
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
深度神经网络(deep neural Networks DNN)
深度的含义是什么呢,它的含义就是一个神经网络,有输入层,输出层,它也会有很多的隐藏层。深度神经网络就是我们隐藏层很多的神经网络。每一层里面都有neuron(神经元),神经元和神经元之间有神经键。
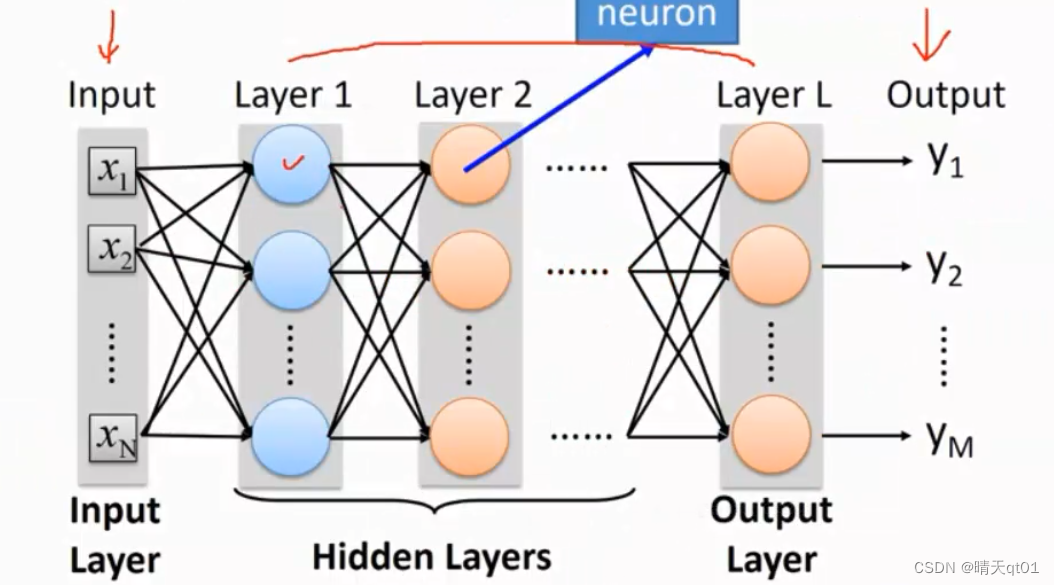
DNN的底层原理
那我们现在有一笔数据进来,是1和-1这个是输入层的两个神经元。 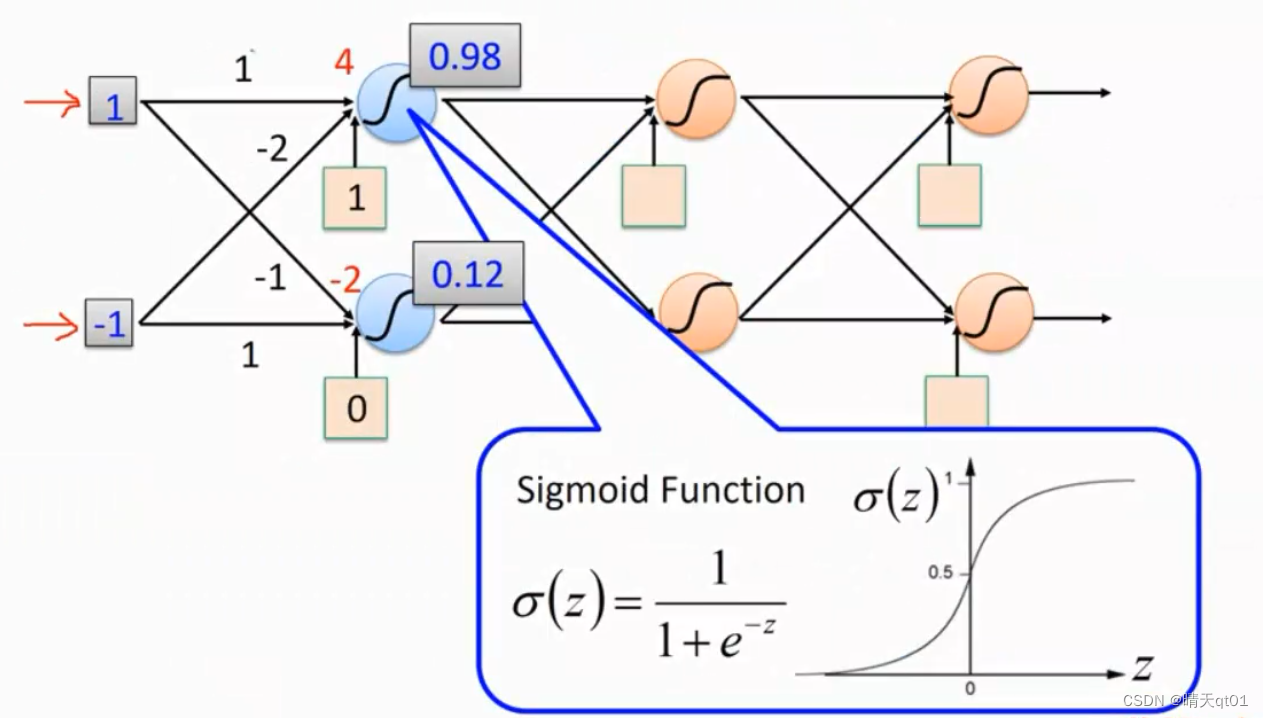
我们就会把这个神经元通过组合函数pass到隐藏中。绿色边框肉色底的方框1就是我们的偏置项bias,神经键上的数字就是权重值。
BP神经网络用的函数就是sigmoid function,函数中的变量就是我们的4,所以它会输出大于0.5的值,0.98
第二个隐藏层的神经元输出的就是0.12。这个就是我们之前说的BP神经网络。
然后继续按照权重值进入下一个隐藏层

