
LLM的问题就是权重参数太大,无法在我们本地消费级GPU上进行调试,所以我们将介绍3种在训练过程中减少内存消耗,节省大量时间的方法:梯度检查点,LoRA和量化。
梯度检查点
梯度检查点是一种在神经网络训练过程中使动态计算只存储最小层数的技术。
为了理解这个过程,我们需要了解反向传播是如何执行的,以及在整个过程中层是如何存储在GPU内存中的。
1、前向和后向传播的基本原理
前向传播和后向传播是深度神经网络训练的两个阶段。
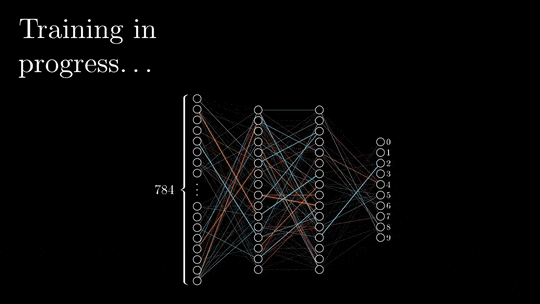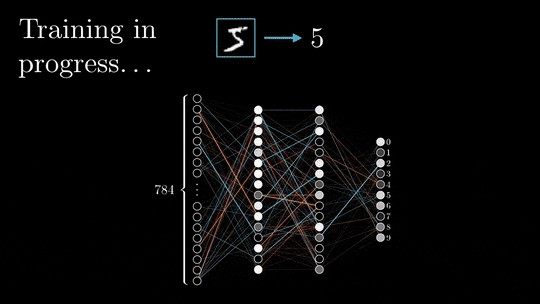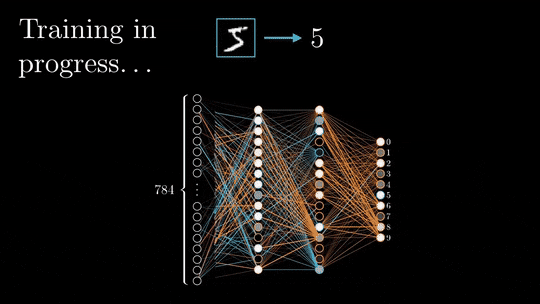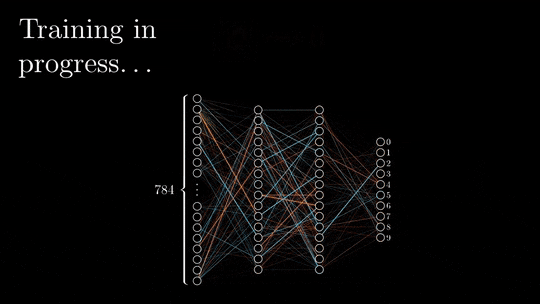
在前向传递过程中,输入被矢量化(将图像转换为像素,将文本转换为嵌入),并且通过一系列线性乘法和激活函数(如sigmoid或ReLU等非线性函数)在整个神经网络中处理每个元素。
神经网络的输出,被称为头部,被设计用来产生期望的输出,例如分类或下一个单词预测。然后将矢量化的预测结果与预期结果进行比较,并使用特定的损失函数(如交叉熵)计算损失。
基于损失值,以最小化损失为目标更新每层的权值和偏差。这个更新过程从神经网络的末端开始并向起点传播。
上面就是一个简单的过程,下面才是我们主要关注的:计算是如何存储在内存中的。
2、减少存储数量
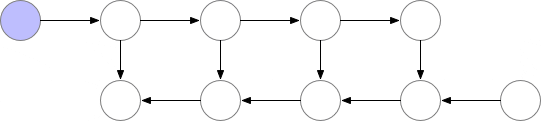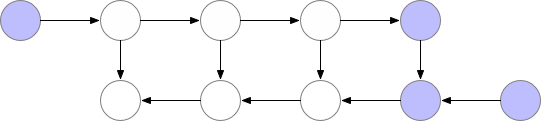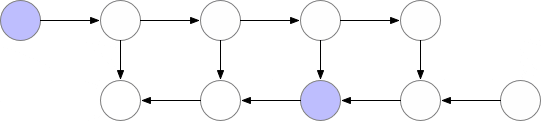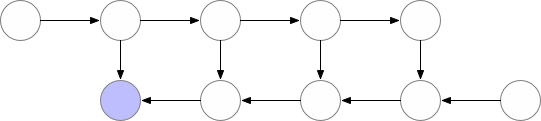
一种简单的方法是只保留反向传播所需的基本层,并在它们的使用完成后从内存中释放它们。
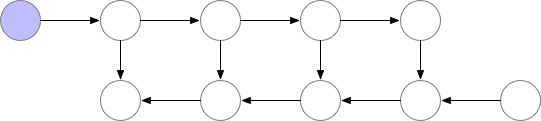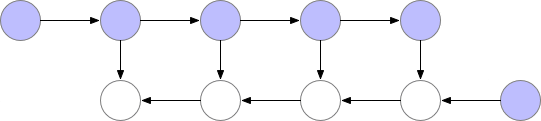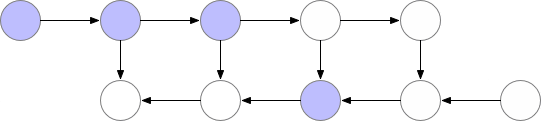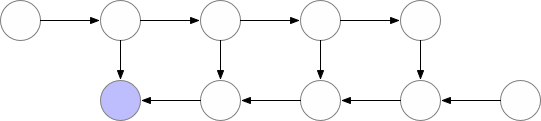
从上图可以看出,同时存储在内存中的层的最大数量并不是最优的。所以我们需要找到一种方法,在保持反向传播工作的同时,在内存中存储更少的元素。
