

>>>深度学习Tricks,第一时间送达<<<
1.MobileOne: 移动端仅需1ms的高性能骨干!
论文题目:An Improved One millisecond Mobile Backbone
论文地址:http://An Improved One millisecond Mobile Backbone

一般用于移动设备的高效神经网络骨干通常针对 FLOP 或参数计数等指标进行优化。然而,当部署在移动设备上时,这些指标可能与网络的延迟没有很好的相关性。因此,我们通过在移动设备上部署多个移动友好网络来对不同指标进行广泛分析。我们识别和分析最近高效神经网络中的架构和优化瓶颈,并提供缓解这些瓶颈的方法。为此,我们设计了一个高效的骨干 MobileOne,其变体在 iPhone12 上的推理时间低于 1 毫秒,在 ImageNet 上的 top-1 准确率为 75.9%。我们展示了 MobileOne 在高效架构中实现了SOTA性能,同时在移动设备上速度提高了许多倍。我们最好的模型在 ImageNet 上获得了与 MobileFormer 相似的性能,同时速度提高了 38 倍。我们的模型在 ImageNet 上的 top-1 准确率比 EfficientNet 在相似的延迟下高 2.3%。此外,我们展示了我们的模型可以推广到多个任务——图像分类、目标检测和语义分割,与部署在移动设备上的现有高效架构相比,延迟和准确度显著提高。
MobileOne(≈MobileNetV1+RepVGG+训练Trick)是由Apple公司提出的一种基于iPhone12优化的超轻量型架构,在ImageNet数据集上以<1ms的速度取得了75.9%的Top1精度!!!
2.MobileOne block网络模型:
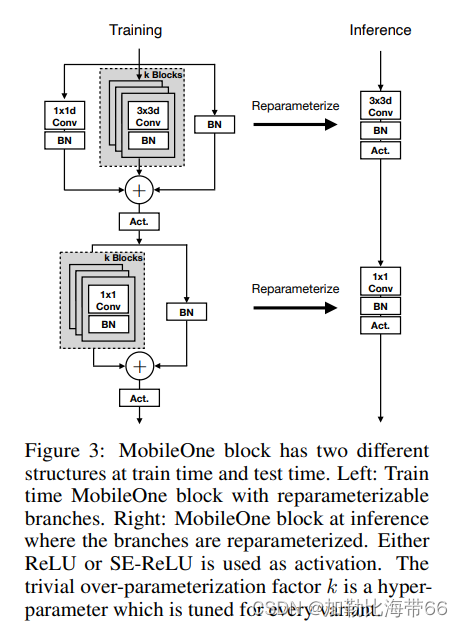
3.源代码
import time
import torch.nn as nn
import numpy as np
import torch
import copy
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class DepthWiseConv(nn.Module):
def __init__(self, inc, kernel_size, stride=1):
super().__init__()
padding = 1
if kernel_size == 1:
padding = 0
# self.conv = nn.Sequential(
# nn.Conv2d(inc, inc, kernel_size, stride, padding, groups=inc, bias=False,),
# nn.BatchNorm2d(inc),
# )
self.conv = conv_bn(inc, inc, kernel_size, stride, padding, inc)
def forward(self, x):
return self.conv(x)
class PointWiseConv(nn.Module):
def __init__(self, inc, outc):
super().__init__()
# self.conv = nn.Sequential(
# nn.Conv2d(inc, outc, 1, 1, 0, bias=False),
# nn.BatchNorm2d(outc),
# )
self.conv = conv_bn(inc, outc, 1, 1, 0)
def forward(self, x):
return self.conv(x)
class MobileOneBlock(nn.Module):
def __init__(self, in_channels, out_channels, k, stride=1, dilation=1, padding_mode='zeros', deploy=False,
use_se=False):
super(MobileOneBlock, self).__init__()
self.deploy = deploy
self.in_channels = in_channels
self.out_channels = out_channels
self.deploy = deploy
kernel_size = 3
padding = 1
assert kernel_size == 3
assert padding == 1
self.k = k
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
...