因为我们用的函数是sigmoidfunction,所以最后概率总和就不会是1那么这就说明我们讨论问题的两个类别是互相独立的,可以第一个输出字段的神经元代表的是是否购买汽车杂志,第二个输出字段的神经元代表的是客户是否购买搞笑杂志。这两件事是独立分开,
如果希望输出字段的概率值累计求和为1的话,就要在最后一个隐藏层使用softmax函数。
这个就是一个普通深度学习的神经网络的基本架构
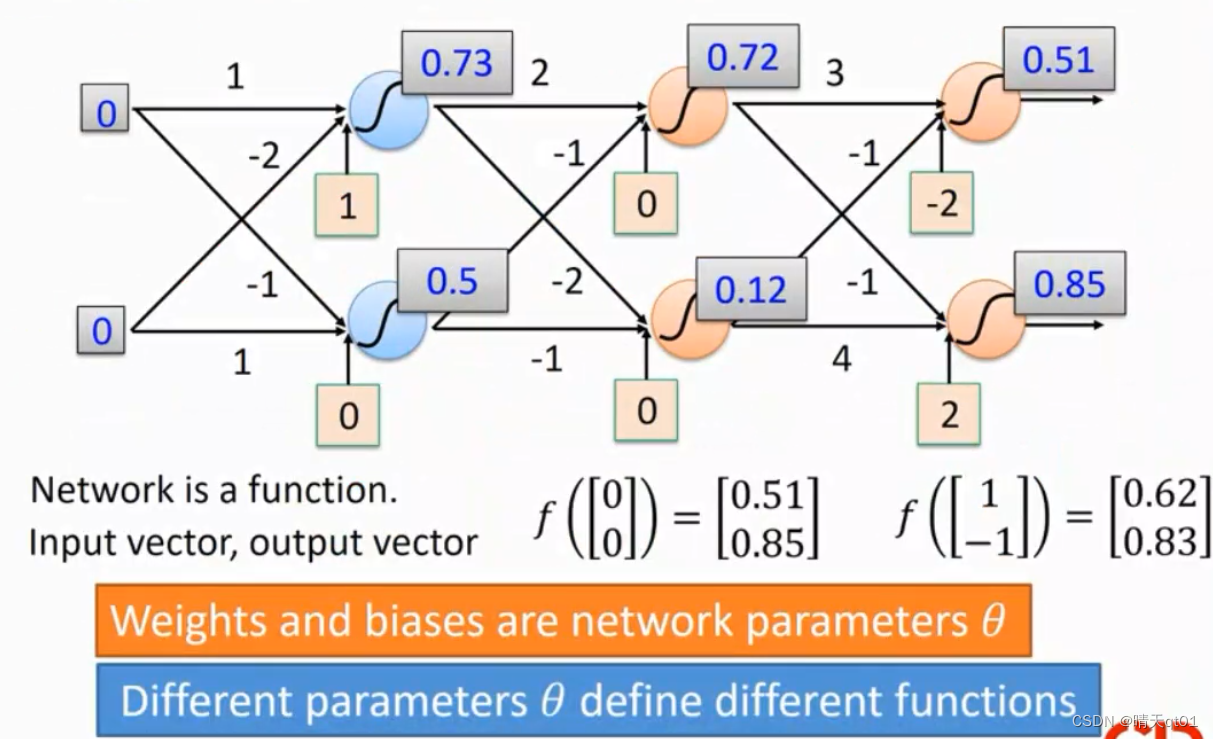
其实整个网络就是一个function(函数),我们有输入的向量【1,-1】,它这个函数(DNN)输出向量【0.62,0.83】
这个网络的参数有不同的权重和偏置项,如果不同的权重和偏置项就会产生不同的函数。
这个函数其实就是一连串的矩阵的运算。

我们可以看第一个隐藏层的前半部分,它代表了一个2*2的矩阵偏执项1,0也是一个向量。第一层神经网络会输出0.98,0.12,就是(输入矩阵和权重矩阵的乘积加上偏置项bias)代入到activation函数中。就会输出0.98,0.12
如果要把神经网络写的比较简单简化一点,我们把输出字段叫做ax-1权重设为Wx,偏置项设为bx,x代表层数。就可以得到下面的数学模型。也就是DNN的简化模型。
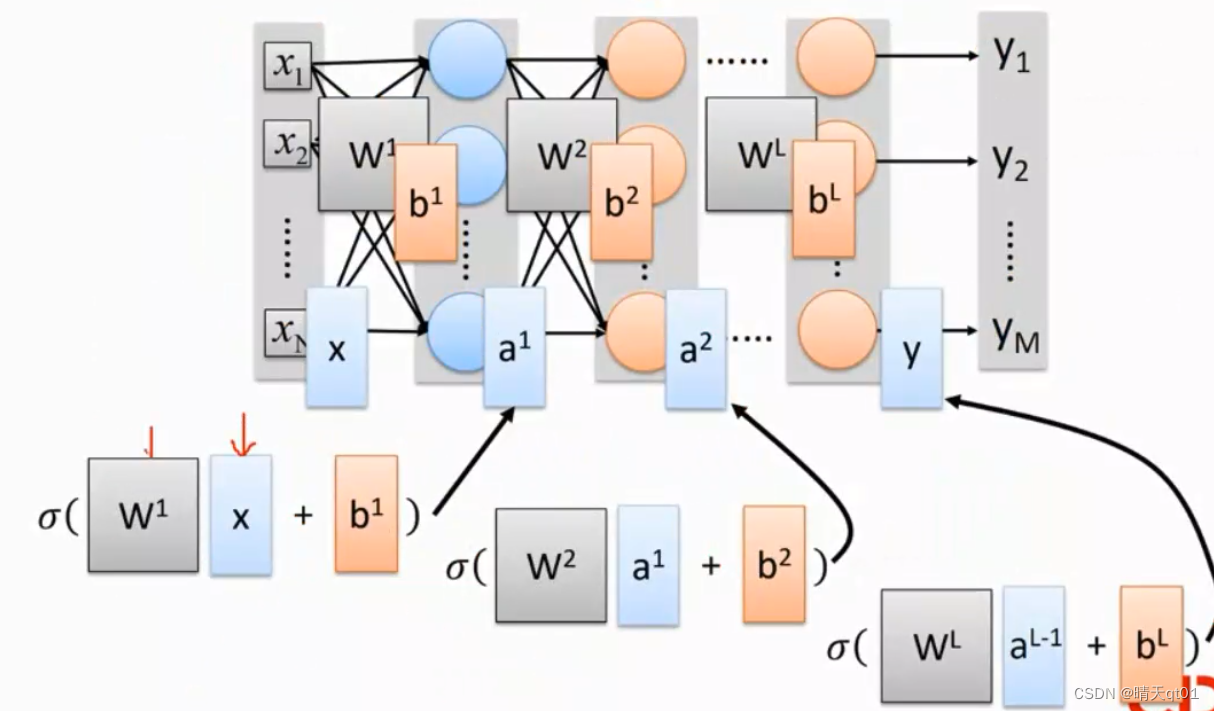
第一层输入结果就是x,第二层产生结果是a1
我们就可以把神经网络用比较平易近人的数学函数展示出来