3、减少计算时间
减少内存占用的一种方法是在神经网络开头的反向传播过程中重新计算每一层。
但是在这种情况下,计算时间会明显增加,使得训练在大模型的情况下不可行。
4、优化计算和内存梯度检查点
该技术通过保存“检查点”以计算反向传播期间“丢失”的层。该算法不是从头开始计算层,如前面的示例所示,而是从最近的检查点开始计算。

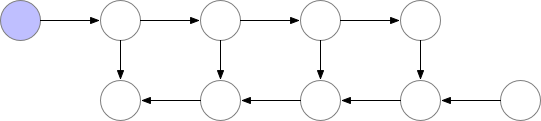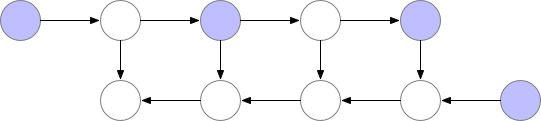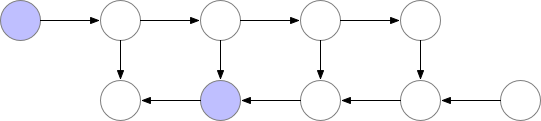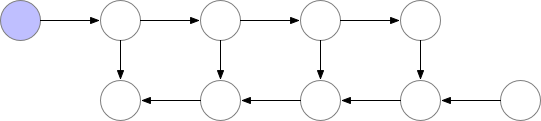
平衡内存存储和计算时间的最佳策略是设置O(sqrt(n))个检查点,层数为n。这样,一次反向传播计算的额外计算次数将对应于一次额外的前反向传播。
这种技术可以在较小的gpu上训练较大的模型,但代价是需要额外的计算时间(约20%)。
5、如何实现梯度检查点
transformer库已经提供了梯度检查点技术。
from transformers import AutoModelForCausalLM, TraininArguments
model = AutoModelForCausalLM.from_pretrained(
model_id,
use_cache=False, # False if gradient_checkpointing=True
**default_args
)
model.gradient_checkpointing_enable()
LoRA
LoRA是微软团队开发的一种技术,用于加速大型语言模型的微调。他们在GPT-3 175B上实施了这种方法,并大大减少了训练参数的数量。

他们的方法冻结预训练模型的所有参数,并将新的可训练参数嵌入到transformer架构中的特定模块中,如注意力模块(查询、键、值,但也适用于其他模块)。
为了实现这些适配器,他们利用线性层,如下面的等式所示,其中x (dimension: d)和h (dim: k)作为乘法前后的层,Wo作为预训练的权重,B和A作为新的权重矩阵。
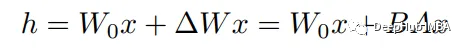
矩阵B和A的维数分别为(d × r)和(r × k),且r << min(d, k)。
