
声明
本篇文章的相关图片来源于论文:InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
论文链接如下:https://arxiv.org/pdf/2211.05778.pdf
碍于本人的知识水平所限,本篇文章的总结可能存在不妥之处
如作为参考,请谨慎推理内容的真实性
欢迎各路大佬指出问题!
文章分类
领域定位
- 计算机视觉
领域细分
- 骨架Backbone
这篇文章得出的结论是什么?
或者说:这篇文章讨论了什么问题?
基于CNN的不同于常规视觉ViTs的新型模型骨架架构InternImage介绍与讨论
这篇文章的创新点在哪里?
- 算子创新- 可变形卷积- 具有以输入和任务信息为条件的自适应空间聚集
这篇文章的技术点在哪里?
这篇论文的相关工作及其主线为?
CNN模型及其发展与ViTs
从前有一个老师,给学术搞了的送命题,还以为是送分题
然后老师发现学术停止了思考,于是拉了个群都是大佬一起研究
起初大家用了一堆滤波方法,叫SLAM
再来有个大佬搞了个5层卷积算法叫LeNet,大家疯狂diss CNN无前途。

这时,开尔文的棺材动了
(”物理(计算机视觉)大厦已经落成,所剩只是一些《修饰工作》。“)

有个大佬整了AlexNet,当年的ImageNet直接被屠榜
然后有了VGG,GoogLeNet,MobileNet......
大佬分成3类,一类开始让CNN更快,一部分开始搞各种模块,一部分试图让CNN是man就下100层
后来大家发现CNN在50层就虚了,下不了100层
大家认为CNN无了

然后王境泽说了一句:真香~

ResNet屠榜了
之后大家开始研究ResNet,发现残差真TM香
又搞了一堆RepVGG架构等等,CV领域开始开花结果
然后隔壁的自然语言处理的大佬有个视—语双修的,搞了个ViTs
这下视觉被变形金刚屠榜了
有了一系列诸如swin-transformer之类的玩意儿
视觉界的部分卷积大佬不服,于是深挖CNN极限
整了个ConvNet试图与ViTs抗衡
然后就到了InternImage了
大规模图像模型
——关于大公司在参数领域的一路疯狂内卷
事情是这样的:
受NLP领域的启发
Zhai等人提出了一个新的方法:首次将ViT扩展到20亿个参数
Liu等人:将分层结构的Swin变换器扩大到一个更深更广的模型,有30亿个参数
一些研究人员:通过结合ViTs和CNNs在不同层面的优势,开发了大规模的混合ViTs
BEiT-3进一步探索了基于ViT的更强的表征,并使用多模态预训练的大规模参数。这些方法大大提高了基本视觉任务的上限。
...... 内卷是吧,还用GPU卷😅
这篇文章主要的设计是?
针对DCNv2上进行的优化,通过(原版照抄)迁移类Transformer的架构与针对DCNv2一些固有问题(增加其长程依赖,归一化上的优化调整,仿深度可分离的卷积组架构)构造了一个InternImage(Stage)块,并进行了许多的超参优化使其更好调参。
这篇文章是怎么做实验的?
- 提了一堆任务
- 掏出一堆对应任务的SOTA
- 掏出InternImage- 【放置】无敌的音响二色蓮花蝶 ~ Red and White- 【挂符】无敌且穷凶极恶的巫女

- Buff上完,开始对比
- 结论:咱的InternImage与大多数SOTA五五开,有些规模甚至赣爆了对吗成为了新的SOTA
这篇文章的论述主线是怎么样的?
以下”我们“代入论文作者视角进行拆分》》》
- 摘要- ViTs很强- 但是CNN还有开发的余地- 咱搞了个InternImage- 与最近CNN搞大型密集核不一样- 咱用可变形卷积- 所以咱模型有超大感受野- 有自适应空间聚合- 所以减少了CNN的归纳偏见- 我们的模型的有效性在包括ImageNet、COCO和ADE20K在内的挑战性基准上得到了证明- 模型的-H版本在COCO与ADE-20K上整了个SOTA
- 介绍- 吹ViTs- ViTs真的NB- 虽然数据量大的情况下我卷积赣不过变形金刚- 但是我们认为只要卷积放弃做人(不是),就能够赣爆ViTs- 分析敌我差距- ViTs有长程依赖性与自适应空间聚合- ViTs能学习到更Strong的表示- ViTs还有一堆各种花里胡哨的- 层归一化- 前馈网络- GELU等- 尽管卷积最近的研究试图使用超大的核超越人类- 但还是被变形金刚赣爆了- 我们赣了些什么?- 咱选了个冷门的可变形卷积(DCN)- 保留一部分类似于ViTs的架构,在混入一部分DCN- InternImage就诞生了- InternImage究竟如何做到的不做人?