所以我们就可以把它想象为一个非常复杂的非线性函数。
输出层:
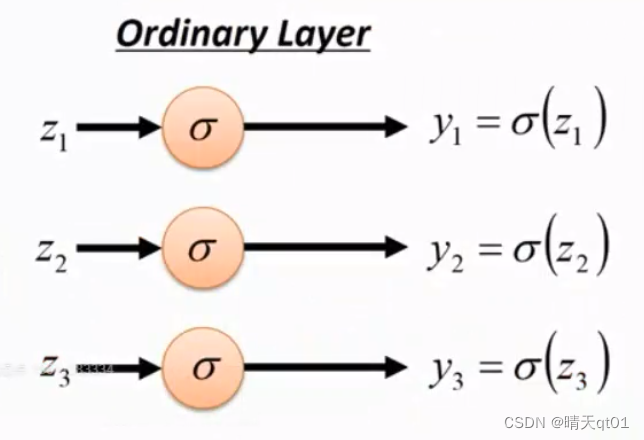
如果我们希望输出层总和为1的话,需要在最后一层的激活函数换成softmax function,也把它叫做softmax layer。如果按上图直接进行普通的sigmoid function激活函数处理,那就会导致3个事件是独立分开的。只不过在深度学习的网络。
输出层的结果只能是一个类别的话就要用softmax,做法如下。

第一个数值是e的3次方,20,e的1次方2.7,e的-3次方0.05。
我们把这3个数值 累加当做每个神经元的分母,然后各种的分子就用自然数为底,指数为组合函数(权重和偏执项)结果的幂。
这种情况,我们会把这一层叫做softmax layer,图示如下。

深度学习网络的问题:
到底要有多少层?每一层要有多少神经元?(这里的层都指隐藏层,)
能不能自动设定。因为传统神经网络我们都要自己去计算。
还不出现过拟合,现在有一个技术,比较火的议题叫AutoDL,这个自动深度学习,就可以解决这2个问题。之后有机会再和大家讲。
既然我们有了深度神经网络的知识现在就可以进行一个应用:
案例1:书写数字识别(梯度下降法详解)

现在这个是一个16*16的一个图。就是256的,这里面把输入字段只分为两种情况,有颜色就是1,无颜色就是0
事实上我们图像进来,一般黑色是0,白色是255,不过我们可以做装换,这题是无所谓,我们发现把输入字段放入,2的概率是0.7,概率最大,所以我们认为这张图像是2。这就是DNN做简单的书写数字识别,准确率能达到百分之95,96这样。当然之后用CNN能到98,99这样

输入是256个字段,输出是10个字段。我们现在就要考虑怎么去组建这个网络。产生这个函数。
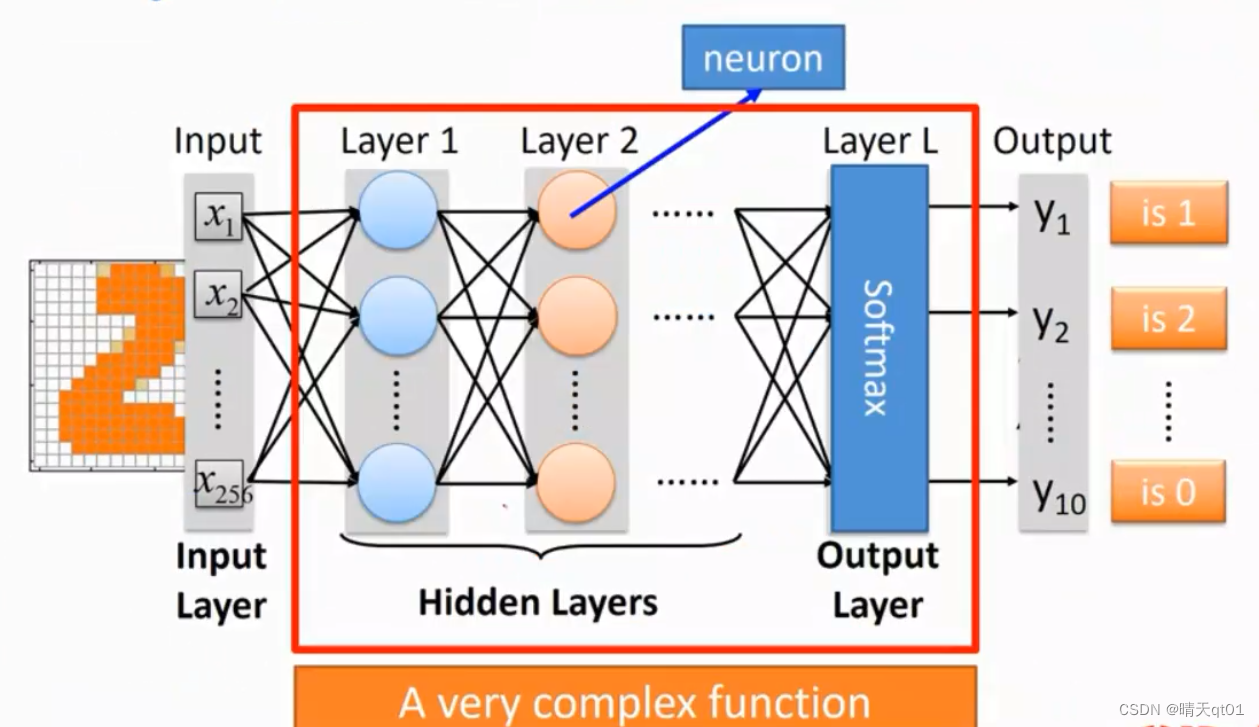
我们可以把这个中间的隐藏层与权重偏置项的关系看成一个非常复杂的函数。
我们要确定权重值和bias值的大小,目前是未知的