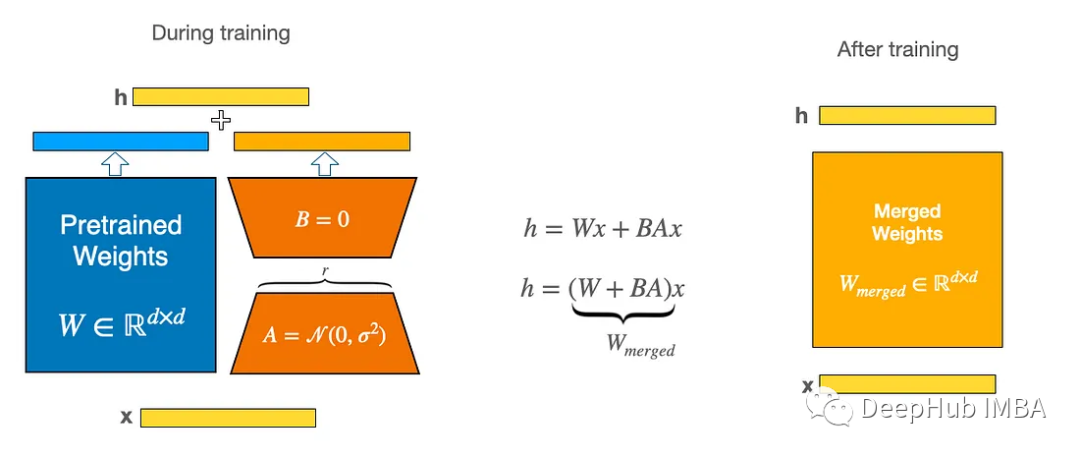
也就是说在不使训练过程复杂化的情况下,将新的密集层添加到现有的层上。在微调过程中,权重矩阵BA初始化为0,并遵循α/r的线性尺度,α为常数。当使用Adam算法优化权重时,α与学习率大致相同。
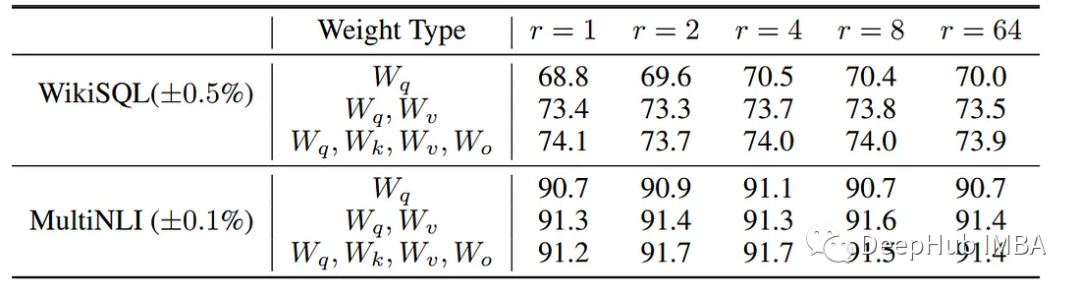
对不同的LoRA配置进行了测试,论文得出的结果是,将r=8(或更高)应用于各种模块的性能最好。
一旦对LoRA模型进行了微调,就可以将权重合并在一起以获得单个模型,或者只单独保存适配器,并将预训练模型与现有模型分开加载。
Hugging Face开发的PEFT库,可以利用LoRA技术。
from peft import LoraConfig, TaskType
lora_config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["query_key_value"]
lora_dropout=0.1,
bias="none",
task_type=TaskType.CAUSAL_LM,
)
还可以针对transformer架构中的所有密集层:
# From https://github.com/artidoro/qlora/blob/main/qlora.py
def find_all_linear_names(args, model):
cls = torch.nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
然后就是将“初始化”适配器添加到预训练模型中。
from transformers import AutoModelForCausalLM
from peft import get_peft_model
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_model = get_peft_model(model, peft_config)
lora_model.print_trainable_parameters()
训练完成后,可以单独保存适配器,也可以将它们合并到模型中。
# Save only adapaters
lora_model.save_pretrained(...)
