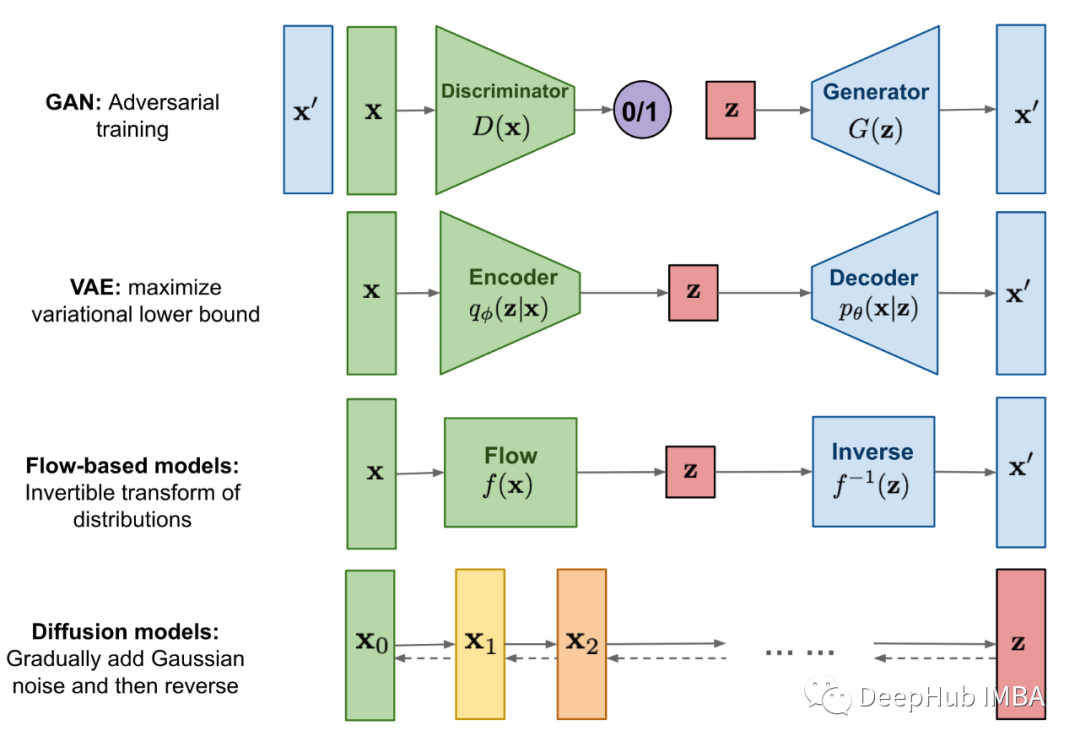
扩散模型的极简介绍
扩散模型是什么,如何工作以及他如何解决实际的问题
基于文化算法优化的神经网络预测研究(Matlab代码实现)
从两个层面分别模拟生物的进化和文化的进化,两个过程既相互独立又相互影响,是一种基于知识的双层进化系统。该算法优点就在于,可以从每次的搜索中提取解决问题的有效信息,并反馈指导种群的搜索过程,在精度和效率上都使算法有效提升。
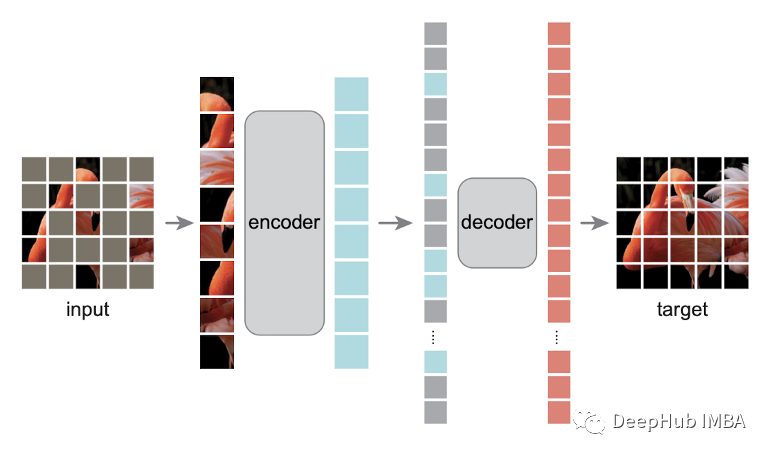
带掩码的自编码器MAE在各领域中的应用总结
NLP,图像,视频,多模态,设置时间序列和图机器学习中都出现了MAE的身影
猿创征文|深度学习基于前馈神经网络完成鸢尾花分类
在梯度下降法中,目标函数是整个训练集上的风险函数,这种方式称为批量梯度下降法(Batch Gradient Descent,BGD)。 批量梯度下降法在每次迭代时需要计算每个样本上损失函数的梯度并求和。当训练集中的样本数量NN很大时,空间复杂度比较高,每次迭代的计算开销也很大。为了减少每次迭代的计算