我们怎么去训练这个网络,让他得到最佳的权重值和偏置项,之前我们不是说过权重项和bias值的调整方法是backforward 就是BP网络里的调整方式。
一开始的权重值和偏置项会不那么准确。其他位置都是0.我们通过计算预测值与目标值的误差通过梯度下降法可以慢慢修正权重值

这里我们通过随机的权重值得到结果,利用模型得到的结果与目标字段的数值进行对比,求二者差平方square error,还有一个DNN提出的新误差模型cross entropy(效果比较好。),得到误差loss
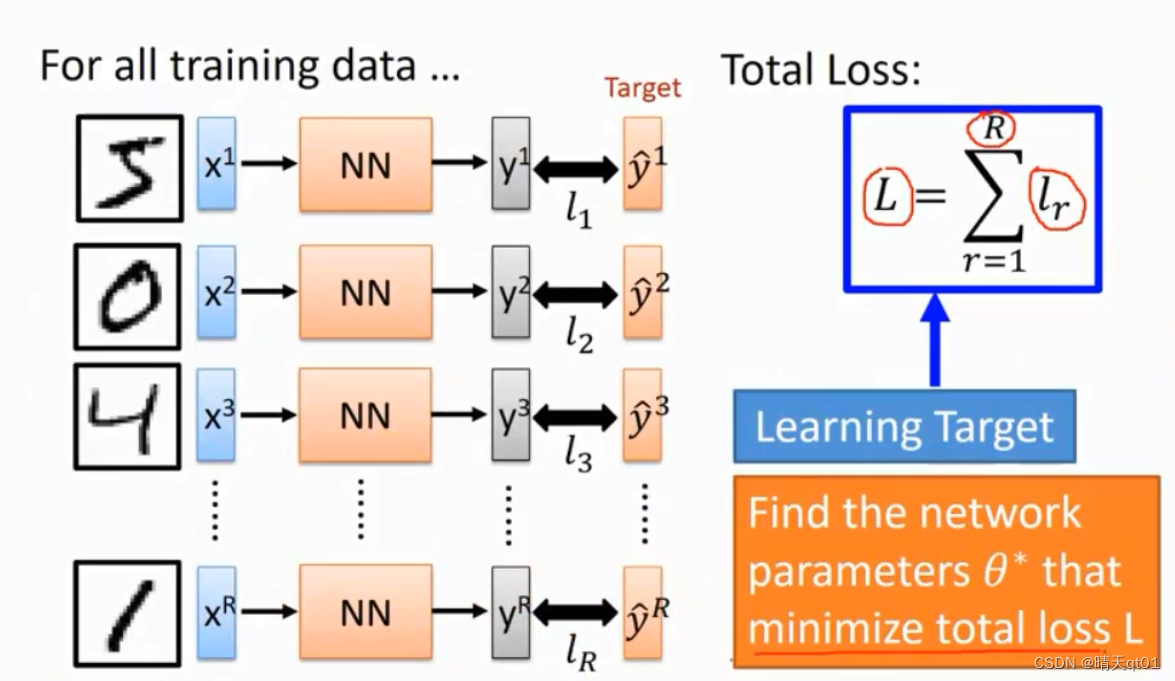
我们就可以得到误差L,L是总误差,每个小节点误差的求和。这就是神经网络在我们学习阶段需要考虑的事情。
在这里,如果你选择列出所以权重值来达到误差最小,是不可行的。比如第一层有1000个神经元,第二层有1000个神经元,那么神经键就有1000000万,一个一个试验,是不可能试出来的。
就拿之前最经典的8层的隐藏层,一层1000个神经元。如果一个一个去调是不可能的,所以我们采用了一个方法梯度下降法,
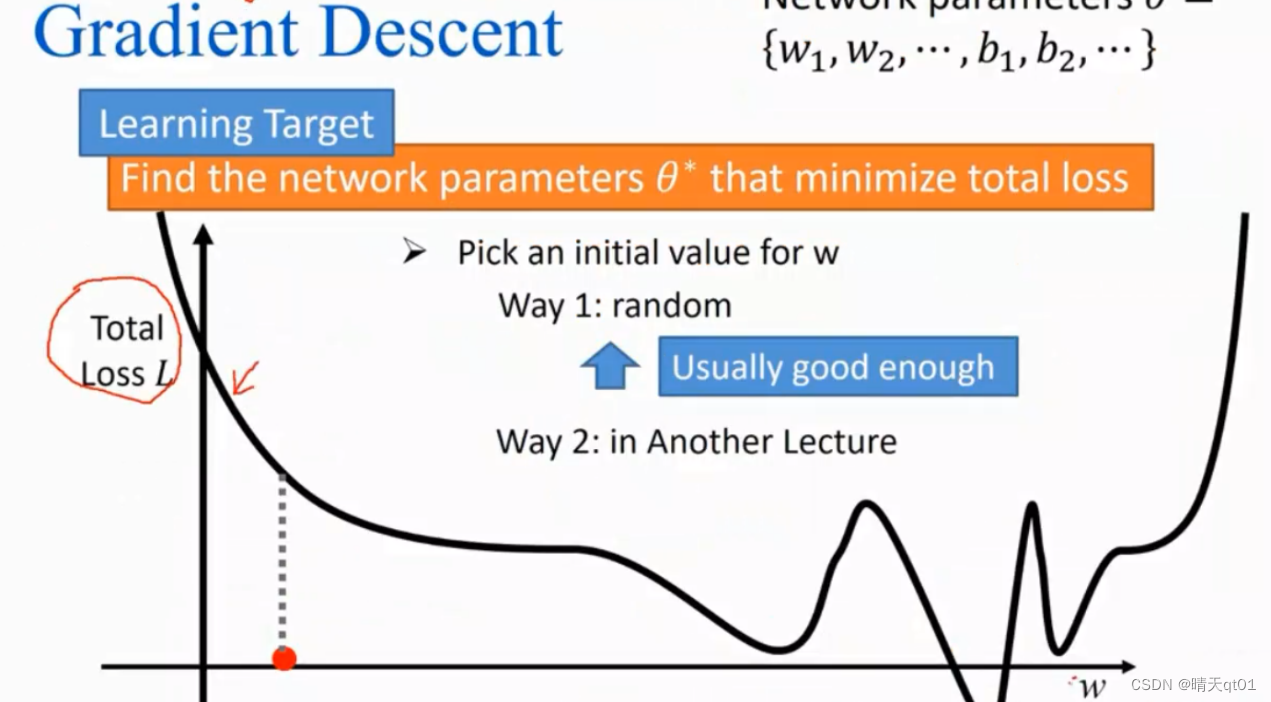
这图的x轴是权重,也就是随着权重的变化,误差会跟随着一起变化。我们的目标是误差的最低点。一开始我们随机设定一个权重值,还有一种方法是我们有方法的去设定一个权重值,那样会让我们收敛的速度更快。
然后我们求这点权重值的斜率,如果切点斜率是正的那就增加权重值,否则就减少权重值。

