
PyTorch Profiler 性能优化示例:定位 TorchMetrics 收集瓶颈,提高 GPU 利用率
本文是将聚焦于指标收集,演示指标收集的一种简单实现如何对运行时性能产生负面影响,并探讨用于分析和优化它的工具与技术。
PyTorch生态系统中的连续深度学习:使用Torchdyn实现连续时间神经网络
神经常微分方程(Neural ODEs)是深度学习领域的创新性模型架构,它将神经网络的离散变换扩展为连续时间动力系统
TorchOptimizer:基于贝叶斯优化的PyTorch Lightning超参数调优框架
TorchOptimizer是一个集成了PyTorch Lightning框架和scikit-optimize贝叶斯优化功能的Python库。该框架通过高斯过程对目标函数进行建模,实现了高效的超参数搜索空间探索,并利用并行计算加速优化过程。
深度强化学习实战:训练DQN模型玩超级马里奥兄弟
本文将探讨深度学习在游戏领域的一个具体应用:构建一个能够自主学习并完成**超级马里奥兄弟**的游戏的智能系统。
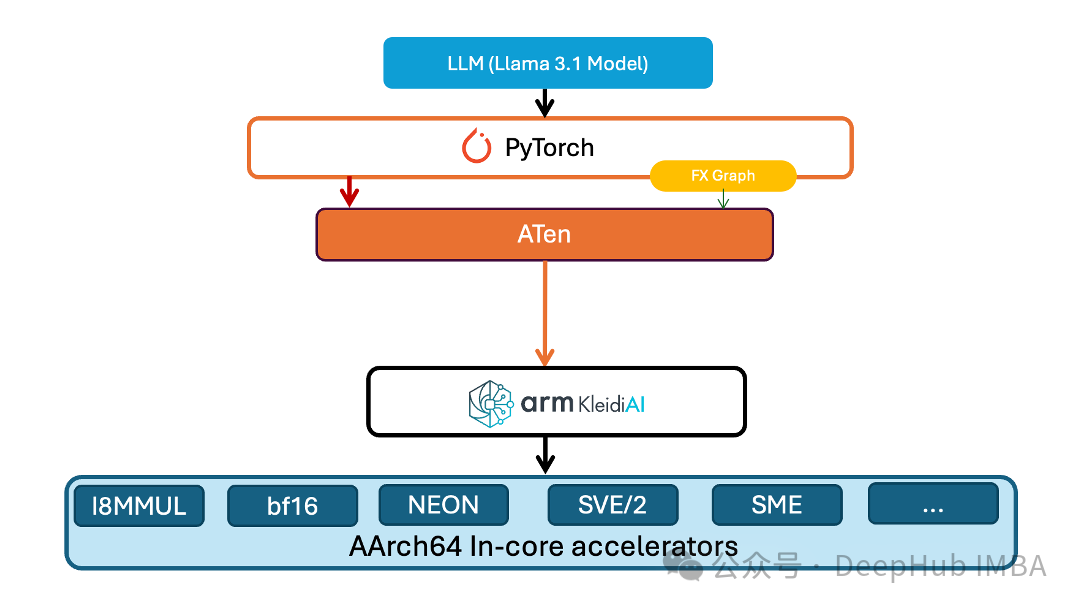
PyTorch团队为TorchAO引入1-8比特量化,提升ARM平台性能
PyTorch团队针对这一问题推出了创新性的技术方案——在其原生低精度计算库TorchAO中引入低位运算符支持。这一技术突破不仅实现了1至8位精度的嵌入层权重量化
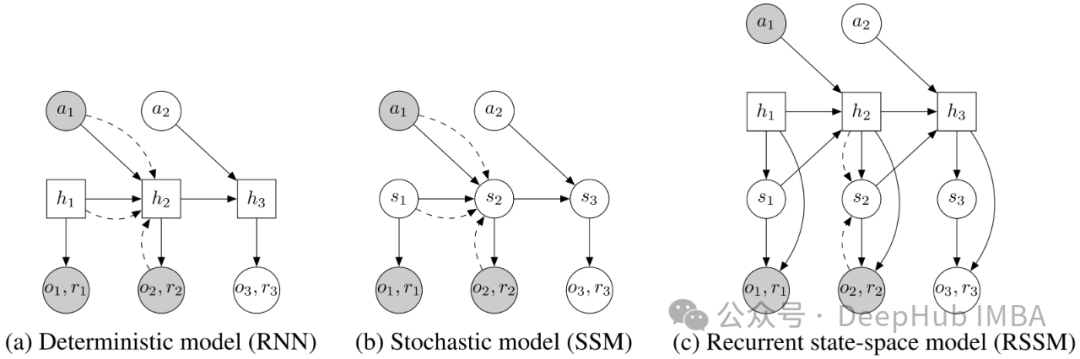
面向强化学习的状态空间建模:RSSM的介绍和PyTorch实现
循环状态空间模型(Recurrent State Space Models, RSSM)最初由 Danijar Hafer 等人在论文《Learning Latent Dynamics for Planning from Pixels》中提出。
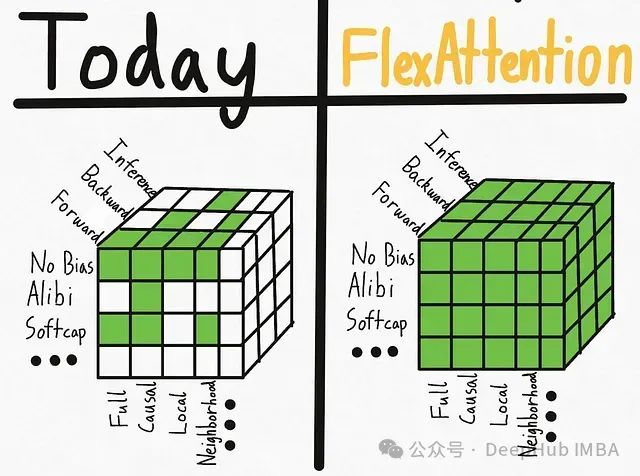
