
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
**🚀对毕设有任何疑问都可以问学长哦!**
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的桥梁裂缝检测系统

设计思路
一、课题背景与意义
裂缝的成因复杂,具有较大的危害性,形状和走向无规律性,一般呈现多种形态和大小。若裂缝缺陷检测和修复不及时,可能会导致桥梁重大经济损失以及威胁生命安全。因此,早期发现和确定桥梁裂缝,以便进行精确的养护,具有特别重要性。深度学习作为近年来的热点和有效的监督学习方法之一,为桥梁裂缝检测带来了显著的提升。深度学习具有强大的特征提取和泛化能力,以及高鲁棒性和可靠性。
二、算法理论原理
2.1 卷积神经网络
YOLO作为一种用于多目标检测的深度学习框架,模型体积小,计算速度快,将检测问题转化为回归问题,整个图作为网络的输入。YOLOv5网络是由YOLOv4和YOLOv3演化而来的一种典型的单级目标检测算法,检测精度高,实时性好。YOLOv5s网络结构分为输入端、骨干端、颈部和检测端。
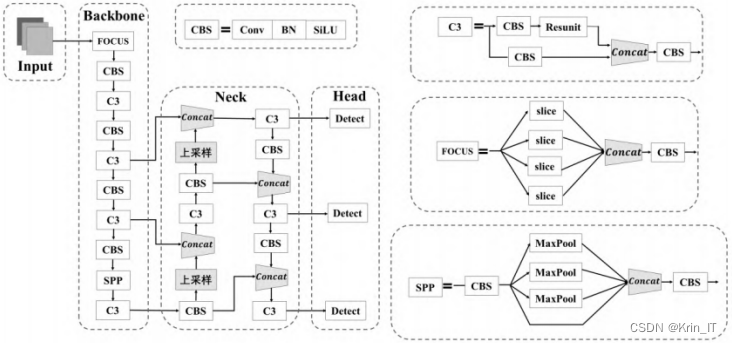
2.1 YOLOv5算法
在目标检测任务中,注意力机制主要作用于特征映射,通过先后生成通道和空间两个独立维度的注意映射,生成二维注意评分映射并应用到输入特征映射上,最后自适应特征细化。种轻量级嵌入式模块,结构由Split、Fuse、Select三部分组成。Split部分对维度为C×H×W特征图X进行3×3、5×5的完整卷积操作,进而得到相同维度的不同特征图。
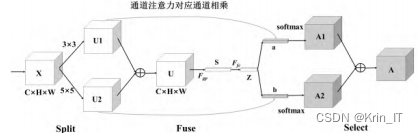
Fuse部分对两者进行信息融合操作得到同维度,进而通过全局平均池化与全连接层获取特征图的注意力信息,从而创建一个紧凑的特征,以便为精确和自适应地调整感受野的大小提供指导。Fuse部分计算公式如下所示:
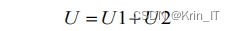
将两部分的特征图按元素求和得到U。
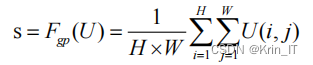
维度为C×H×W的特征图通过空间维度的全局平均池化操作生成通道统计信息,得到维度为C×1的特征图S。
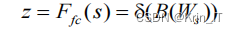
经过先降维再升维的FC全连接层生成紧凑的特征(维度为d×1,d<C),δ是ReLU激活函数,表示批标准化(BN),的维度为卷积核的个数,维度为d×C,d代表全连接后的特征维度。
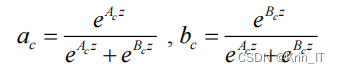
桥梁裂缝检测过程中,图像的背景复杂,这引入了相当大的背景噪音,且裂缝形状和大小的规格并不固定,目标规格差异,给检测带来了一定的困难。裂缝检测模型需要一个强大的特征融合模块。然而,原YOLOv5s模型中FPN-PAN结构存在多尺度特征融合不足的问题,一般的特征融合方法虽可以丰富整体的特征信息,但不同维度之间往往存在预测冲突,因此在特征融合部分增加ASFF结构,自主学习每个尺度的空间权重,实现图像多尺度特征的充分融合。
YOLOv5s网络中的Neck部分输出得到三个特征层Leavl1、Leavl2、Leavl3。权重参数α、β和γ与不同特征层相乘之后相加得到新的融合特征ASFF-1、ASFF-2、ASFF-3。以ASFF-1为例,公式如下所示:
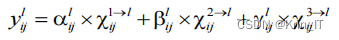
三、桥梁裂缝检测的实现
3.1 数据集