前面的倍数是我们的学习速率。斜率大的我们调整幅度就大,斜率小,调整幅度也会随之减少。
这边我们会发现,梯度下降法是只能区域最佳解。
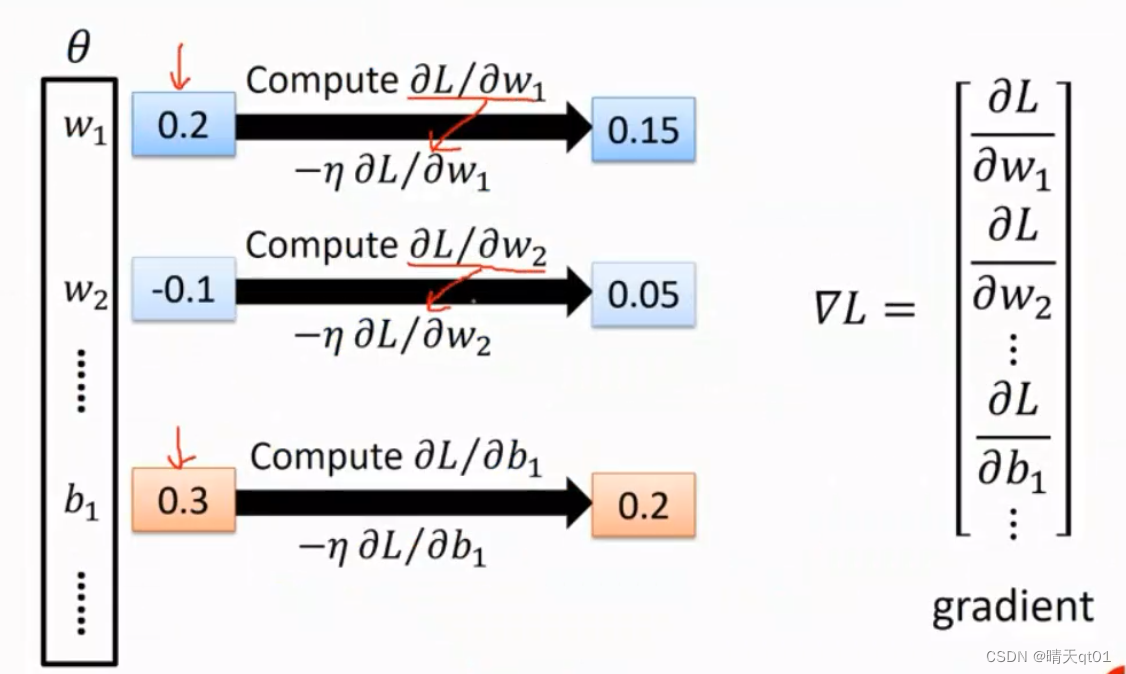
后面的值就是我们的梯度。Gradient
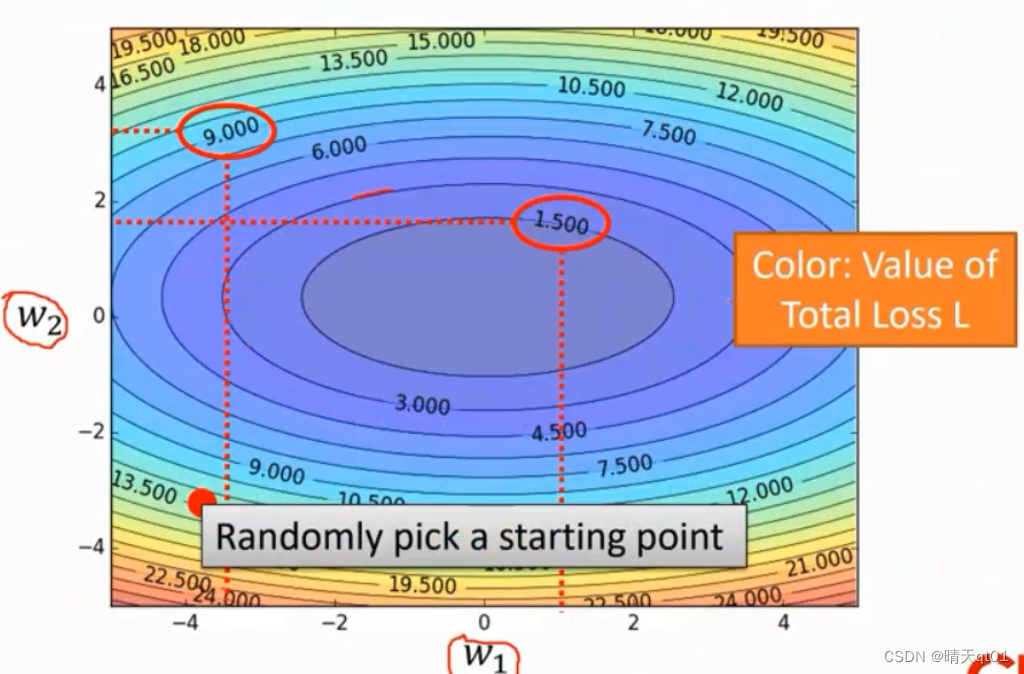
这是两个权重的对应的误差图。我们可以求出各自的斜率,各自独立进行调整。目标就是中间1.5的平面。

这边多个参数的情况考虑误差就分别独立考虑,它就会趋向于最佳值了。

我们权重和bias的梯度下降法的调整方法就好像我们在玩地形非常复杂的世纪帝国。希望找到最低的低谷,但是我们的视野只有上图的大小。梯度下降法的视野是非常小的情况,不能看到一个整体的样貌。Alpha go其实也是这么做。
实际上,我们来看误差图会发现,其实我们有很多坡谷的地方