手把手教你深度学习和实战-----卷积神经网络
利用大量的图片来讲解卷积神经网络的原理
手把手带你调参Yolo v5 (v6.2)(三)
解析val.py文件中21个参数含义!
图神经网络(三):数学基础
图神经网络的数学基础
【深度学习】6-卷积过程中数据的结构变化
在学习卷积神经网络时,我对于卷积过程中数据的结构变化常感困惑不解(如改变数组的维度顺序),因此在这里做一些整理。

如何估算transformer模型的显存大小
本文将详细介绍如何计算transformer的内存占用

Pytorch中获取模型摘要的3种方法
在pytorch中获取模型的可训练和不可训练的参数,层名称,内核大小和数量。
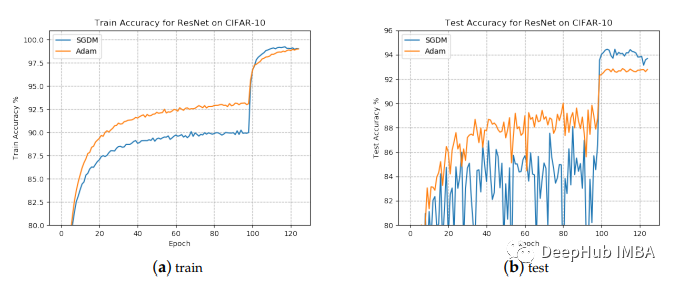
为什么Adam 不是默认的优化算法?
本文这并不是否定自适应梯度方法在神经网络框架中的学习参数的贡献。而是希望能够在使用Adam的同时实验SGD和其他非自适应梯度方法
处理医学时间序列中缺失数据的3种方法
这些方法都是专为RNN设计,它们都经过了广泛的学术评估,而且十分的简单
RepVGG :让卷积再次伟大
一个经典的卷积神经网络(ConvNet),VGG [31],在图像识别方面取得了巨大的成功,其简单的架构由一堆 conv、ReLU 和 pooling 组成。随着 Inception [33, 34, 32, 19]、ResNet [12] 和 DenseNet [17],许多研究兴趣转移到精心设计
【深度学习实践(八)】生成对抗网络(GAN)之手写数字生成
【深度学习实践(八)】生成对抗网络(GAN)之手写数字生成
神经网络案例编程实战
神经网络案例编程实战
【深度学习】笔记3-神经网络的学习
深度学习个人笔记,神经网络的学习
【数模智能算法】BP神经网络基本算法原理
【数模智能算法】BP神经网络基本算法原理

使用Dask,SBERT SPECTRE和Milvus构建自己的ARXIV论文相似性搜索引擎
通过矢量相似性搜索,可以在〜50ms内响应〜640K论文上的语义搜索查询
【深度学习实践(四)】识别验证码
【深度学习实践(四)】识别验证码