由于桥梁裂缝检测没有公开可访问的数据集,为了验证提出的目标检测模型,利用高清数码相机收集了钢筋混凝土施工桥梁表面不同位置的裂缝图像数据。为了数据集的完整性,数据图像包括不同光照、天气条件和遮挡阴影下的缺陷图像,共计筛选出1,500张照片。经过数据相似度比较,将收集到的桥梁裂缝图像与部分质量较好的裂缝图像合并,共计1,000张。

为了使目标检测模型更加有效,通过几何变换、光学变换等数据增强技术丰富桥梁裂缝数据集,完成裂缝检测数据集的构建,最终共计得到5,000张桥梁裂缝图像,按7:3分为训练集和验证集。
3.2 模型训练
模型的训练与测试都在同一设备进行,使用的软硬件工具包括处理器AMD Ryzen 9 3950X、内存64GB、系统Windows 10和开发环境torch 1.7.0。根据服务器内存和显卡配置,设定迭代次数(epoch)为200来评估指标和可视化效果,批次(batch size)为16,初始学习率为0.01,最小学习率为0.001。
在目标检测中,评价模型性能的标准有很多。采用准确率(Precision)、召回率(Recall)、平均精度均值(mean Average Precision)和F1四个性能指标来评价模型。
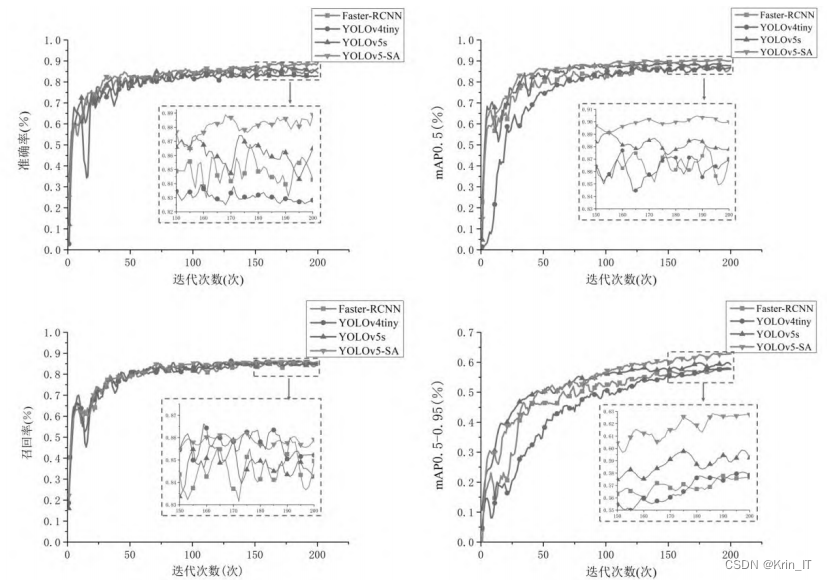
在前50次迭代中,各模型拟合较快,损失值明显减小。改进后的模型最终稳定在0.017附近,而原始的YOLOv5s稳定在约0.021,其他模型的稳定值均高于改进后的模型。改进后的YOLOv5-SA模型曲线平滑,无明显波动,改进后的模型在特征提取方面更加高效,收敛速度更快,训练效率更高。
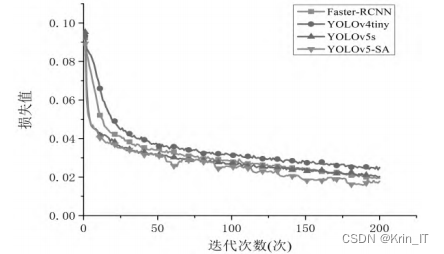
训练过程中准确率、召回率和mAP的变化趋势如图所示,与其他三种模型相比,可以观察到改进后的模型各检测指标正在稳步增加。在相同的数据集下,YOLOv5-SA网络的收敛速度最快,模型检验准确率高于原始模型及其他模型。对于mAP0.5和mAP0.5-0.95,从图中可看出,改进后的YOLOv5-SA模型在这些指标上排名最高。
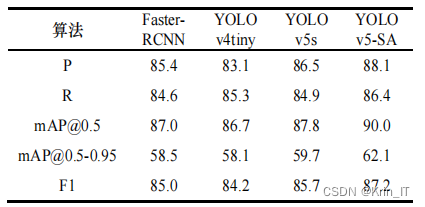
表中显示了四种模型的具体结果比较,改进后的YOLOv5-SA模型在mAP0.5-0.95上达到62.1%,
部分代码如下:
# 定义类别标签
class_labels = ['Crack']
# 加载待检测的桥梁图像
image_path = 'path/to/image.jpg'
image = Image.open(image_path)
# 对图像进行预处理
preprocessed_image = model.preprocess(image)
# 将预处理后的图像传入模型进行推理
output = model.predict(preprocessed_image)
# 解析模型输出,获取检测结果
predictions = output.pandas().xyxy[0]
# 遍历每个预测结果
for _, prediction in predictions.iterrows():
class_label = class_labels[int(prediction['class'])]
confidence = prediction['confidence']
bbox = prediction[['xmin', 'ymin', 'xmax', 'ymax']].values.tolist()
实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/qq_37340229/article/details/135092646
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。