我们无法保证可以得到一个全局的最佳解。一种比较简单的方法就是,我们采用几个不同的初始误差值这样就有可能达到全域最佳解。
能用DNN做些什么
比如我们输入图片的,要识别出是猫是狗。
也可以对文本进行分析,查看它是属于什么类型的文章。
也可以对声音进行分析识别。查看它的文本。我们发现隐藏层层数越多,错误率就越低
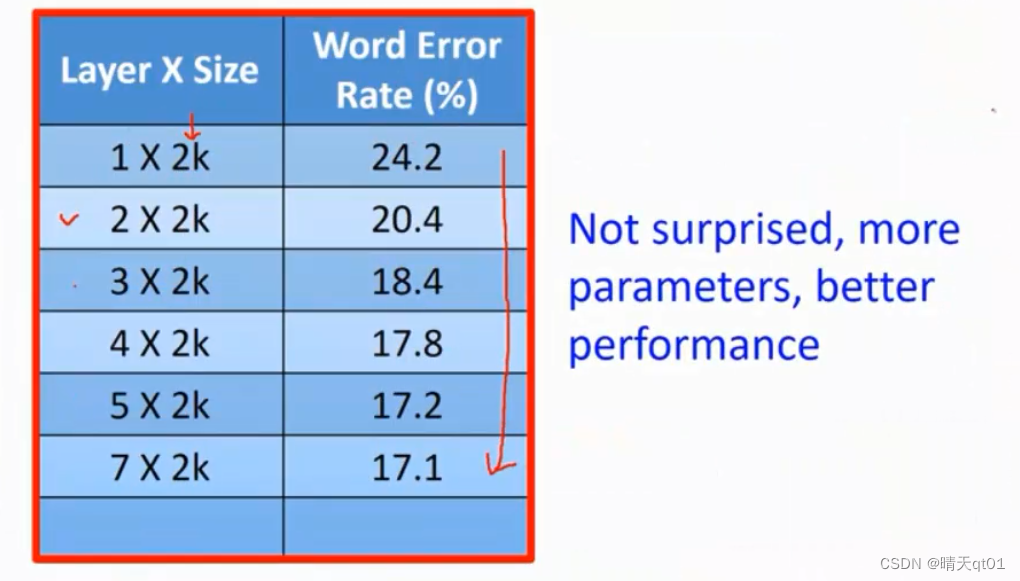
参数多和数据够多,层数多,结果更好。这个还不能看出什么。
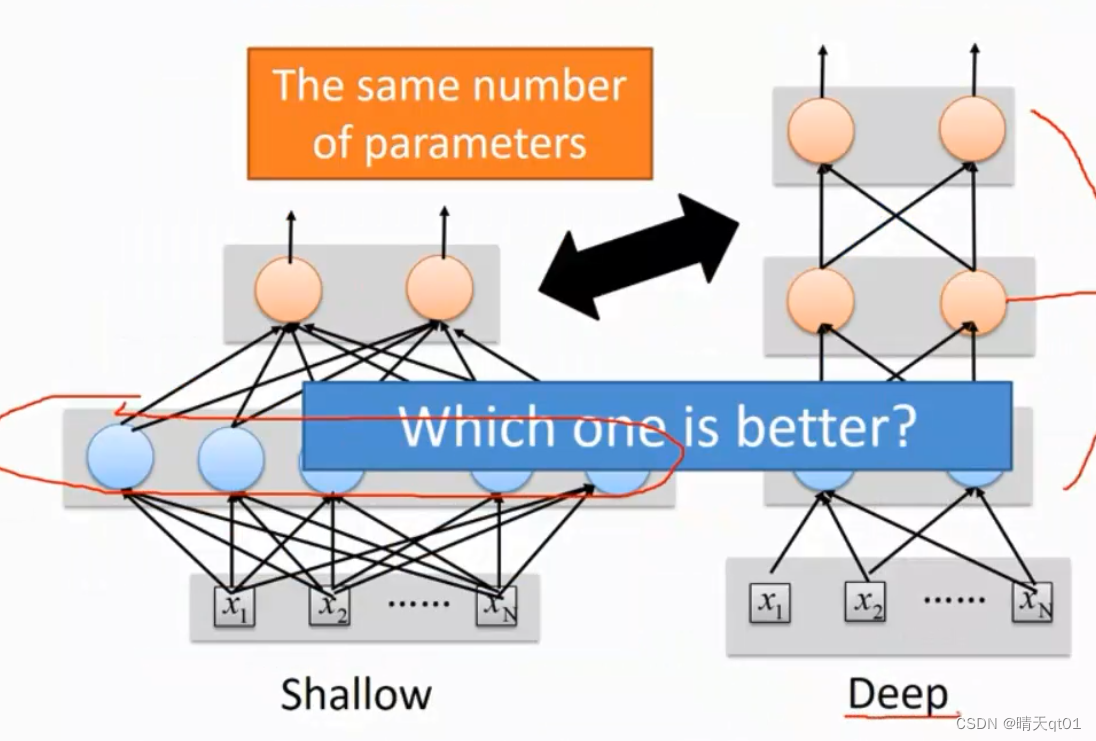
神经元数量相同的时候,左边是只设计一层隐藏层,右边是设置多层隐藏层。效果哪个会好呢?