 - 整了一个动态的稀疏卷积,窗口3*3- 能够自动学习感受野——不论长程还是短程- 采样偏移与调制标量(?怪怪的)自动调整- 避免了由大型密集核引起的优化问题和昂贵的成本- 所以我们赣了啥?(威严满满)
- 整了一个动态的稀疏卷积,窗口3*3- 能够自动学习感受野——不论长程还是短程- 采样偏移与调制标量(?怪怪的)自动调整- 避免了由大型密集核引起的优化问题和昂贵的成本- 所以我们赣了啥?(威严满满) - 我们提出了一个新的基于CNN的大规模基础模型InternImage- 我们成功地将CNN扩展到大规模的环境中- 咱搞了个多任务的模型,并且有一部分SOTA了
- 我们提出了一个新的基于CNN的大规模基础模型InternImage- 我们成功地将CNN扩展到大规模的环境中- 咱搞了个多任务的模型,并且有一部分SOTA了 - 相关工作(狗头)- CNN模型及其发展(上面有)- ViTs(同)- 大规模图像模型(同)
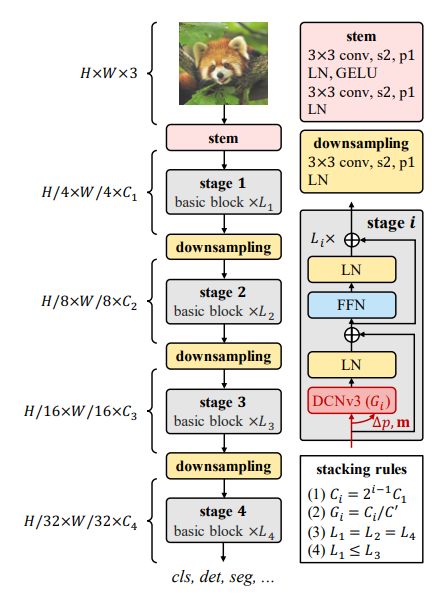
- 方法- 如何构造一个论文中提到的卷积算子?- 灵活的卷积变体(DCNv2)——>亿点点调整——>将调谐卷积算子与现代骨干网络中的高级块设计结合+基于DCN块的堆叠与缩放定理 == InternImage- 可变形卷积V3(DCNv3)- 卷积与MHSA的区别- 长程依赖关系(你33卷积就那么点感受野,看看人家ViTs)- 自适应的空间聚合- 与权重受输入动态调节的MHSA相比- 常规卷积是一个具有静态权重和强归纳偏差的算子,如二维定位、邻域结构、翻译等值等- 由于具有高度的归纳特性,由常规卷积组成的模型可能比ViTs更快地融合,并且需要更少的训练数据。- 但它也限制了CNN从网络规模的数据中学习更普遍和稳健的模式。- 重新审视DCNv2- 将长程依赖于自适应空间之间引入常规卷积- DCNv2长什么样?- 诠释- K代表了采样点的个数- k列举了采样点- 表明第k个采样点的投影权重- 表示第k个采样点的调制标量,通过sigmoid函数进行归一化- 表示预先定义的网格采样的第k个位置- 是对应与第k个网格采样位置的偏移- 分析- 对于长距离的依赖性,采样偏移量是灵活的,能够与短程或者长程的依赖性相互作用。- 对于自适应空间聚合,采样偏移量和调制标量都是可学习的,并以输入为条件。- 因此可以发现,DCNv2与MHSA有着相似的有利特性(所以架构也一样)- 怎么扩展DCN成为一个主要的架构?- 通常DCNv2就是一个存在感超低的组件,就像你海晶卡组里面Link-4的装备卡一样无关紧要,纯纯涨点数的。- 首先,在卷积神经元之间共享权重- 原始的DCNv2具有独立的线性投影权重- 所以其参数与内存复杂度与采样点总数呈线性关系- 借助可分离卷积的思想,将原始卷积权重分为深度部分与点部分,深度部分依赖于,点部分设置为共享的投影权重- 引入多组机制- 多组(头)设计首次出现在组卷积中- 广泛使用于MHSA(多头注意力机制)- 所以:我们将空间聚合这个过程分成G组- 每组都有单独的采样偏移量- 与调制尺度- 因此单个卷积层上的不同组可以有不同的空间聚合模式,从而为下游提供更强的特征任务。- 沿采样点归一化调制标量(照搬Transformer 🐶)- 原始 DCNv2 中的调制标量由 sigmoid 函数按元素归一化- 因此,每个调制标量都在[0, 1]范围内,所有样本点的调制标量之和不稳定,在0到K之间变化- 这导致训练时DCNv2层的梯度不稳定- 为了缓解不稳定性问题- 将逐元素 sigmoid 归一化更改为*沿样本点的 softmax 归一化。