
精确分割在当今众多领域都是一项关键需求比如说自动驾驶汽车的训练、医学图像识别系统,以及通过卫星图像进行监测。在许多其他领域,当感兴趣的对象微小但至关重要时,例如研究血管流动、手术规划、检测建筑结构中的裂缝或优化路线规划,需要更高的精度。此前已经做了大量工作来解决这种具有挑战性的分割问题。
此前已经做了大量工作来解决这种具有挑战性的分割问题。深度学习和神经网络的进步,例如[U-Net]及其变体,极大地提高了分割精度。“那还有什么问题呢?”所有这些方法在分割微小、细长和曲线结构方面表现不佳。根据研究,这可能是损失函数的一个问题

上面是来自不同数据库的包含示例,(a)卫星图像中的道路,(b)视网膜血管,©混凝土裂缝,(d)面部CT扫描的下牙槽管,(e)[圆]动脉
深度学习网络使用了最先进的损失算法,比如centerline-Dice或cl- dice,但是他们的计算成本非常大,在大容量和多类分割问题,即使在现代gpu,也表现得不好。
这篇论文则介绍了一个新的损失:Skeleton Recall Loss,我把它翻译成骨架召回损失.这个损失目前获得了最先进的整体性能,并且通过取代密集的计算他的计算开销减少超过90% !
为了说明这篇论文的损失函数,我们先介绍一下目前用于分割的损失函数
分割是如何工作的?
分割是将数字图像分成更简单的区域的过程,在以前都是使用传统的图像特征技术来实现,但是U-Nets(一种卷积神经网络)架构发表彻底改变了这一点。他以快速、高度准确、适应性强、效率高而著称,并且他的变体到现在还是目前最好的深度神经网络分割框架。
该体系结构包括:
压缩路径(Encoder) -下行采样并捕获输入图像的特征
一个对称的扩展路径(Decoder) -从收缩阶段学习到的特征重建下采样图像
U-Net体系结构的一个关键特征是跳过连接,它可以改进梯度流的编码器和解码器子网络,并帮助保存空间信。

U-Nets通常使用损失函数如下:
交叉熵损失-测量预测概率和真实类别标签之间的差异,惩罚不准确的预测
Dice 系数损失-衡量预测和真实片段之间的重叠,惩罚不相似
对Dice损失的修改称为centerline-Dice,交叉熵很好理解,并且在分类任务中非常常用,所以我们这里主要介绍Dice损失
Dice损失
Dice相似性系数度量两个集合之间的相似性。在图像分割方面,它测量预测之间的重叠

上面是Dice系数的公式,其中A和B是集合,预测和真值分割中的像素,以及A∩B表示两个集合的交点。对于这个度量,值“1”表示完全重叠,值“0”表示无重叠。
为了使它作为损失函数,随着模型的改进而减小,不同版本的骰子损失被称为“软Dice损失”被定义为
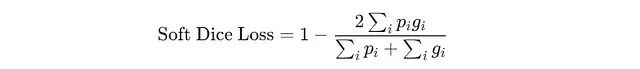
软Dice损失的公式中p(i)和g(i)分别是像素i的预测概率和真值的标签,N是被分割的像素总数。为了进一步提高分割精度,后来又引入了cl-Dice。
cl-Dice
Centerline-Dice(cl-Dice)是一个将传统的Dice系数损失与分割结构的骨架或中心线相结合的度量。
这里的术语“骨架 skeleton”是指代表管状结构的中心路径或连接性的一像素宽的线。由于原始的骨架化方法在数学上是不可微的,因此使用了一种称为“软骨架化”的近似骨架化方法。
这种方法是可微的(使用最小和最大池算子与ReLU迭代),这对神经网络训练至关重要。
所以这种损失被称为软cl-Dice损失。
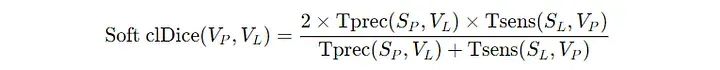
软cl-Dice系数公式,其中T(prec)和T(sens)分别表示拓扑精度和拓扑灵敏度
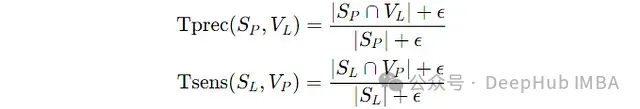
T(prec)和T(sens)的计算方法如下:其中S§和S(L)分别是预测的和真实的分割掩码的骨架,V§和V(L)分别是预测的和真实的分割掩码