左边是对深度进行一个加深(效果很好)右边是对神经元的数量增加。
明显可以看出,加深深度的效果会更好些。
男女头发长短区分案例(为什么隐藏层追求深度):
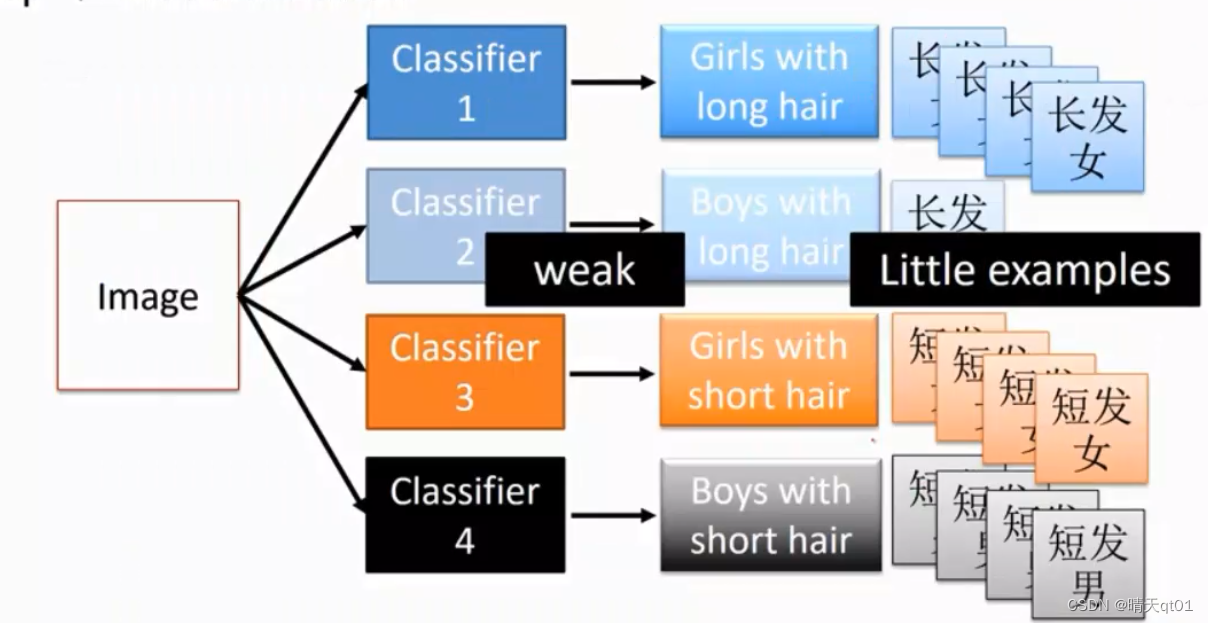
我们选择要做一个分类,要把人群分为长发男,长发女短发男,短发女4类。一次要把4类分开来,是有困难的,因为长发男的图像特别少。所以之后对长发男的判断几乎都不会是对的。训练范例太少了。
但是如果这个时候,我们增加一层,第一层我们先判断这个人的性别是男是女,然后再训练头发是长发短发。
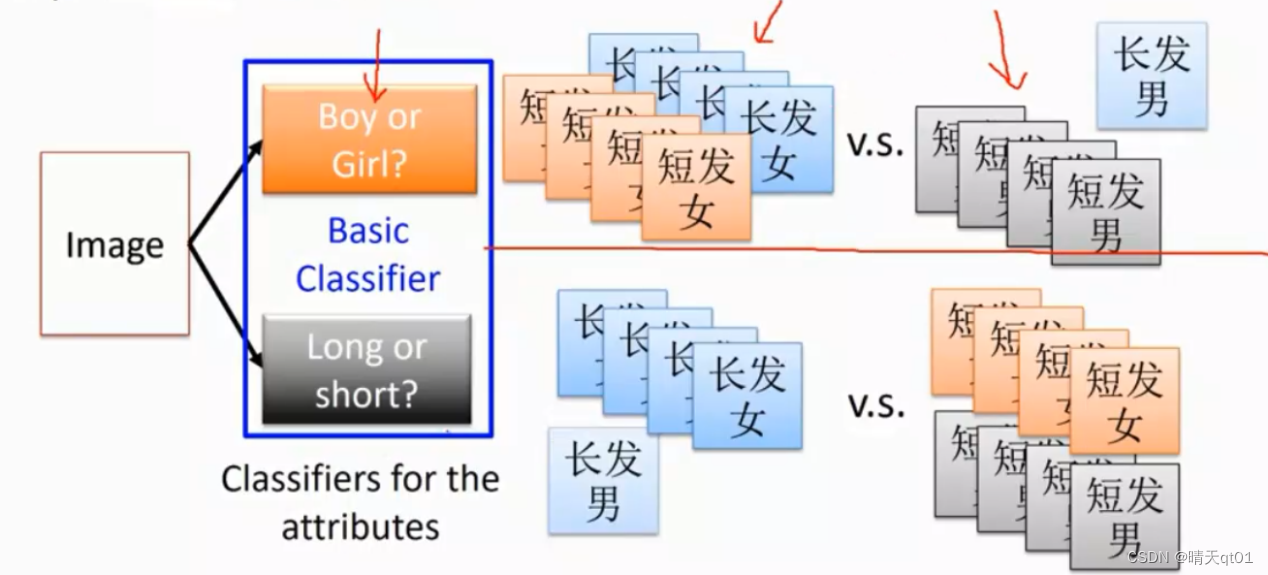
这样的好处就是,无论是性别还是头发长短的数据量都是足够的。效果比一次性把4类分出来要好很多。这也间接说明了为什么深度足够的模型效果比较好了。
训练的数据量可能还比原来需要的数据少一些。
所以我们可以得到结论,如果你使用的隐藏层层数比较多,那么你可能需要的数据量少,得到的效果还好。
我们以这个思路来看一下深度学习DNN。

