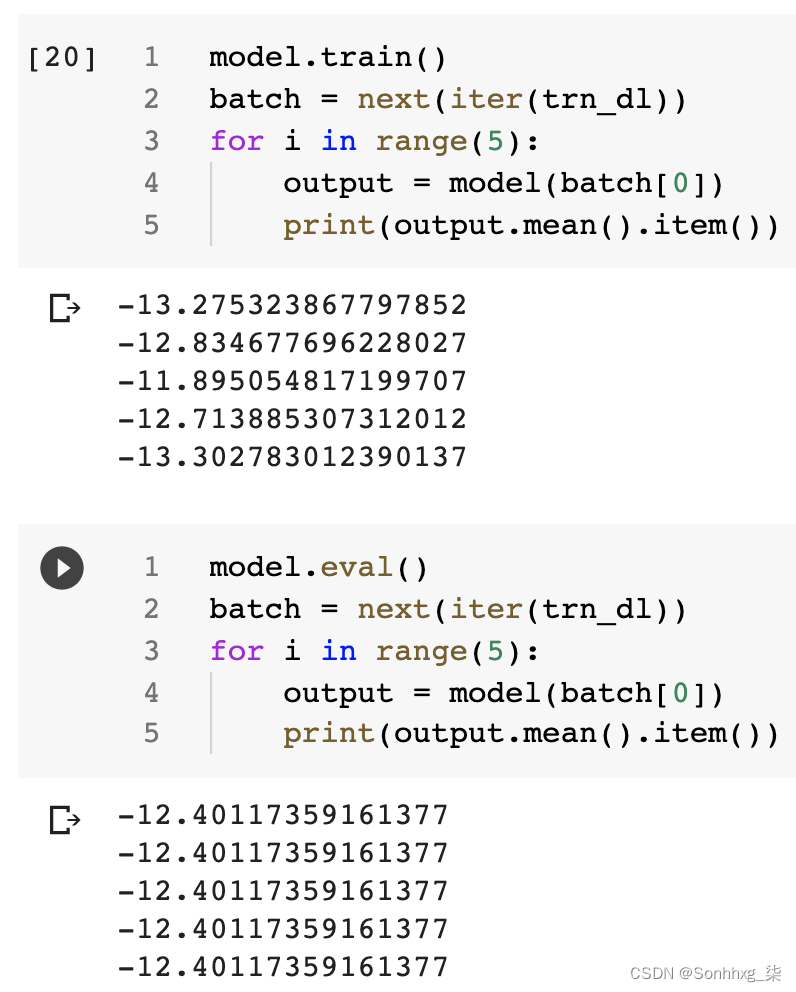
请注意,在预测期间,不需要应用 dropout,因为这种机制只能应用于经过训练的模型。此外,权重将在预测(评估)期间自动缩小,以调整权重的大小(因为所有权重都在预测期间存在)。
通常,在训练和验证过程中层的行为会有所不同——正如您在 dropout 的情况下看到的那样。出于这个原因,您必须使用以下两种方法之一预先指定模型的模式—— model.train()让模型知道它处于训练模式并model.eval()让它知道它处于评估模式。如果我们不这样做,我们可能会得到意想不到的结果。例如,在下图中,请注意模型(包含 dropout)在训练模式下如何为我们提供对相同输入的不同预测。但是,当同一个模型处于 eval 模式时,它会抑制 dropout 层并返回相同的输出:
在定义架构时,在get_model函数中指定 Dropout如下:
def get_model():
model = nn.Sequential(
nn.Dropout(0.25),
nn.Linear(28 * 28, 1000),
nn.ReLU(),
nn.Dropout(0.25),
nn.Linear(1000, 10)
).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
请注意,在前面的代码中,Dropout是在线性激活之前指定的。这指定不会更新线性激活层中固定百分比的权重。
一旦模型训练完成,如Batch size of 32部分,训练和验证数据集的损失和准确度值将如下所示:
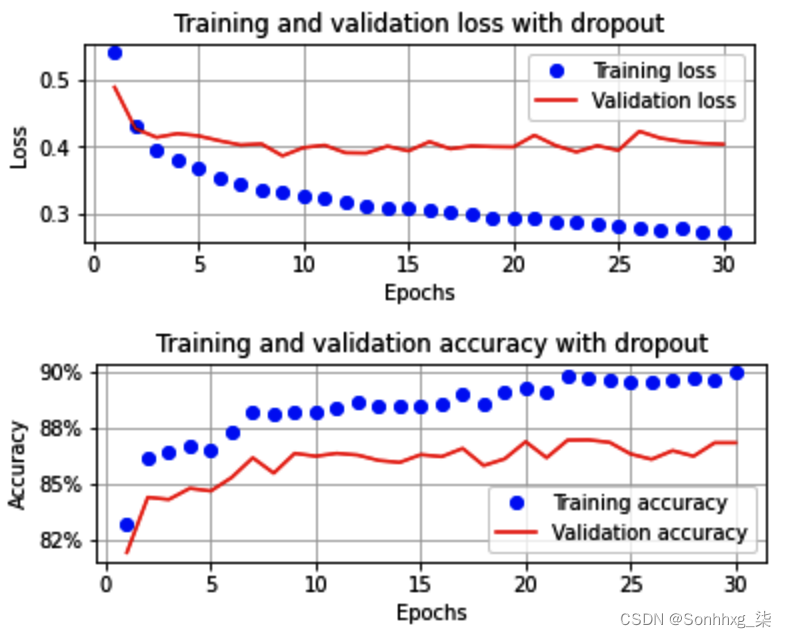
请注意,在前面的场景中,训练数据集和验证数据集的准确度之间的差异没有我们在前面的场景中看到的那么大,因此导致场景的过度拟合较少。