else:
self.se = nn.Identity()
if deploy:
self.dw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=in_channels,
bias=True, padding_mode=padding_mode)
self.pw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,
bias=True)
else:
# self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
# self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
# self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
# print('RepVGG Block, identity = ', self.rbr_identity)
self.dw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'dw_3x3_{k_idx}', DepthWiseConv(in_channels, 3, stride=stride))
self.dw_1x1 = DepthWiseConv(in_channels, 1, stride=stride)
self.pw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'pw_1x1_{k_idx}', PointWiseConv(in_channels, out_channels))
def forward(self, inputs):
if self.deploy:
x = self.dw_reparam(inputs)
x = self.nonlinearity(x)
x = self.pw_reparam(x)
x = self.nonlinearity(x)
return x
if self.dw_bn_layer is None:
id_out = 0
else:
id_out = self.dw_bn_layer(inputs)
x_conv_3x3 = []
for k_idx in range(self.k):
x = getattr(self, f'dw_3x3_{k_idx}')(inputs)
# print(x.shape)
x_conv_3x3.append(x)
x_conv_1x1 = self.dw_1x1(inputs)
# print(x_conv_1x1.shape, x_conv_3x3[0].shape)
# print(x_conv_1x1.shape)
# print(id_out)
x = id_out + x_conv_1x1 + sum(x_conv_3x3)
x = self.nonlinearity(self.se(x))
# 1x1 conv
if self.pw_bn_layer is None:
id_out = 0
else:
id_out = self.pw_bn_layer(x)
x_conv_1x1 = []
for k_idx in range(self.k):
x_conv_1x1.append(getattr(self, f'pw_1x1_{k_idx}')(x))
x = id_out + sum(x_conv_1x1)
x = self.nonlinearity(x)
return x
# Optional. This improves the accuracy and facilitates quantization.
# 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight.
# 2. Use like this.
# loss = criterion(....)
# for every RepVGGBlock blk:
# loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2()
# optimizer.zero_grad()
# loss.backward()
def get_custom_L2(self):
# K3 = self.rbr_dense.conv.weight
# K1 = self.rbr_1x1.conv.weight
# t3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
# t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
# l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2, 1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them.
# eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel.
# l2_loss_eq_kernel = (eq_kernel ** 2 / (t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2.
# return l2_loss_eq_kernel + l2_loss_circle
...
# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,
# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.
def get_equivalent_kernel_bias(self):
# kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
# kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
# kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
# return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
dw_kernel_3x3 = []
dw_bias_3x3 = []
for k_idx in range(self.k):
k3, b3 = self._fuse_bn_tensor(getattr(self, f"dw_3x3_{k_idx}").conv)
# print(k3.shape, b3.shape)
dw_kernel_3x3.append(k3)
dw_bias_3x3.append(b3)
dw_kernel_1x1, dw_bias_1x1 = self._fuse_bn_tensor(self.dw_1x1.conv)
dw_kernel_id, dw_bias_id = self._fuse_bn_tensor(self.dw_bn_layer, self.in_channels)
dw_kernel = sum(dw_kernel_3x3) + self._pad_1x1_to_3x3_tensor(dw_kernel_1x1) + dw_kernel_id
dw_bias = sum(dw_bias_3x3) + dw_bias_1x1 + dw_bias_id
# pw
pw_kernel = []
pw_bias = []
for k_idx in range(self.k):
k1, b1 = self._fuse_bn_tensor(getattr(self, f"pw_1x1_{k_idx}").conv)
# print(k1.shape)
pw_kernel.append(k1)
pw_bias.append(b1)
pw_kernel_id, pw_bias_id = self._fuse_bn_tensor(self.pw_bn_layer, 1)
pw_kernel_1x1 = sum(pw_kernel) + pw_kernel_id
pw_bias_1x1 = sum(pw_bias) + pw_bias_id
return dw_kernel, dw_bias, pw_kernel_1x1, pw_bias_1x1
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch, groups=None):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
bias = branch.conv.bias
