BERT详解
主要介绍了什么是Bert模型,它的优点,输入输出和预训练方法。
将AI和机器学习集成到Serverless架构中:API和数据处理
作者:禅与计算机程序设计艺术 Serverless是一种新的软件开发模型,其主要特点在于只需关注业务逻辑,而不用关心底层基础设施相关的问题。这种部署模式可以让开发者更专注于产品功能的实现,从而提升效率、降低运营成本。Serverless架构通过云服务商提供的各种
【人工智能的数学基础】利普希茨连续条件(Lipschitz Continuity Condition)
利普希茨连续条件(Lipschitz Continuity Condition)是一个比一致连续更强的函数光滑性条件。该条件限制了函数改变的速度,即符合Lipschitz连续条件的函数的斜率必小于一个依函数而定的Lipschitz常数。一般地,一个实值函数fxf(x)fx是KKK阶Lipschitz
语言模型(language model)
语言模型是一种用于预测文本序列中下一个词或字符的概率分布的模型。它可以捕获语言结构的某些方面,如语法、句式和上下文信息。传统的语言模型通常使用N-gram方法或隐藏马尔可夫模型,但这些模型往往不能捕捉到长距离依赖和复杂的语义信息。
NLP-语义解析(Text2SQL):技术路线【Seq2Seq、模板槽位填充、中间表达、强化学习、图网络】
结合预训练模型、语义匹配的方法,该方法以表格内容作为预训练语料,结合语义匹配任务目标输入数据库Schema,从而选中需要的列,例如:BREIDGE、GRAPPA等。
【代码笔记】Transformer代码详细解读
Transformer代码详细解读
Word2Vec详解
Word2Vec详解
人工智能大模型和数据中台结合,实现“智能数据中台”的AI时代的数字化解决方案
在当今数字化时代,企业面临着海量数据的挑战,如何高效地管理和利用这些数据成为了企业发展的关键。数据中台是解决这一问题的重要手段,它可以等方面的工作,实现。而的出现,为数据中台的发展带来了新的机遇和挑战。本文将介绍人工智能大模型和数据中台的结合,探讨如何实现“”的数字化解决方案。
T5模型简单介绍
谷歌公司的研究人员提出的T5(Text-to-Text Transfer Transformer,有5个T开头的单词,所以叫做T5)模型采用了一种与前述模型截然不同的策略:将不同形式的任务统一转化为条件式生成任务。
自然语言处理系列(一)入门概述
让小白也能轻松入门自然语言处理成为领域大神的专栏。该专栏介绍包括分词、词性分析、语义理解、命名实体识别、依存文法分析和句法分析等核心技术,以及智能问答系统、文本生成、机器翻译、情感分析和文本主题分类等应用场景。不仅有理论基础更有有多个实战案例以及代码详解。.........
什么是GPT模型,GPT下载和国内镜像
什么是GPT模型,GPT模型是通过预训练的方式,采用无监督学习方式,大量语料输入,经过多次训练后得到模型。它能够自动学习并理解自然语言中的语义、句法和语法信息,并可以用于文本生成、对话系统、情感分析、机器翻译等自然语言处理任务中。今天聊聊GPT国内镜像和GPT怎么下载。
全球&中国 AI 大模型 ( LLM ) 列表
AI 大模型(Large Language Model,简称LLM)是一种人工智能技术,通过深度学习算法训练大规模数据集来生成自然语言文本(如文章、对话等)。该技术的应用范围非常广泛,包括自然语言处理、机器翻译、文本生成、问答系统等。目前,AI 大模型已成为人工智能领域的一个热点,引起了各界的广泛关
在消费级GPU调试LLM的三种方法:梯度检查点,LoRA和量化
LLM的问题就是权重参数太大,无法在我们本地消费级GPU上进行调试,所以我们将介绍3种在训练过程中减少内存消耗,节省大量时间的方法:梯度检查点,LoRA和量化。
提示词工程师入门 百度文心Prompt课之十大技巧(适用所有AI大模型)
现在模型基本没有记忆功能,所以他会总结前面的对话,然后再发送给大模型,所以看起来大模型有记忆能力,但是因为发送给大模型的长度是有限的,所以输入时间久了之后就会看起来大模型好像失忆了,实际上是大模型的记忆长度达到上限,总结前面话语时遗失了重要信息。因为大模型加入了学习思维链的数据,所以类似教小孩一样”
人工智能LLM大模型:让编程语言更加支持自然语言处理
作者:禅与计算机程序设计艺术 人工智能LLM大模型:让编程语言更加支持自然语言处理作为人工智能的核心技术之一,自然语言处理 (Natural Language Processing, NLP) 已经在各个领域得到了广泛应用,如智能客服、智能翻译、文本分类等
A30、V100性能测试对比报告
共压80000数据,同时请求500数据。
推荐一个最近刚出的比较全面的多模态综述:Multimodal Deep Learning
多模态综述:Multimodal Deep Learning。对多模态、CV 和 NLP 领域中一些任务的 数据集、模型、评价指标等等 都做了较详细的介绍和总结。是个非常不错的综述,内容较全面且详细。
transformers库中的.from_pretrained()
Transformers库中的预训练模型加载函数.from_pretrained()
【论文速递】EMNLP2022-随机模态缺失情况下的多模态情感分析
论文速递-EMNLP2022-EMMR:Mitigating Inconsistencies in Multimodal Sentiment Analysis under Uncertain Missing Modalities
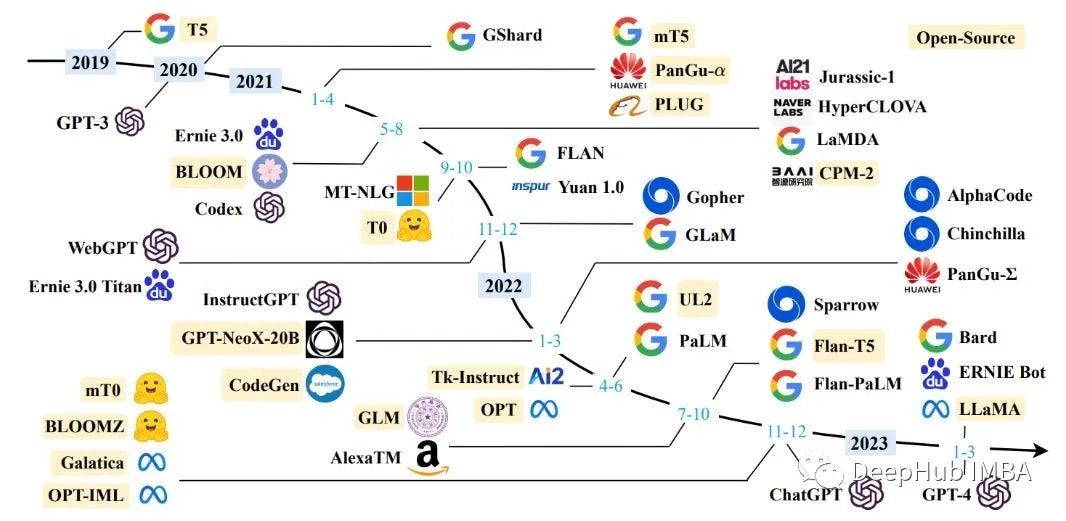
2023年发布的25个开源大型语言模型总结
本文总结了当前可用的开源llm的全部(几乎全部)列表,以及有关其许可选项和源代码存储库的信息,希望对你有所帮助