PyTorch FlexAttention技术实践:基于BlockMask实现因果注意力与变长序列处理
本文介绍了如何利用torch 2.5及以上版本中新引入的FlexAttention和BlockMask功能来实现因果注意力机制与填充输入的处理。
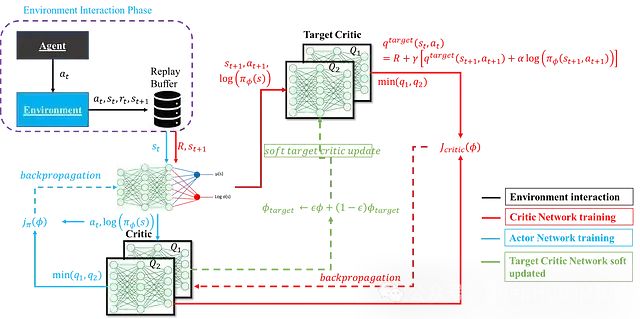
深度强化学习中SAC算法:数学原理、网络架构及其PyTorch实现
软演员-评论家算法(Soft Actor-Critic, SAC)因其在样本效率、探索效果和训练稳定性等方面的优异表现而备受关注。
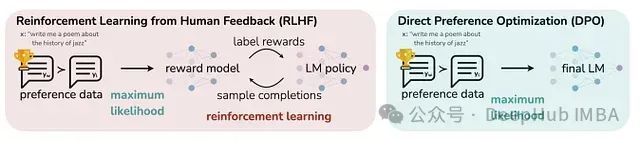
使用PyTorch实现GPT-2直接偏好优化训练:DPO方法改进及其与监督微调的效果对比
本文将探讨RLHF技术,特别聚焦于直接偏好优化(Direct Preference Optimization, DPO)方法,并详细阐述了一项实验研究:通过DPO对GPT-2 124M模型进行调优,同时与传统监督微调(Supervised Fine-tuning, SFT)方法进行对比分析。
【人工智能】基于PyTorch的深度强化学习入门:从DQN到PPO的实现与解析
深度强化学习(Deep Reinforcement Learning)是一种结合深度学习和强化学习的技术,适用于解决复杂的决策问题。深度Q网络(DQN)和近端策略优化(PPO)是其中两种经典的算法,被广泛应用于游戏、机器人控制等任务中。本文将从零讲解深度强化学习的基础概念,深入探讨DQN和PPO的核
【AI入门超详细系列】卷积神经网络(CNN)入门指南【Pytorch版】
大家好,我是默子!欢迎来到“默子AI”的世界。今天,我们将深入探索 PyTorch 的强大功能,学习如何使用卷积神经网络(CNN)识别图像数据。无论你是深度学习的新手,还是希望强化实践经验的开发者,这篇教程都将为你提供详尽的指导和深入的解说。准备好了吗?让我们一起开启这段充满干货与乐趣的学习之旅吧!