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
# if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // groups # self.groups
if groups == 1:
ks = 1
else:
ks = 3
kernel_value = np.zeros((self.in_channels, input_dim, ks, ks), dtype=np.float32)
for i in range(self.in_channels):
if ks == 1:
kernel_value[i, i % input_dim, 0, 0] = 1
else:
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
dw_kernel, dw_bias, pw_kernel, pw_bias = self.get_equivalent_kernel_bias()
self.dw_reparam = nn.Conv2d(in_channels=self.pw_1x1_0.conv.conv.in_channels,
out_channels=self.pw_1x1_0.conv.conv.in_channels, kernel_size=self.dw_3x3_0.conv.conv.kernel_size,
stride=self.dw_3x3_0.conv.conv.stride, padding=self.dw_3x3_0.conv.conv.padding,
groups=self.dw_3x3_0.conv.conv.in_channels, bias=True, )
self.pw_reparam = nn.Conv2d(in_channels=self.pw_1x1_0.conv.conv.in_channels,
out_channels=self.pw_1x1_0.conv.conv.out_channels, kernel_size=1, stride=1, bias=True)
self.dw_reparam.weight.data = dw_kernel
self.dw_reparam.bias.data = dw_bias
self.pw_reparam.weight.data = pw_kernel
self.pw_reparam.bias.data = pw_bias
for para in self.parameters():
para.detach_()
self.__delattr__('dw_1x1')
for k_idx in range(self.k):
self.__delattr__(f'dw_3x3_{k_idx}')
self.__delattr__(f'pw_1x1_{k_idx}')
if hasattr(self, 'dw_bn_layer'):
self.__delattr__('dw_bn_layer')
if hasattr(self, 'pw_bn_layer'):
self.__delattr__('pw_bn_layer')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class MobileOne(nn.Module):
def __init__(self, blocks, ks, channels, strides, width_muls, num_classes, deploy=False):
super().__init__()
self.stage_num = len(blocks)
# self.stage0 = MobileOneBlock(3, int(channels[0] * width_muls[0]), ks[0], stride=strides[0], deploy=deploy)
self.stage0 = nn.Sequential(nn.Conv2d(4, int(channels[0] * width_muls[0]), 3, 2, 1, bias=False),
nn.BatchNorm2d(int(channels[0] * width_muls[0])), nn.ReLU(), )
in_channels = int(channels[0] * width_muls[0])
for idx, block_num in enumerate(blocks[1:]):
idx += 1
module = []
out_channels = int(channels[idx] * width_muls[idx])
for b_idx in range(block_num):
stride = strides[idx] if b_idx == 0 else 1
block = MobileOneBlock(in_channels, out_channels, ks[idx], stride, deploy=deploy)
in_channels = out_channels
module.append(block)
setattr(self, f"stage{idx}", nn.Sequential(*module))
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Sequential(nn.Linear(out_channels, num_classes, ), )
def forward(self, x):
# for s_idx in range(self.stage_num):
# x = getattr(self, f'stage{s_idx}')(x)
x0 = self.stage0(x)
# print(x0[0,:,0,0])
# return x0
x1 = self.stage1(x0)
x2 = self.stage2(x1)
x3 = self.stage3(x2)
x4 = self.stage4(x3)
x5 = self.stage5(x4)
x = self.avg_pool(x5)
x = torch.flatten(x, start_dim=1) # b, c
x = self.fc1(x)
return x
def make_mobileone_s0(num_classes,deploy=False):
blocks = [1, 2, 8, 5, 5, 1]
strides = [2, 2, 2, 2, 1, 2]
ks = [4, 4, 4, 4, 4, 4] if deploy is False else [1, 1, 1, 1, 1, 1]
width_muls = [0.75, 0.75, 1, 1, 1, 2] # 261 M flops
channels = [64, 64, 128, 256, 256, 512, 512]
model = MobileOneNet(blocks, ks, channels, strides, width_muls, num_classes, deploy)
return model
def repvgg_model_convert(model: torch.nn.Module, do_copy=True, input=None, output=None):
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
print('swith done. Checking....')
deploy_model = make_mobileone_s0(26,deploy=True)
deploy_model.eval()
deploy_model.load_state_dict(model.state_dict())
if input is not None:
o = deploy_model(x)
# print(o)
# print(output)
print((output - o).sum())
# if save_path is not None:
# torch.save(model.state_dict(), save_path)
return deploy_model
if __name__ == '__main__':
model = make_mobileone_s0(num_classes=4)#.cuda(0)
model.eval()
data = torch.rand(1, 4, 128, 128)#.cuda(0)
for i in range(10):
start = time.time()
out = model(data)
print('time', time.time() - start, out.size())
如何结合YOLOv5,有需要且感兴趣的小伙伴关注互粉一下,一起学习!共同进步!