正则化的影响
除了训练准确率远高于验证准确率外,过拟合的另一个特征是某些权重值会远高于其他权重值。高权重值可能是模型在训练数据上学习得很好(本质上是对所见内容的烂学习)的症状。
虽然 dropout 是一种用于不频繁更新权重值的机制,但正则化是我们可以用于此目的的另一种机制。
正则化是一种我们惩罚具有高权重值的模型的技术。因此,它是一个双重目标函数——最小化训练数据的损失以及权重值。在本节中,我们将学习两种类型的正则化:
- L1 正则化
- L2 正则化
让我们开始吧!
L1 正则化
L1 正则化计算 如下:
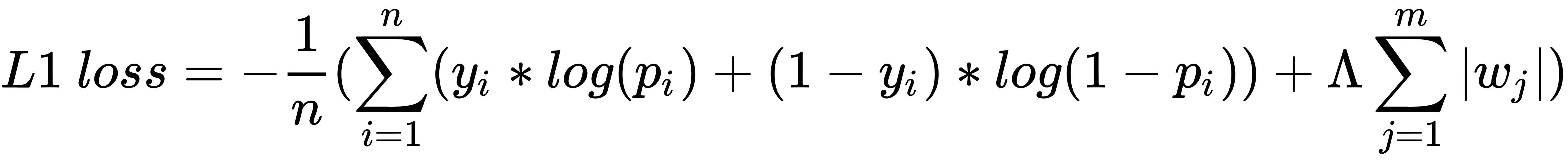
上述公式的第一部分是指我们迄今为止一直用于优化的分类交叉熵损失,而第二部分是指模型的权重值的绝对和。
请注意,L1 正则化通过将权重的绝对值合并到损失值计算中来确保它惩罚权重的高绝对值。
 指的是我们与正则化(权重最小化)损失相关联的权重。
指的是我们与正则化(权重最小化)损失相关联的权重。
L1 正则化在训练模型的同时进行,如下:
def train_batch(x, y, model, opt, loss_fn):
model.train()
prediction = model(x)
l1_regularization = 0
for param in model.parameters():
l1_regularization += torch.norm(param,1)
batch_loss = loss_fn(prediction, y)+0.0001*l1_regularization
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
在前面的代码中,我们通过初始化对所有层的权重和偏差进行了正则化 l1_regularization.