# Save merged model
merged_model = lora_model.merge_and_unload()
merged_model.save_pretrained(...)
量化
谈到LoRA,我就还需要说一下量化。这两种技术在论文QLORA得到了高效的融合,并且已经通过bitsandbytes、peft和accelerayte整合到了Hugging Face 的transformer中。
1、什么是量化?
量化是一种技术,可以降低元素的精度,但不会失去元素的整体意义。例如在图片的情况下,量化包括减少像素的数量,同时保持图像的一个体面的分辨率。

上图肉眼基本看不出区别,但是存储空间却少了很多。在解释量化之前,需要了解计算机如何表示数字的
2、浮点数基本原理

计算机是二进制的,这意味着它们只通过0和1交换信息。为了表示数字,科学家设计了一种称为浮点格式的特殊系统,它允许计算机理解大范围的数值。最常见的表示形式是单精度浮点格式,由32位组成(1位= 0或1)。
除此以外还存在各种格式,例如半精度(16位)或双精度(64位)。简而言之,使用的比特数越多,可以容纳的数字范围就越广。
像GPT-3.5或Bloom-175B这样的模型非常大。在FP32格式中,这将表示:
175*10⁹. 4字节= 700Gb,半精度为350Gb,基本不可能加载到GPU内存中,那么我们如何缩小这些模型呢?
3、从FP32到Int8
Int8表示[- 127,127]之间的任何数字。
我们想将一个浮点数向量简化为Int8格式:
v = [-1.2, 4.5, 5.4, -0.1]
我们需要做的是定义v的最大值(这里是5.4),并将所有数字缩放到Int8[- 127,127]的范围内。所以需要计算系数
α = 127 / max(v) = 127 / 5.4 ~ 23.5
然后把v中的所有数乘以α,然后四舍五入,得到:
α.v = [-28, 106, 127, -2]
如果想去量化这个向量,只需要做相反的操作,就能够得到初始向量!
v = [-1.2, 4.5, 5.4, -0.1]
可以看到量化和反量化不会丢失任何信息。但实际上在四舍五入每个值时确实会失去精度。然而,在这个特定的例子中差异并不大,因为我们决定只用一个小数来表示数字,另外就是对于大模型来说,参数相互很大,之间也有关系,所以四舍五入的精度丢失不会对模型的结果产生很大的影响(是不产生很大影响,不是没影响),为了节省内存丢失一些小小的精度还是可以接受的。
那么,如果有异常值存在会发生什么?假设我们现在有这个向量:
v’ = [-1.2, 70, 5.4, -0.1]
目前的最高数字是70,这可以被视为一个异常值。如果我们重现完全相同的过程,我们在量化之后得到:
de-quantized v’ = [-1.1, 70, 5.5, 0.0]
精度的损失开始出现了,让如果我们将同样的损失应用于由70亿个参数组成的LLM:缺乏精度将在整个神经网络中积累,导致有意义的信息完全丢失,并导致纯噪声。而且我们现在使用的是8位格式,如果是4位甚至3位,结果会更糟,对吧。
但是大佬们找到了一种将量化应用于LLM的方法!
4、LLM.int8()使大规模量化成为可能
论文LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale 介绍了一种绕过此异常值问题的方法。

量化参数的完整性会导致性能下降,而在矩阵乘法过程中使用量化,结合混合精度分解和向量量化。在矩阵乘法过程中,从权重矩阵中提取包含异常值(高于阈值)的向量,从而产生两次乘法。小数字矩阵(根据论文代表 99.9% 的值)被量化,而大数字则保留在 FP16 中。
按照混合精度分解原理,对小数乘法输出进行反量化,并添加到其他输出。

也就是说量化技术仅在推理(矩阵乘法)期间使用,这意味着实际上没有8位数字组成的更小的模型!由于这种技术实现,我们甚至得到了一个更大的模型!(根据该论文,对于13B以下的模型,误差为0.1%)但是在BLOOM-175B上的实验表明,在没有任何性能下降的情况下,内存占用减少了1.96倍!这种技术可以访问以前无法装入GPU内存的大型模型
5、可以微调这个量化模型吗?