🚀🏆🍀【算法创新&算法训练&论文投稿】相关链接👇👇👇
✨【YOLO创新算法尝新系列】✨
🏂 美团出品 | YOLOv6 v3.0 is Coming(超越YOLOv7、v8)
🏂 官方正品 | Ultralytics YOLOv8算法来啦(尖端SOTA模型)
🏂 改进YOLOv5/YOLOv7——魔改YOLOv5/YOLOv7提升检测精度(涨点必备)
————————————🌴【重磅干货来袭】🎄————————————
🚀一、主干网络改进(持续更新中)🎄🎈
1.目标检测算法——YOLOv5/YOLOv7改进之结合ConvNeXt结构(纯卷积|超越Swin)
2.目标检测算法——YOLOv5/YOLOv7改进之结合MobileOne结构(高性能骨干|仅需1ms)
3.目标检测算法——YOLOv5/YOLOv7改进之结合Swin Transformer V2(涨点神器)
4.目标检测算法——YOLOv5/YOLOv7改进结合BotNet(Transformer)
5.目标检测算法——YOLOv5/YOLOv7改进之GSConv+Slim Neck(优化成本)
6.目标检测算法——YOLOv5/YOLOv7改进结合新神经网络算子Involution(CVPR 2021)
7.目标检测算法——YOLOv7改进|增加小目标检测层
8.目标检测算法——YOLOv5改进|增加小目标检测层
🌴 持续更新中……
🚀二、轻量化网络(持续更新中)🎄🎈
1.目标检测算法——YOLOv5/YOLOv7改进之结合RepVGG(速度飙升)
2.目标检测算法——YOLOv5/YOLOv7改进之结合PP-LCNet(轻量级CPU网络)
3.目标检测算法——YOLOv5/YOLOv7改进之结合轻量化网络MobileNetV3(降参提速)
4.目标检测算法——YOLOv5/YOLOv7改进|结合轻量型网络ShuffleNetV2
5.目标检测算法——YOLOv5/YOLOv7改进结合轻量型Ghost模块
🌴 持续更新中……
🚀三、注意力机制(持续更新中)🎄🎈
1.目标检测算法——YOLOv5改进之结合CBAM注意力机制
2.目标检测算法——YOLOv7改进之结合CBAM注意力机制
3.目标检测算法——YOLOv5/YOLOv7之结合CA注意力机制
4.目标检测算法——YOLOv5/YOLOv7改进之结合ECA注意力机制
5.目标检测算法——YOLOv5/YOLOv7改进之结合NAMAttention(提升涨点)
6.目标检测算法——YOLOv5/YOLOv7改进之结合GAMAttention
7.目标检测算法——YOLOv5/YOLOv7改进之结合无参注意力SimAM(涨点神器)
8.目标检测算法——YOLOv5/YOLOv7改进之结合Criss-Cross Attention
9.目标检测算法——YOLOv5/YOLOv7改进之结合SOCA(单幅图像超分辨率)
🌴 持续更新中……
🚀四、检测头部改进(持续更新中)🎄🎈
1.魔改YOLOv5/v7高阶版(魔法搭配+创新组合)——改进之结合解耦头Decoupled_Detect
2.目标检测算法——YOLOv5/YOLOv7改进结合涨点Trick之ASFF(自适应空间特征融合)
🌴 持续更新中……
🚀五、空间金字塔池化(持续更新中)🎄🎈
1.目标检测算法——YOLOv5/YOLOv7改进之结合ASPP(空洞空间卷积池化金字塔)
2.目标检测算法——YOLOv5/YOLOv7改进之结合特征提取网络RFBNet(涨点明显)
🌴 持续更新中……
🚀六、损失函数及NMS改进(持续更新中)🎄🎈
1.目标检测算法——YOLOv5/YOLOv7改进|将IOU Loss替换为EIOU Loss
2.目标检测算法——助力涨点 | YOLOv5改进结合Alpha-IoU
3.目标检测算法——YOLOv5/YOLOv7改进之结合SIoU
4.目标检测算法——YOLOv5将NMS替换为DIoU-NMS
🌴 持续更新中……
🚀七、其他创新改进项目(持续更新中)🎄🎈
1.手把手教你搭建属于自己的PyQt5-YOLOv5目标检测平台(保姆级教程)