- 这样,调制标量的和被约束为1,使得模型在不同尺度下的训练过程更加稳定。- DCNv3- G:聚合组的总数- 对于第g组:- 表示该组的位置无关投影权重,其中表示组维度,表示第g个组中第k个采样点的调制标量- 由softmax函数沿维度K进行归一化- 对应于输入特征图中的切片- 为第g组中网格采样位置对应的偏移量- DCNv3的优点- 解决了常规卷积在长程依赖和自适应空间聚合方面的不足- 算子继承了卷积的归纳偏置,使得模型更加高效- 算子基于稀疏采样。较以前的方法例如MHSA或是重参数化大内核等方法具有更高的计算与内存效率- 由于采样稀疏,DCNv3只需要一个3*3级别的核来学习长程依赖‘- InternImage Model的菜谱及其烹饪- 基本模块- 类Transformer架构- 基本算子- Stem层 & 下采样层- 堆叠规则- 配置- LN,FFN,GELU- 图例- 核心模块组成- 模型scale及其超参
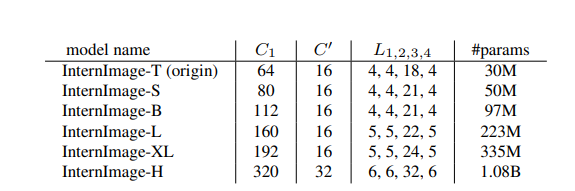 - 超参数说明:- 第i个阶段的通道数- 第i个阶段DCNv3的组数量- 第i个阶段的基本块数- 模型堆叠了四个阶段,即i=4,此时的超参总数为个,搜索空间过大难以穷穷举- 超参搜索规则(现有技术设计经验)(见上图stacking rules)(归约到4个超参数)(C1,C’,L1,L3)1. 后3个通道数由通道数C1决定2. 组号对应于阶段通道数:AABA原则(A<=B)3. 最佳超参设置:- 缩放规则- 参数缩放规则:考虑两个缩放维度:深度D(3L1+L3)与宽度C1,并使用与复合因子这3个维度- 基于这种缩放规则构建了不同参数尺度的 InternImage 变体- 即 InternImage-T/S/B/L/XL- 其复杂度 类似于 ConvNeXt- 为了进一步测试能力用 10 亿参数构建了一个更大的 InternImage-H,为了适应超大模型宽度,将C‘改为32
- 超参数说明:- 第i个阶段的通道数- 第i个阶段DCNv3的组数量- 第i个阶段的基本块数- 模型堆叠了四个阶段,即i=4,此时的超参总数为个,搜索空间过大难以穷穷举- 超参搜索规则(现有技术设计经验)(见上图stacking rules)(归约到4个超参数)(C1,C’,L1,L3)1. 后3个通道数由通道数C1决定2. 组号对应于阶段通道数:AABA原则(A<=B)3. 最佳超参设置:- 缩放规则- 参数缩放规则:考虑两个缩放维度:深度D(3L1+L3)与宽度C1,并使用与复合因子这3个维度- 基于这种缩放规则构建了不同参数尺度的 InternImage 变体- 即 InternImage-T/S/B/L/XL- 其复杂度 类似于 ConvNeXt- 为了进一步测试能力用 10 亿参数构建了一个更大的 InternImage-H,为了适应超大模型宽度,将C‘改为32 - 现在是,实验时间!- 在图像分类,对象检测,实例与语义分割都整了比较- 消融实验在Appendix(速读不看不讲系列)- 图像分类- 设置- 数据集:ImageNet-1K,Laion-400M,YFCC-15M,CC12M- 模型:ConvNexT,Swin,DeiT。。。。。。太多不写了- 为了公平比较,按照常见做法 [2,10,21,58],InternImage-T/S/B 在 ImageNet-1K(