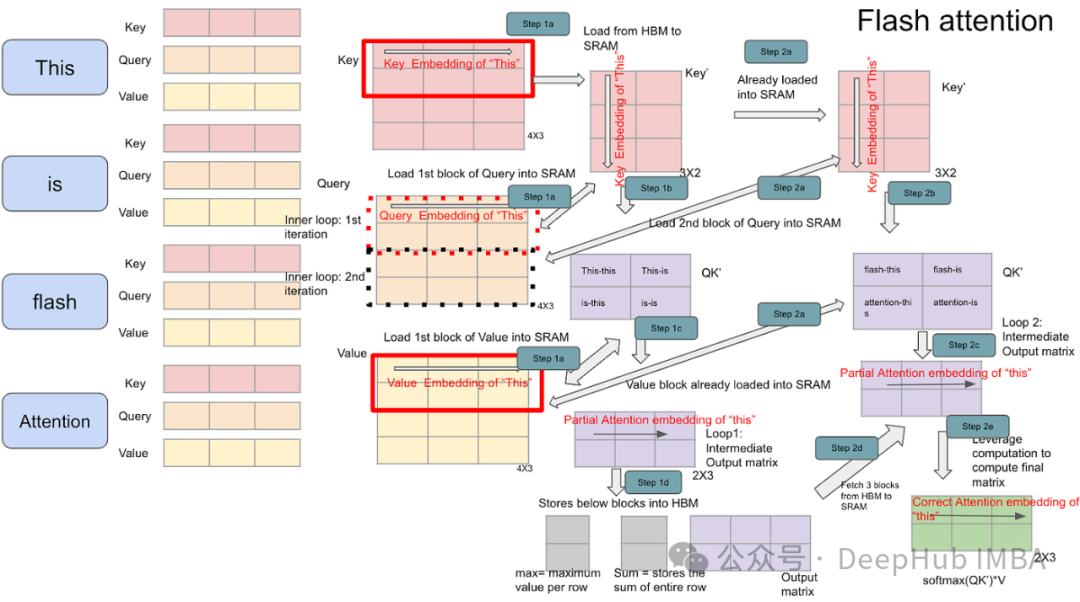
Transformer模型变长序列优化:解析PyTorch上的FlashAttention2与xFormers
本文将进一步探讨变长输入序列这一挑战——这是真实世界数据(如文档、代码、时间序列等)的固有特征。
【人工智能】深入理解PyTorch:从0开始完整教程!全文注解
PyTorch是一个开源的深度学习框架,由Facebook的AI研究团队开发。它提供了灵活的工具来构建和训练神经网络模型,广泛应用于计算机视觉、自然语言处理等领域。迁移学习是一种在预训练模型的基础上进行微调的方法,适用于数据量较少的任务。PyTorch提供了丰富的预训练模型,方便我们进行迁移学习。C
Ubuntu安装Cuda、PyTorch、TensorRT、OpenCV、Redis等AI推理环境
Ubuntu安装Cuda、CUDNN、PyTorch、TensorRT、Anaconda、OpenCV、Redis、yaml等AI推理环境
【人工智能】PyTorch、TensorFlow 和 Keras 全面解析与对比:深度学习框架的终极指南
本文将为你一一解答。为了更直观地了解三大框架的使用方式,下面我们将通过一个简单的手写数字识别(MNIST)任务,演示如何使用 PyTorch、TensorFlow 和 Keras 构建和训练一个基本的神经网络模型。通过以上简单的示例,我们可以看到,虽然三大框架在具体实现上有所不同,但总体流程相似,都