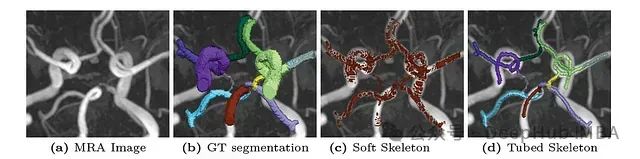
用于cl-Dice损失的可微分软骨架通常是锯齿状和穿孔的,导致分割不准确。
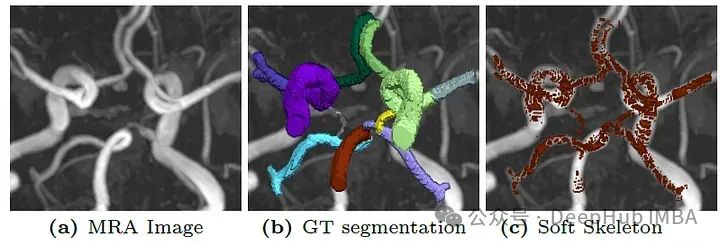
上图可以看到问题,并且cl-Dice损失的计算涉及到密集计算,这使得它不适合大型3D数据集和多类分割问题。
Skeleton Recall Loss
Skeleton Recall Loss的设计目的是在分割过程中保持细管结构的连通性,同时减少与此过程相关的计算开销。这种损失适用于任何深度学习分割网络,无论输入是2D还是3D。
上面我们已经说了导致这种计算效率损失的原因如下:
“使用骨架来保持连通性是一种有效的方法,但它不需要是可微分的。”
根据这一见解在真值上执行骨架化方法,而不是基于gpu的软骨架化。
它的工作流程如下::
1、二值化:将真值分割掩码(Y)转换为二值形式(Y_{bin}),其中前景和背景被明显标记。
2、骨架提取:使用前面的方法计算二值化掩码的骨架,用于2D和3D输入。
3、扩张:二值化后的骨架使用半径为2的菱形核进行扩张,使其成为管状。这增加了有效面积,并通过在骨架周围包含更多像素来稳定损失计算。
4、多类分配:对于多类分割问题,将管状骨架乘以原始的真值掩码 (Y),将骨架的不同部分分配到各自的类中。
伪代码如下所示。
Require: Y are K-classed hard targets where Y_{i,j,(,k)} ∈ [0, K]
1: Y_{bin} ← Y > 0 % Binarize to foreground and background labels
2: Y_{skel} ← skeletonize(Y_{bin}) % Extract binarized skeleton
3: Y_{skel} ← dilate(Y_{skel}) % Dilate to create tubed skeleton
4: Y_{mc-skel} ← Y_{skel} × Y % De-binarize to create multi-class tubed skeleton
5: return Y_{mc-skel}
上述所有操作在计算上都很轻量,而且可以在数据加载时通过CPU上执行。甚至可以使用像scikit-image这样的库预先计算
在骨架化之后,使用“软”(可微分)召回损失函数来激励神经网络预测尽可能多的管状骨架部分。这就是这篇论文介绍的 骨架召回损失:

其中Y(Skeleton)是管状骨架,Y^是预测的分割,C是类集,i是分割中的像素索引。下图展示了Skeleton Recall loss与之前最先进的loss的不同之处。
骨架召回损失的性能
这个新的损失在五个公共数据集上进行评估,这些数据集具有来自不同领域结构,包括二维和三维背景下的二分类和多类分割问题。
数据集如下:
1、带有二元标签的道路二维航拍道路图像
2、带有二进制标签的视网膜血管二维图像
3、混凝土结构上带有二元标签的裂缝的二维图像
4、牙槽管为目标结构的三维锥束CT图像,带有二值标记
5、脑血管圈内13种不同类型血管的3D CTA和MRA图像
作者通过与两个最先进的基线损失函数来进行对比:
cl-Dice Loss、Topo-clDice Loss
并使用了2个最先进的网络架构:
用于医学分割的nnUNet和用于自然图像的HRNet
通过改进nnUNet和HRNet上的Dice、clDice和Betti指标,Skeleton Recall Loss在多个数据集上始终优于clDice和Topo-clDice Loss,这表明它与体系结构无关。