130 万)上训练 300 个 epoch,InternImage-L/XL 首先训练 在 ImageNet-22K(1420 万)上进行 90 个迭代,然后在 ImageNet-1K 上微调 20 个迭代。 为了进一步探索我们模型的能力并匹配以前方法[16、20、59]中使用的大规模私有数据,我们采用 M3I 预训练 [60],一种统一的预训练方法,可用于未标记的 和弱标记数据,在公共 Laion-400M [61]、YFCC-15M [62] 和 CC12M [63] 的 4.27 亿联合数据集上预训练 InternImage-H 30 个时期,然后我们微调 ImageNet 1K 上的模型 20 个 epochs。- 结果- 抗衡与ViTs,ConvNext,有些情况超过了他俩- (嘴硬说VIT与ConvNext可能动了私货数据集,但是咱的InternImage没有,所以⑨是最强的!)- 具体看下面图例介绍- 目标检测与实例分割- 设置- COCO基准- 对比框架:Mask-RCNN,Cascade Mask R-CNN,DETR等- 结果- InternImage明显的强于RCNN- SOTA(加了自监督微调)- 语义分割- 设置- 数据集:ADE20K- 对比模型:UperNet,Mask2Former......- 结果- SOTA- 具体看表格吧 - 消融研究- 由于硬件限制,大型模型对核心运算符的参数和内存成本很敏感。- 为了解决这个问题,我们在 DCNv3 的卷积神经元之间共享权重。
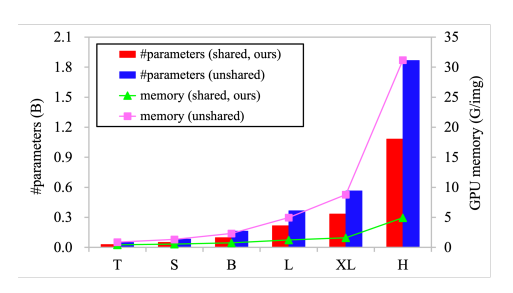 - 我们看到具有非共享权重的模型的参数和内存成本比共享权重高得多,特别是对于 -H 尺度,保存参数和 GPU 内存的比率分别为 42.0% 和 84.2%。 如表 6 所示,我们还检查了 -T 尺度的两个模型在 ImageNet(83.5 对 83.6)和 APb(47.2 对 47.4)上具有相似的 top-1 精度,即使是没有共享权重的模型 多了 66.1% 的参数
- 我们看到具有非共享权重的模型的参数和内存成本比共享权重高得多,特别是对于 -H 尺度,保存参数和 GPU 内存的比率分别为 42.0% 和 84.2%。 如表 6 所示,我们还检查了 -T 尺度的两个模型在 ImageNet(83.5 对 83.6)和 APb(47.2 对 47.4)上具有相似的 top-1 精度,即使是没有共享权重的模型 多了 66.1% 的参数 - 结论- 我们介绍了 InternImage,这是一种新的基于 CNN 的大规模基础模型,可以为图像分类、目标检测和语义分割等多种视觉任务提供强大的表示。 我们调整了灵活的DCNv2算子以满足基础模型的要求,并开发了一系列以核心算子为中心的块、堆叠和缩放规则。 大量关于对象检测和语义分割基准的实验证实,我们的 InternImage 可以获得与经过大量数据训练的精心设计的大规模视觉变换器相当或更好的性能,表明 CNN 也是大型图像的重要选择。 尺度视觉基础模型研究。 尽管如此,对于基于 DCN 的运营商适应具有高速要求的下游任务来说,延迟仍然是一个问题。 此外,大规模 CNN 仍处于早期发展阶段,我们希望 InternImage 可以作为一个良好的起点。
文章的图例展示及其论述如何?