不行,因为这种技术只适用于推理,不适合训练。
如果我们可以使用量化减少GPU内存占用,并使用LoRA技术训练新的适配器,会怎么样?
还记得我们以前介绍的QLoRA吗,它就干的是这个事,他们成功地将预训练模型量化为4位!它们通过一些新技术来成功地量化模型,比如双量化和4位NormalFloat。
6、如何在代码中使用量化?
首先需要安装bitsandbytes和accelerate 库
pip install -q bitsandbytes
pip install -q accelerate
pip install -q peft==0.4.1
然后,在调用from_pretrained方法时,可以通过传递参数load_in_4bit=True或load_in_8bit= true来加载4位或8位量化的模型。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m",
load_in_4bit=True,
device_map="auto"
)
也可以使用BitsAndBytesConfig类来进行高级的设置
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto"
quantization_config=nf4_config
)
这样模型差不多可以进行推断了。但是我们还需要设置一下的参数:
冻结量化参数以防止训练,
在所有归一化层和 LM 头中使用FP32(未量化),以确保模型的稳定性
如果使用梯度检查点,需要配置model.enable_input_require_grad()
for name, param in model.named_parameters():
# freeze base model's layers
param.requires_grad = False
# cast all non int8 or int4 parameters to fp32
for param in model.parameters():
if (param.dtype == torch.float16) or (param.dtype == torch.bfloat16):
param.data = param.data.to(torch.float32)
if use_gradient_checkpointing:
# For backward compatibility
model.enable_input_require_grads()
在最新的peft==0.4.1库中,使用prepare_model_for_kbit_training()方法可以处理这个准备工作。
这样我们就有了一个量子的模型!
一段代码总结
我们已经介绍了梯度检查点、LoRA和量化,让我们编写代码来对LLM进行微调。
先安装必要的库:
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
然后就是代码:
from transformers import (
AutoModelForCausalLM,
BitsAndBytesConfig
)
from peft import (
get_peft_model,
LoraConfig,
TaskType,
prepare_model_for_kbit_training
)
# Import the model
gradient_checkpointing = True
model = AutoModelForCausalLM.from_pretrained(
args.model_id,
use_cache=False if gradient_checkpointing else True, # this is needed for gradient checkpointing
device_map="auto",
load_in_4bit=True
)
# Prepare the model (freeze, cast FP32, enable_require_grads, activate gradient checkpointing)
model = prepare_model_for_kbit_training(
model,
use_gradient_checkpointing=gradient_checkpointing
)
# Prepare Peft model by adding Lora
peft_config = LoraConfig(
r=64,
lora_alpha=16,
target_modules=modules,
lora_dropout=0.1,
bias="none",
task_type=TaskType.CAUSAL_LM,
)
model = get_peft_model(model, peft_config)
这样模型就可以在本地的GPU上进行微调了。通过创建SFTTrainer (Trainer的一个子类,可以处理我们到目前为止讨论的所有内容)使这个过程变得更加容易。
from trl import SFTTrainer
model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-neo-125m",
load_in_4bit=True,
device_map="auto",
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
dataset_text_field="text",
torch_dtype=torch.bfloat16,
peft_config=peft_config,
)
trainer.train()
总结
在本文中,介绍了大型语言模型微调过程中出现的一个挑战:如何在单个GPU上进行微调。我们介绍了3种技术来减少内存占用:梯度检查点、LoRA和量化。我们看到了如何通过利用PEFT、BitsAndBytes和Transformers将这些技术应用到我们的代码中。
本文的目标是提供一个深入而简单的视图,利用的现有技术,以便在你的项目中微调自己的llm。
作者:Jeremy Arancio