【已解决】onnx无法找到CUDA的路径
环境变量没问题的话,一般就是cudnn和cuda以及oxxn的版本不匹配。查看好自己cudnn和cuda对应oxxn版本后,输入这个。换成你需要的版本,如我是cuda12.x以及cudnn8.x。oxnn找到了gpu,但是还是不能调用。
AI:237-改进 YOLOv8涨点 | 基于自适应特征金字塔网络(AFPN)的创新提升
本文深入探讨了如何将自适应特征金字塔网络(AFPN)集成到 YOLOv8 中,以提升目标检测的性能。AFPN 作为一种改进的特征融合方法,通过多尺度特征融合和动态特征重标定,显著增强了 YOLOv8 在复杂场景和小目标检测中的表现。AFPN 的核心概念与改进特征金字塔网络(FPN): AFPN 在传
江大白 | 视觉Transformer与Mamba的创新改进,完美融合(附论文及源码)
在本文中,作者引入了MambaVision,这是首个专门为视觉应用设计的Mamba-Transformer混合骨架。作者提出了重新设计Mamba公式的方法,以增强全局上下文表示的学习能力,并进行了混合设计集成模式的综合研究。
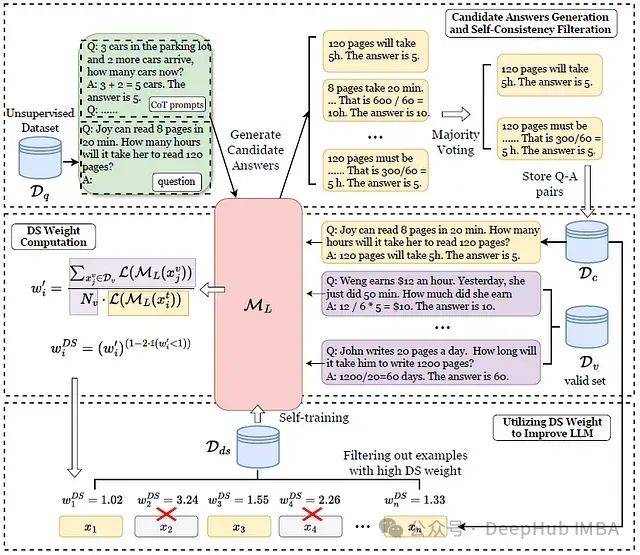
基于重要性加权的LLM自我改进:考虑分布偏移的新框架
在这篇论文中,证明过滤掉正确但具有高分布偏移程度(DSE)的样本也可以有利于自我改进的结果。
一文彻底搞懂Transformer - Add & Norm(残差连接和层归一化)
在Transformer模型中,Add & Norm(残差连接和层归一化)是两个重要的组成部分,它们共同作用于模型的各个层中,以提高模型的训练效率和性能。网络退化:网络退化(Degradation)是深度学习中一个常见的现象,特别是在构建深层神经网络时更为显著。它指的是在网络模型可以收敛的情况下,随
催化反应产率预测赛题--Datawhale AI夏令营
碳氮成键反应、Diels-Alder环加成反应等一系列催化合成反应,被广泛应用于各类药物的生产合成中。研究人员与产业界在针对特定反应类型开发新的催化合成方法时,往往追求以高产率获得目标产物,也即开发高活性的催化反应体系,以提升原子经济性,减少资源的浪费与环境污染。然而,开发具有高活性的催化反应体系通
AI:39-基于深度学习的车牌识别检测
从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。📌📌📌本专栏包含以下学习方向:机器学习、深度学习、自然语言处理(NLP)、机器视觉、语音识别、强化学习、推荐系统、机器学习
人工智能全景图2.0 | 一文了解人工智能学科
如果你对人工智能感兴趣,不妨来看看人工智能学科的全景地图!
[论文精读] StyleGAN2 论文&代码理解 (上)
精读这篇文章的原来还是来自于一些工作中的启发,人脸修复算法(face restoration)效果较好的基于可以分为3个流派,一种基于stylegan先验的GFPGAN、GPEN等,另外两种分别是基于transform和diffusion。而基于stylegan的方式通常都是采用 stylegan2
【深度学习】“复杂场景下基于深度学习的卷积神经网络在鸟类多类别识别中的模型设计与性能优化研究“(上)
本研究旨在探索基于深度学习的卷积神经网络在鸟类多类别识别中的应用潜力,通过深入分析模型设计和性能优化的方法,以应对复杂环境带来的挑战。通过系统的实验验证和性能评估,本研究试图为解决实际应用中的识别难题提供创新的解决方案和理论支持。
002-FFN(前馈神经网络)和MLP(多层感知器)的介绍及对比
FFN(前馈神经网络)与MLP(多层感知器)的介绍与对比
Yolo-World在基于自己的数据集训练后zero-shot能力显著下降甚至消失的问题
关于yolo-world的零样本检测能力问题
全球最强AI程序员 “Genie” 横空出世
Genie是迄今为止世界上最好的 AI 程序员。Genie启动。cosine.sh。
【大模型】 智谱 AI 的 GLM-4 来了,26 种语言支持,最高支持 1M 上下文长度(约 200 万中文字符)
智谱 AI 的 GLM-4 来了,26 种语言支持,最高支持 1M 上下文长度(约 200 万中文字符)
丹摩智算:如何在云端开发一个AI应用——基于UNet的眼底血管分割案例
丹摩智算低价狂欢节开始,4090、显示器等神秘好礼等待大家!
MaskRCNN 在 Windows 上的部署教程
在’train’模式下,主要关注dataset、weights和logs参数,确保它们正确指向了训练所需的数据集、权重文件和日志目录。在’splash’模式下,除了上述参数外,还需要关注image或video参数,确保它们正确指向了要检测的目标图像或视频文件。同时,weights参数应指向一个已训练
Transformer——逐步详解架构和完整代码搭建
Transformer是一个经典的编码解码结构,编码器decoder负责编码,解码器encoder负责解码。Transformer是基于seq2seq的架构,提出时被用在机器翻译任务上,后面变种Swin Transformer和Vision Transformer让其在CV领域也大放异彩。
Qwen2-57B-A14B预训练
Qwen2-57B-A14B作为一个强大的MoE模型,在保持较小激活参数规模的同时,实现了优秀的性能表现,为大规模语言模型的应用提供了新的可能性。任务中表现优异,超越了当前主流的MoE开源模型。SwiGLU激活函数。
使用TensorRT进行加速推理(示例+代码)
TensorRT 是 NVIDIA 开发的一款高性能深度学习推理引擎,旨在优化神经网络模型并加速其在 NVIDIA GPU 上的推理性能。它支持多种深度学习框架,并提供一系列优化技术,以实现更高的吞吐量和更低的延迟。TensorRT(NVIDIA Tensor Runtime)是由 NVIDIA 开
药品包装或质量控制
这段代码是一个完整的工作流程,从图像的读取、预处理、特征提取、分类器训练、分类、后处理到结果展示。它适用于自动化药片识别和分类的场景,例如在药品包装或质量控制中。