对于不同核心架构的可解释性图例分析
图例
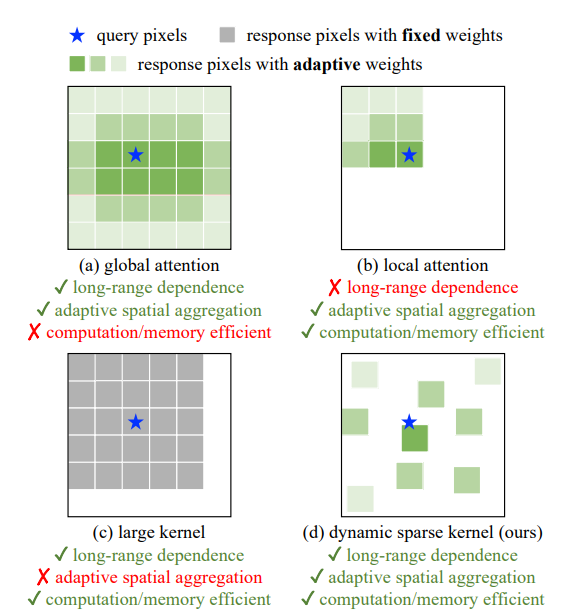
方法
具有自适应权重的响应像素可视化(概念图)
论述
(a)显示了多头自我注意(MHSA)[1]的全局聚合,其计算和内存成本在需要高分辨率输入的下流任务中非常昂贵。
(b)将MHSA的范围限制为一个局部窗口,以降低成本。
(c)是一种深度卷积,具有非常大的核,用于建模长范围相关性。
(d)为可变形卷积,具有与MHSA相似的优良性质,对于大尺度模型足够有效。我们从它开始构建一个大规模的CNN
结论
可变形卷积较ViTs,深度卷积有更好的长程感受力,空间聚合能力与可接受的记忆单元消耗
在COCO数据集上的性能比较
图例
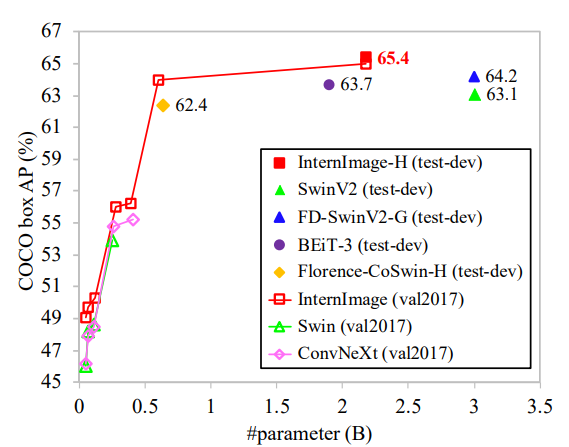
方法
COCO数据集上的, 基于box AP的性能衡量与比较
与Swin V2,FD-SwinV2-G,BEiT-3,Florence-CoSwin-H,Swin,ConvNeXt进行比较
论述
所提出的InternImage-H在COCO测试开发中实现了创纪录的65.4盒AP,显著优于最先进的CNN和大规模ViT。
结论
同论述。
InternImage总体架构
图例
方法
网格结构图介绍
论述
核心操作符是DCNv3
基本块由层正常化(LN)[24]和前馈网络(FFN)[1]作为转换器组成
主干层和下采样层遵循传统CNN的设计
“s2”和“p1”分别表示步长:2和填充:1
受叠加规则的约束,只有4个超参数(C1、C0、L1、L3)可以决定一个模型