我们输入1000个数据,先加入第一个隐藏层,分类为100个类别。再把100个类别归类到50个类别。
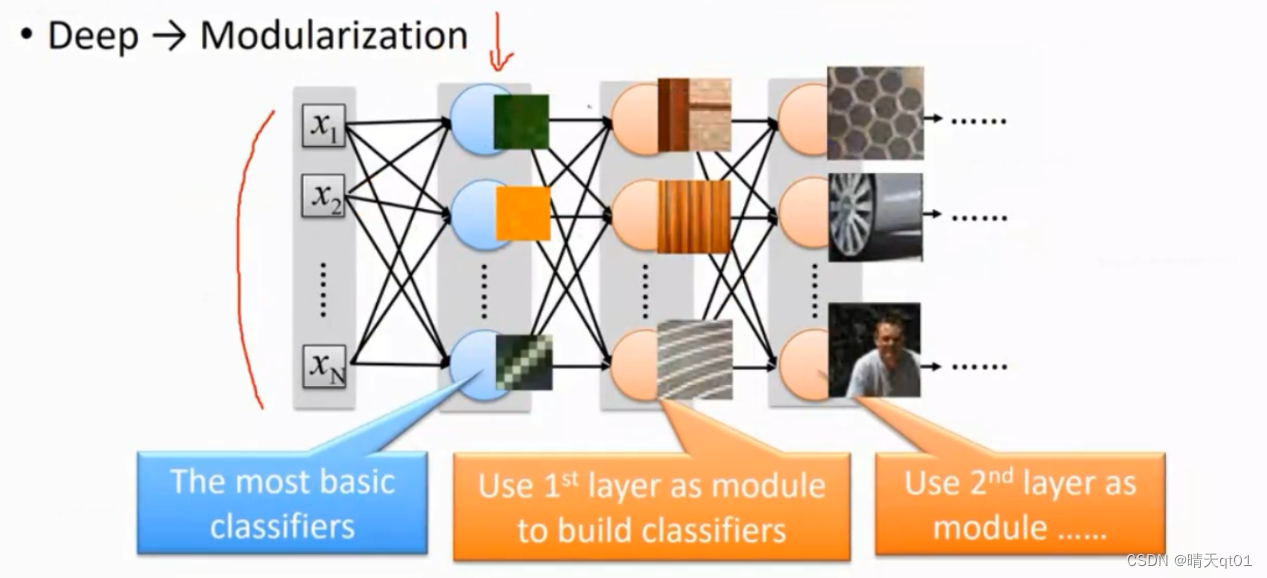
刚开始的神经元可能可以辨别出颜色第二层就可能辨识出纹理,第三层就可以利用纹理组合为物件,然后他就根据结果来帮你判断东西还是人。
这个就是深度的含义。它类似于盖房子,刚开始是砖,然后是台,慢慢越来越大。这比你一次就把房子盖好,要容易许多。
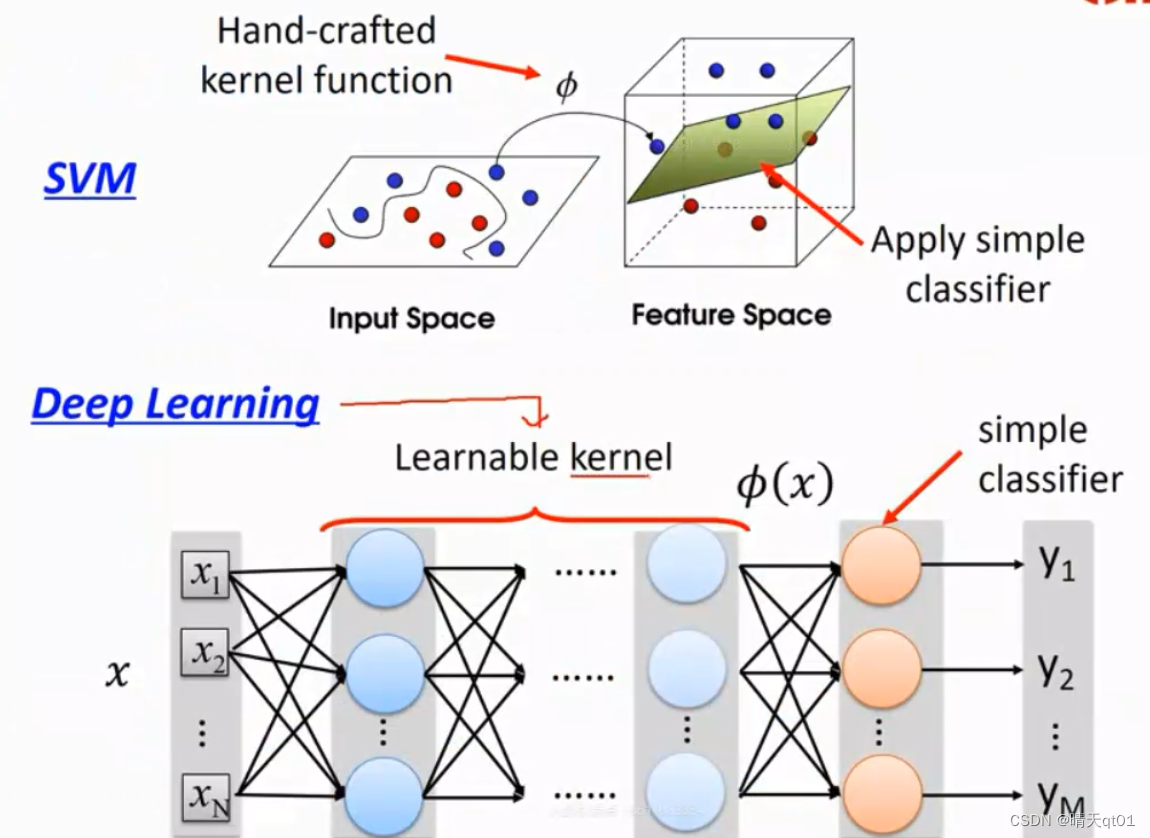
深度学习其实就是一个可以更新学习的函数(kernel function)
SVM(支持向量机):支持向量机就是通过对坐标的转换,修改,只不过这个装换和修改的规则kernel function是人为定义的。我们只是进行一个选择
深度学习就相当于自己去学习这个kernel function 然后去产生。每一层都是在进行坐标的转化,最后在一个多维空间里,用简单的线性分类(simple classifier)就把这些点进行一个切割聚类。
与支持向量机有异曲同工之妙。
为什么我们说深度学习可以进行特征学习,其实就是这个原理。我们通过坐标装换之后,就得到新的维度关系,这些可以作为新特征。
Boosting:之后会讲,现在有个印象就可以
它是把输入值进行多个弱分类,通过弱分类的组合(只在结尾输入的时候进行组合),得到输出结果的分类。XGboostin就是其中一种。
Deep Leaning:
我们也可以把Deep Leaning看为在第一层隐藏层产生了一个最弱的的弱分类器,把弱分类器进行组合得到强一点的分类器,隐藏层第二层,以此类推。最后多次的组合,得到好的效果。也就是说深度学习就是多次的boosting理论上有很大的相似性。

学到这里,是不是觉得DNN和BP神经网络其实差不多,都是由3个部分构成,有组合函数,有激活函数,有权重和bias的修补。都是刚开始使用从左往右的处理方式feedforward, 然后由于结果不理想,在使用backward pass 来修正权重值和bias。利用节点误差来调整。先利用输出层的节点误差,然后隐藏层的节点误差,一步一步由后往前传导过去。得到优化的BP神经网络模型。之后我们会说明一下它参数上的差别,激活函数等等,其实是有一定差距的

版权归原作者 晴天qt01 所有, 如有侵权,请联系我们删除。