torch.norm(param,1) 提供跨层的权重和偏差值的绝对值。
此外,我们有一个非常小的权重 ( 0.0001) 与跨层参数的绝对值之和相关联。
一旦我们执行剩余的代码,如在32 的 Batch size部分中,训练和验证数据集在增加 epoch 上的损失和准确度值将如下所示:
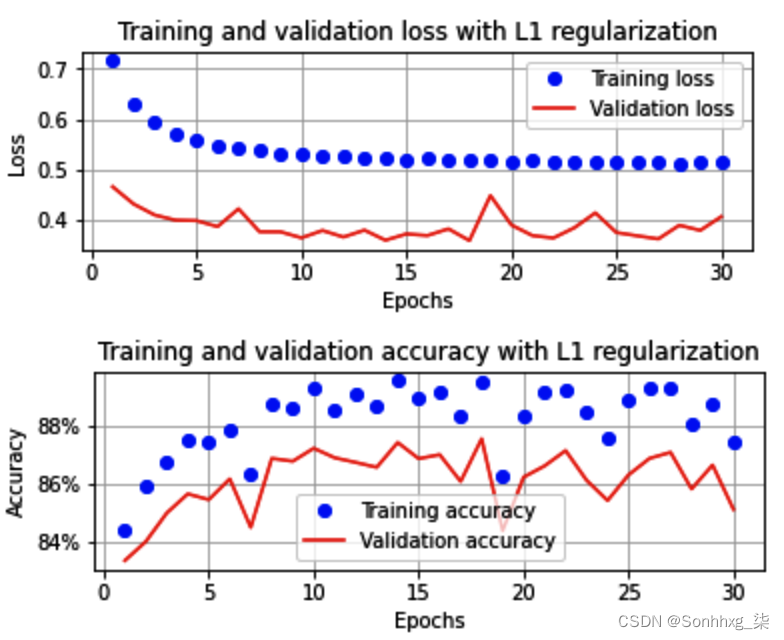
在这里,我们可以看到训练数据集和验证数据集的准确度差异没有没有 L1 正则化时那么高。
L2 正则化
L2正则化计算如下:
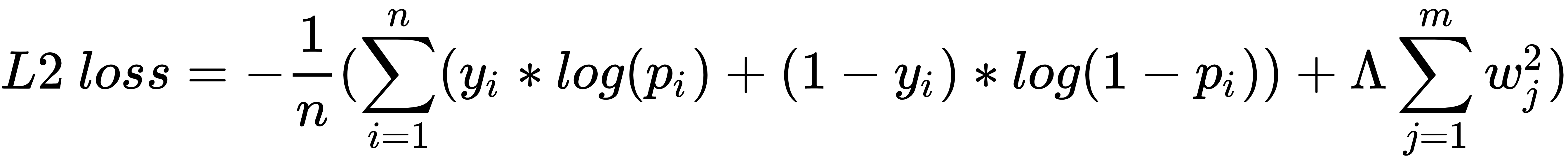
上式的第一部分是指得到的分类交叉熵损失,而第二部分是指模型权重值的平方和。
与 L1 正则化类似,我们通过将权重的平方和纳入损失值计算来惩罚高权重值。
指的是我们与正则化(权重最小化)损失相关联的权重。
L2 正则化在训练模型时实现如下:
def train_batch(x, y, model, opt, loss_fn):
model.train()
prediction = model(x)
l2_regularization = 0
for param in model.parameters():
l2_regularization += torch.norm(param,2)