结论
介绍,无结论
不同规模模型的超参数
图例
方法
表格
论述
InternImage-T是原始模型,-S/B/L/XL/H是从-T放大的。“#params”表示参数的数量。
结论
介绍,无结论
ImageNet数据集上的图像分类性能
图例
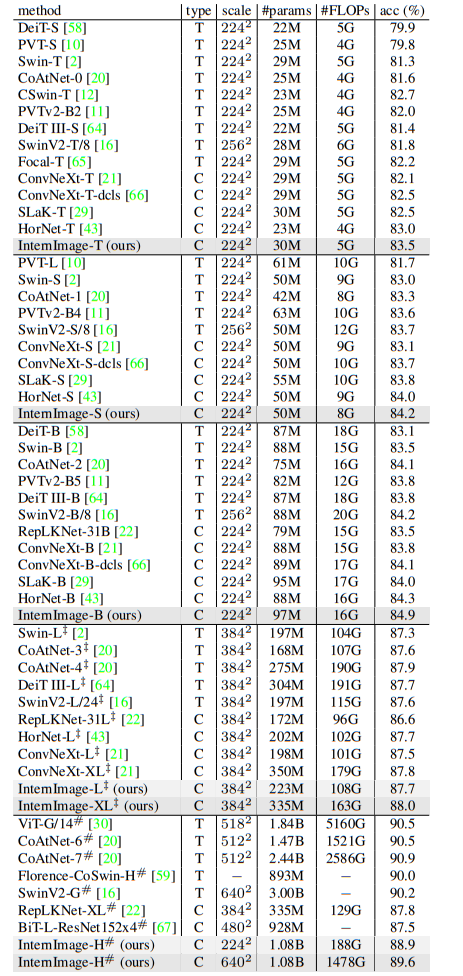
方法
表格
论述
type:模型类型
“T”:transformer
“C”:CNN
“scale” is the input scale
“acc” :表示Top-1的准确率
“‡ ” 代表模型在ImageNet-22K上执行了预训练
“#”:表示在超大的不公开数据集上进行训练,例如FT-300M,FLD-900M,论文本身准备的联合公共数据集
结论
如上述表格,体现了InternImage系列在该任务上的优越性(公开数据集上似乎一般?)
COCO val2017上的对象检测和实例分割性能
图例
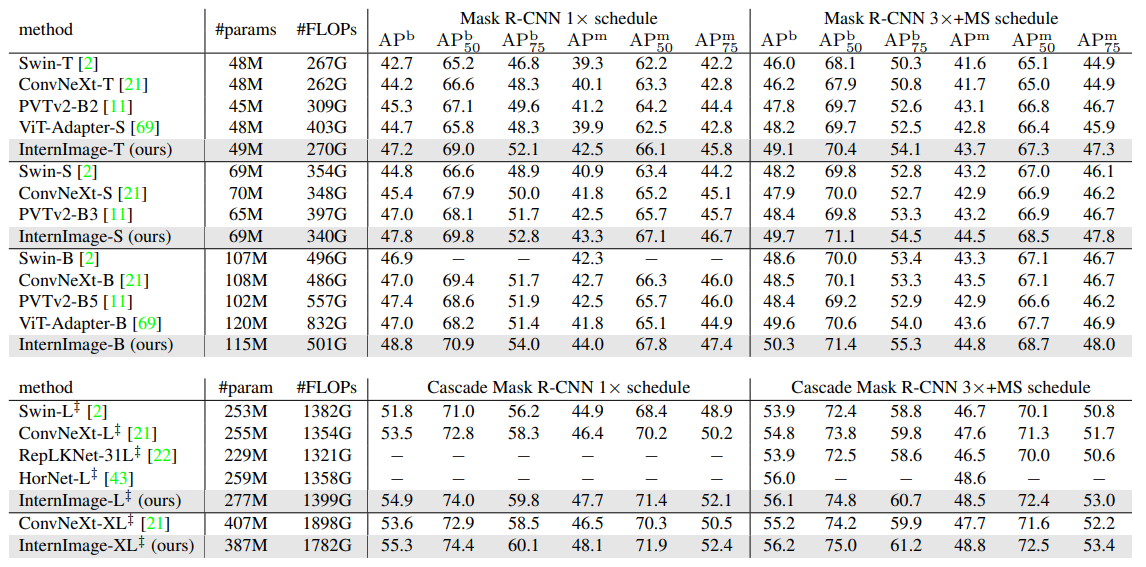
方法
表格
论述
FLOP采用1280×800输入进行测量。APb和APm分别表示方框AP和掩码AP。“MS”是指多尺度训练。
结论
如上述表格,体现了InternImage系列在该任务上的优越性
COCO val2017和测试开发上最先进的探测器的比较
图例
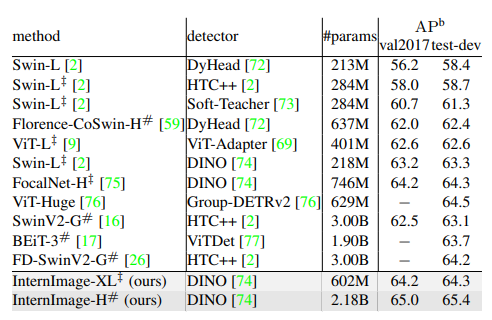
方法
表格
论述
COCO val2017和测试开发上最先进的探测器的比较
结论
InternImage在该数据集上的训练效果很好。