在Windows上离线安装指定版本的Pytorch(以CUDA11.8版本为例)
我们都知道,通过 pip或conda在线安装Pytorch是非常方便的 ,但是有时候网络环境受到限制,比如公司的工作站(无法连接网络)或者机房的教学机器等等,只能通过离线的方式安装Pytorch;今天就来记录一下离线安装Pytorch的过程。并记录了遇到的问题及解决过程。对于深度学习 环境搭建来说,
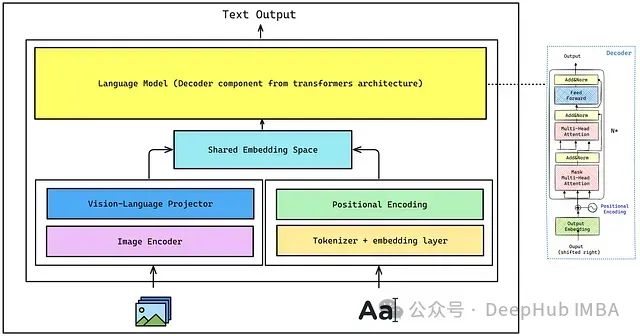
使用Pytorch构建视觉语言模型(VLM)
本文将介绍 VLM 的核心组件和实现细节,可以让你全面掌握这项前沿技术。我们的目标是理解并实现能够通过指令微调来执行有用任务的视觉语言模型。

使用 PyTorch-BigGraph 构建和部署大规模图嵌入的完整教程
本文深入探讨了使用 PyTorch-BigGraph (PBG) 构建和部署大规模图嵌入的完整流程,涵盖了从环境设置、数据准备、模型配置与训练,到高级优化技术、评估指标、部署策略以及实际案例研究等各个方面。
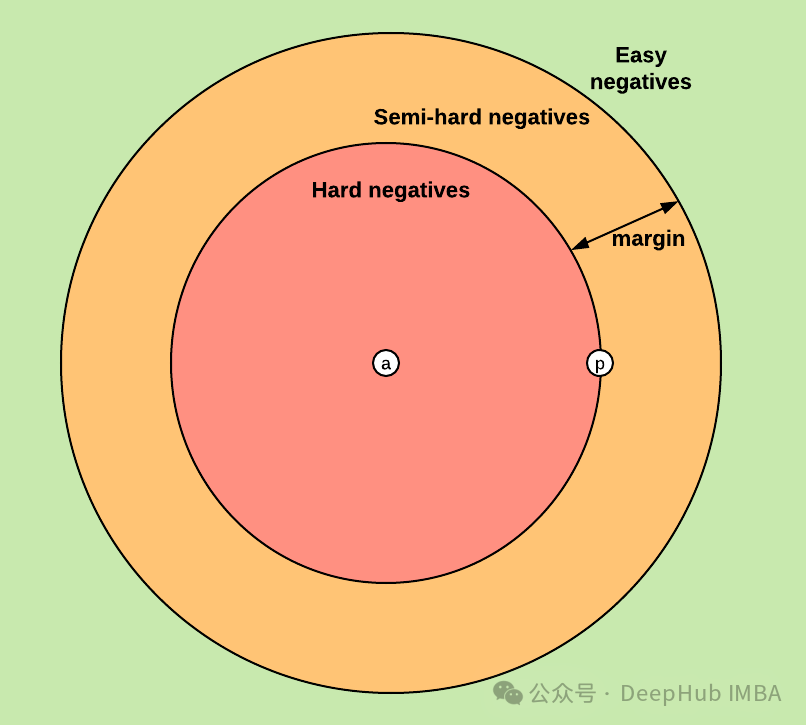
利用PyTorch的三元组损失Hard Triplet Loss进行嵌入模型微调
本文介绍如何使用 PyTorch 和三元组边缘损失 (Triplet Margin Loss) 微调嵌入模型,并重点阐述实现细节和代码示例