batch_loss = loss_fn(prediction, y) + 0.01*l2_regularization
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
请注意,在前面的代码中,正则化参数 (0.01) 略高于 L1 正则化,因为权重通常在 -1 到 1 之间,并且它们的平方会导致更小的值。将它们乘以更小的数字,就像我们在 L1 正则化中所做的那样,将导致我们在整体损失计算中对正则化的权重非常小。
一旦我们执行剩余的代码,如在32 的 Batch size部分中,训练和验证数据集在增加 epoch 上的损失和准确度值将如下所示:
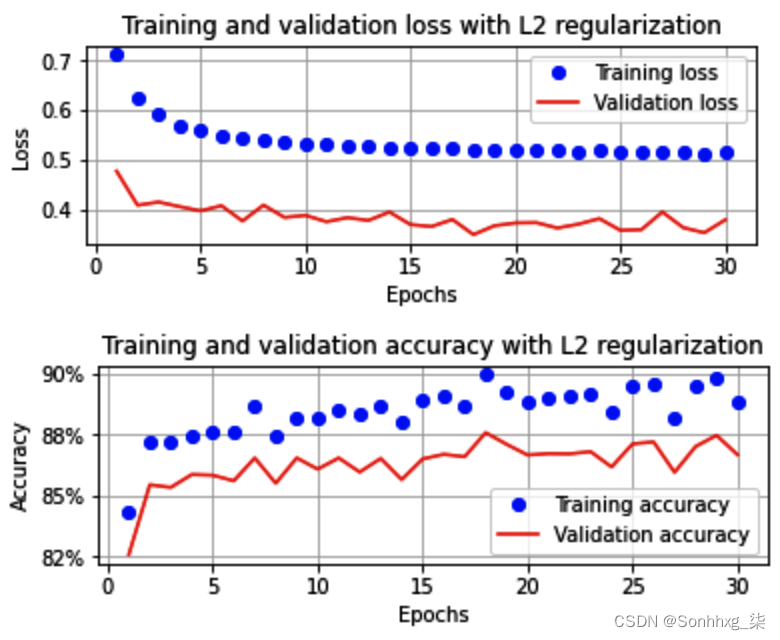
在这里,我们可以看到 L2 正则化也导致验证和训练数据集的准确性和损失值彼此接近。
最后,让我们比较没有正则化和 L1/L2 正则化的权重值,以便我们可以验证我们的理解,即在记忆边缘情况的值时,某些权重会有很大差异。我们将通过跨层的权重分布来做到这一点,如下图所示:
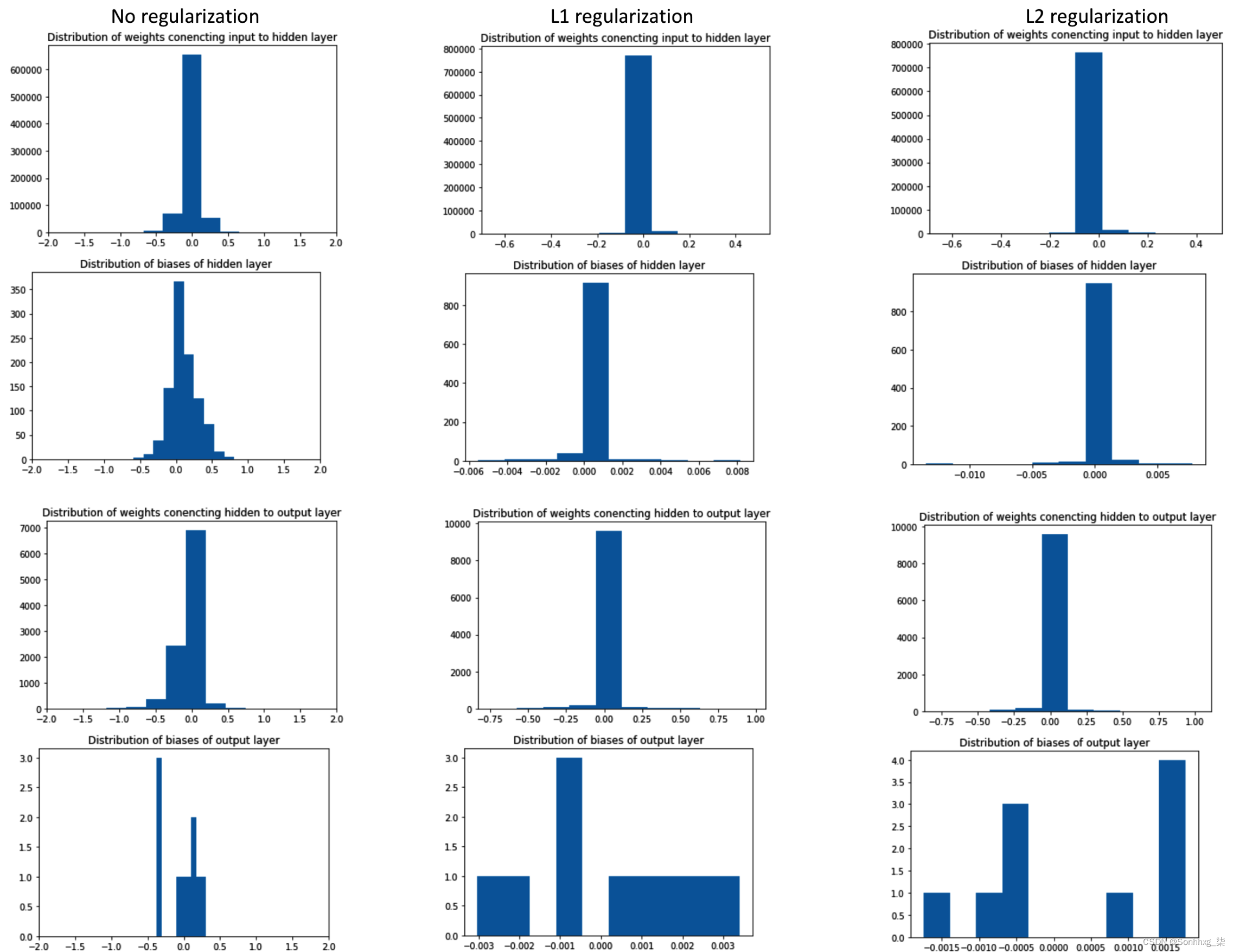
在这里,我们可以看到,与不执行正则化相比,执行 L1/L2 正则化时参数的分布非常小。这可能会减少为边缘情况更新权重的机会。
概括
我们从学习如何表示图像开始本章。接下来,我们了解了缩放、学习率的值、我们选择的优化器以及批量大小如何帮助提高训练的准确性和速度。然后,我们了解了批量归一化如何帮助提高训练速度并解决隐藏层中值非常小或大的问题。接下来,我们了解了如何安排学习率以进一步提高准确性。然后我们开始理解过拟合的概念,并了解了 dropout 和 L1 和 L2 正则化如何帮助我们避免过拟合。
现在我们已经了解了使用深度神经网络进行图像分类,以及帮助训练模型的各种超参数,在下一章中,我们将了解本章所学的内容如何失败以及如何解决这使用卷积神经网络。
问题
- 如果输入值未在输入数据集中进行缩放,会发生什么情况?
- 如果在训练神经网络时背景是白色像素颜色而内容是黑色像素颜色,会发生什么情况?
- 批量大小对模型的训练时间以及给定数量的 epoch 的准确性有什么影响?
- 输入值范围对训练结束时的权重分布有什么影响?
- 批量标准化如何帮助提高准确性?
- 我们如何知道模型是否在训练数据上过度拟合?
- 正则化如何帮助避免过度拟合?
- L1 和 L2 正则化有何不同?
- dropout 如何帮助减少过拟合?
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。