ADK20K验证集上的语义分割性能
图例
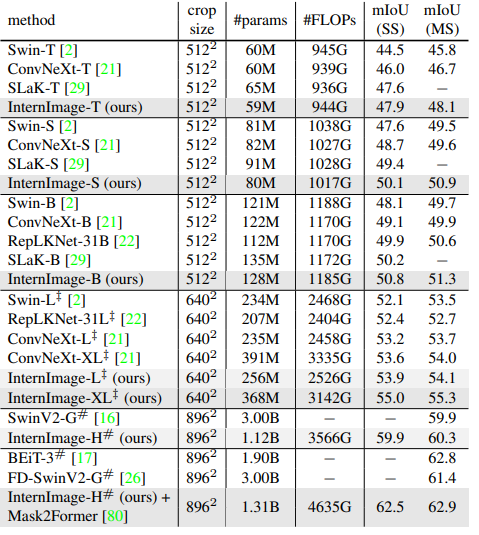
方法
表格
论述
“SS”和“MS”分别表示单尺度和多尺度测试。
根据裁剪尺寸用512×2048、640×2560或896×896的输入测量FLOPs
结论
同比比较效果不错?
消融实验中GPU内存使用量与共享模型参数的比较关系
图例
方法
直方图+折线图+双纵坐标轴
论述
左纵轴表示模型参数,右纵轴表示当批处理量为32,输入图像分辨率为224×224时,每幅图像的GPU内存使用量。
结论
通过图例可以对不同的参数共享状态与GPU内存使用有一个直观的感受。
不同阶段不同群体的采样位置的可视化
图例
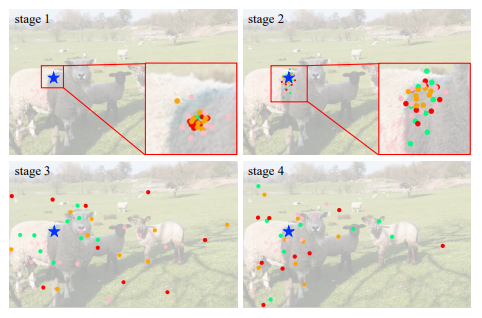
方法
带背景的散点图
论述
蓝星表示查询点(在左边的羊群上),不同颜色的点表示不同组的采样位置。
结论
对于同一个查询像素,来自不同组的偏移量集中在不同的区域,从而产生了层次化的语义特征。
DCNv3中三种修改的消融比较
图例
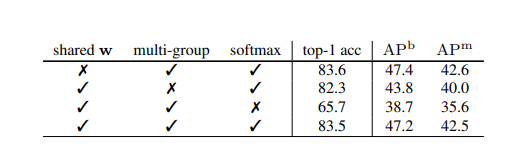
方法
表格
论述
这些实验是基于InternImage-T的分类和Mask R-CNN 1×的检测
结论
在-T尺度下的两个模型在ImageNet(83.5 vs. 83.6)和COCO(47.2 vs. 47.4)上具有相似的前1名准确率,即使没有共享权重的模型也有66.1%的参数
版权归原作者 万年学习的小伞 所有, 如有侵权,请联系我们删除。