2.YOLO算法改进之结合GradCAM可视化热力图(附详细教程)
3.目标检测算法——YOLOv5/YOLOv7改进之结合SPD-Conv(低分辨率图像和小目标涨点明显)
4.目标检测算法——YOLOv5/YOLOv7改进之更换FReLU激活函数
5.目标检测算法——YOLOv5/YOLOv7改进之结合BiFPN
🌴 持续更新中……
🚀八、算法训练相关项目(持续更新中)🎄🎈
1.目标检测算法——YOLOv7训练自己的数据集(保姆级教程)
2.人工智能前沿——玩转OpenAI语音机器人ChatGPT(中文版)
3.深度学习之语义分割算法(入门学习)
4.知识经验分享——YOLOv5-6.0训练出错及解决方法(RuntimeError)
5.目标检测算法——将xml格式转换为YOLOv5格式txt
6.目标检测算法——YOLOv5/YOLOv7如何改变bbox检测框的粗细大小
7.人工智能前沿——6款AI绘画生成工具
8.YOLOv5结合人体姿态估计
9.超越YOLOv5,0.7M超轻量,又好又快(PP-YOLOE&PP-PicoDet)
10.目标检测算法——收藏|小目标检测的定义(一)
11.目标检测算法——收藏|小目标检测难点分析(二)
12.目标检测算法——收藏|小目标检测解决方案(三)
🌴 持续更新中……
🚀九、数据资源相关项目(持续更新中)🎄🎈
1.目标检测算法——小目标检测相关数据集(附下载链接)
2.目标检测算法——3D公共数据集汇总(附下载链接)
3.目标检测算法——3D公共数据集汇总 2(附下载链接)
4.目标检测算法——行人检测&人群计数数据集汇总(附下载链接)
5.目标检测算法——遥感影像数据集资源汇总(附下载链接)
6.目标检测算法——自动驾驶开源数据集汇总(附下载链接)
7.目标检测算法——自动驾驶开源数据集汇总 2(附下载链接)
8.目标检测算法——图像分类开源数据集汇总(附下载链接)
9.目标检测算法——医学图像开源数据集汇总(附下载链接)
10.目标检测算法——工业缺陷数据集汇总1(附下载链接)
11.目标检测算法——工业缺陷数据集汇总2(附下载链接)
12.目标检测算法——垃圾分类数据集汇总(附下载链接)
13.目标检测算法——人脸识别数据集汇总(附下载链接)
14.目标检测算法——安全帽识别数据集(附下载链接)
15.目标检测算法——人体姿态估计数据集汇总(附下载链接)
16.目标检测算法——人体姿态估计数据集汇总 2(附下载链接)
17.目标检测算法——车辆牌照识别数据集汇总(附下载链接)
18.目标检测算法——车辆牌照识别数据集汇总 2(附下载链接)
19.收藏 | 机器学习公共数据集集锦(附下载链接)
20.目标检测算法——图像分割数据集汇总(附下载链接)
21.目标检测算法——图像分割数据集汇总 2(附下载链接)
22.收藏 | 自然语言处理(NLP)数据集汇总(附下载链接)
23.自然语言处理(NLP)数据集汇总 2(附下载链接)
24.自然语言处理(NLP)数据集汇总 3(附下载链接)
25.自然语言处理(NLP)数据集汇总 4(附下载链接)
🌴 持续更新中……
🚀十、论文投稿相关项目(持续更新中)🎄🎈
1.论文投稿指南——收藏|SCI论文投稿注意事项(提高命中率)
2.论文投稿指南——收藏|SCI论文怎么投?(Accepted)
3.论文投稿指南——收藏|SCI写作投稿发表全流程
4.论文投稿指南——收藏|如何选择SCI期刊(含选刊必备神器)
5.论文投稿指南——SCI选刊
6.论文投稿指南——SCI投稿各阶段邮件模板
7.人工智能前沿——深度学习热门领域(确定选题及研究方向)
8.人工智能前沿——2022年最流行的十大AI技术
9.人工智能前沿——未来AI技术的五大应用领域
10.人工智能前沿——无人自动驾驶技术
11.人工智能前沿——AI技术在医疗领域的应用
12.人工智能前沿——随需应变的未来大脑
13.目标检测算法——深度学习知识简要普及
14.目标检测算法——10种深度学习框架介绍
15.目标检测算法——为什么我选择PyTorch?