上图是nnUNet结果

上图是HRNet结果
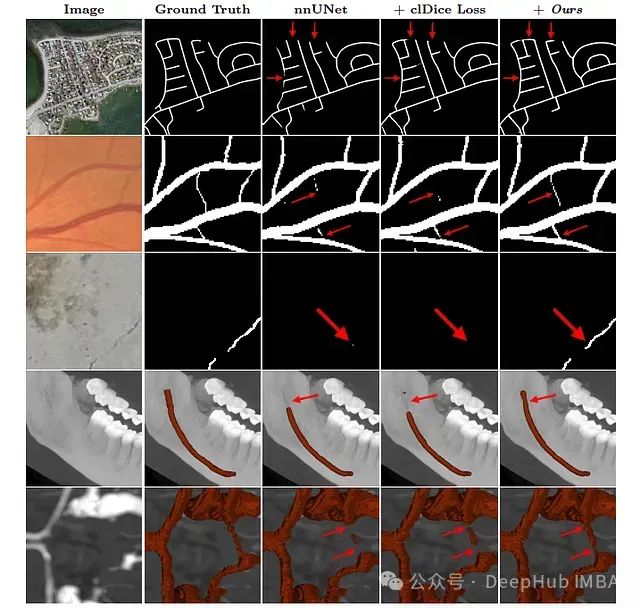
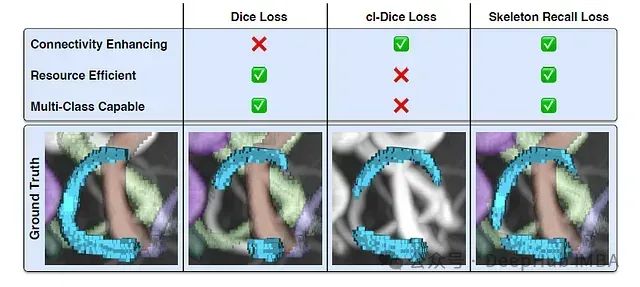
一些结果图片的展示
这个损失显示了改进的拓扑保存和增强的连接图像分割
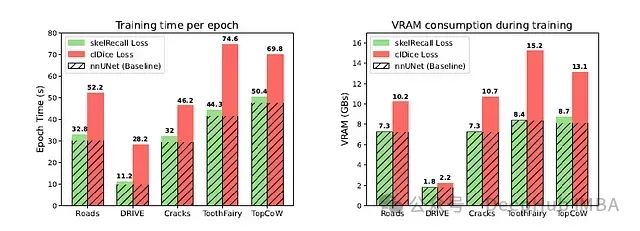
资源利用率
与普通nnUNet主干上的cl-Dice Loss相比,Skeleton Recall Loss最低限度地增加了VRAM使用量(2%)和训练时间(8%)。
Skeleton Recall Loss在多类分割方面表现出色,并且优于clDice Loss, clDice Loss由于高内存使用量(注意下面显示的out - memory错误)和随着类数量的增加而增加的训练时间而变得不可行的。
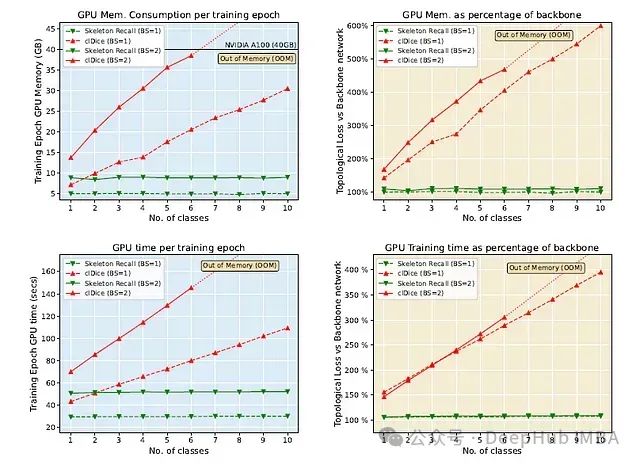
可以充分的显示Skeleton Recall Loss具有内存效率,可以最大限度地减少了训练时间,无缝集成到2D和3D分割的各种架构中,并且支持多类标签,而不会产生显著的计算开销。
论文地址:
https://avoid.overfit.cn/post/ddf618e45066433f9aca7447773bc61f
版权归原作者 deephub 所有, 如有侵权,请联系我们删除。