16.知识经验分享——超全激活函数解析(数学原理+优缺点)
17.知识经验分享——卷积神经网络(CNN)
18.海带软件分享——Office 2021全家桶安装教程(附报错解决方法)
19.海带软件分享——日常办公学习软件分享(收藏)
20.论文投稿指南——计算机视觉 (Computer Vision) 顶会归纳
21.论文投稿指南——中文核心期刊
22.论文投稿指南——计算机领域核心期刊
23.论文投稿指南——中文核心期刊推荐(计算机技术)
24.论文投稿指南——中文核心期刊推荐(计算机技术2)
25.论文投稿指南——中文核心期刊推荐(计算机技术3)
26.论文投稿指南——中文核心期刊推荐(电子、通信技术)
27.论文投稿指南——中文核心期刊推荐(电子、通信技术2)
28.论文投稿指南——中文核心期刊推荐(电子、通信技术3)
29.论文投稿指南——中文核心期刊推荐(机械、仪表工业)
30.论文投稿指南——中文核心期刊推荐(机械、仪表工业2)
31.论文投稿指南——中文核心期刊推荐(机械、仪表工业3)
32.论文投稿指南——中国(中文EI)期刊推荐(第1期)
33.论文投稿指南——中国(中文EI)期刊推荐(第2期)
34.论文投稿指南——中国(中文EI)期刊推荐(第3期)
35.论文投稿指南——中国(中文EI)期刊推荐(第4期)
36.论文投稿指南——中国(中文EI)期刊推荐(第5期)
37.论文投稿指南——中国(中文EI)期刊推荐(第6期)
38.论文投稿指南——中国(中文EI)期刊推荐(第7期)
39.论文投稿指南——中国(中文EI)期刊推荐(第8期)
40.【1】SCI易中期刊推荐——计算机方向(中科院3区)
41.【2】SCI易中期刊推荐——遥感图像领域(中科院2区)
42.【3】SCI易中期刊推荐——人工智能领域(中科院1区)
43.【4】SCI易中期刊推荐——神经科学研究(中科院4区)
44.【5】SCI易中期刊推荐——计算机科学(中科院2区)
45.【6】SCI易中期刊推荐——人工智能&神经科学&机器人学(中科院3区)
46.【7】SCI易中期刊推荐——计算机 | 人工智能(中科院4区)
47.【8】SCI易中期刊推荐——图像处理领域(中科院4区)
48.【9】SCI易中期刊推荐——工程技术-计算机:软件工程(中科院4区)
49.【10】SCI易中期刊推荐——工程技术-计算机:人工智能(中科院2区)
50.【11】SCI易中期刊推荐——计算机方向(中科院4区)
51.【12】SCI易中期刊推荐——计算机信息系统(中科院4区)
🌴 持续更新中……
关于YOLO改进及论文投稿可关注并留言博主的CSDN/QQ
>>>一起交流!互相学习!共同进步!<<<
本文转载自: https://blog.csdn.net/m0_53578855/article/details/127413048
版权归原作者 加勒比海带66 所有, 如有侵权,请联系我们删除。
版权归原作者 加勒比海带66 所有, 如有侵权,请联系我们删除。