什么是CodeBert
CodeBERT是微软在2020年开发的BERT模型的扩展。它是一个用于编程语言(PL)和自然语言(NL)的双峰预训练模型,可以执行下游的(NL-PL)任务,这个模型使用6种编程语言(Python, Java, JavaScript, PHP, Ruby, Go)进行NL-PL的匹配训练。
本文将对论文进行简要概述,并使用一个例子展示如何使用,有关模型背后的数学和详细架构的更多详细信息,请参阅原始论文。在最后除了CodeBert以外,还整理了最近一些关于他的研究之上的衍生模型。
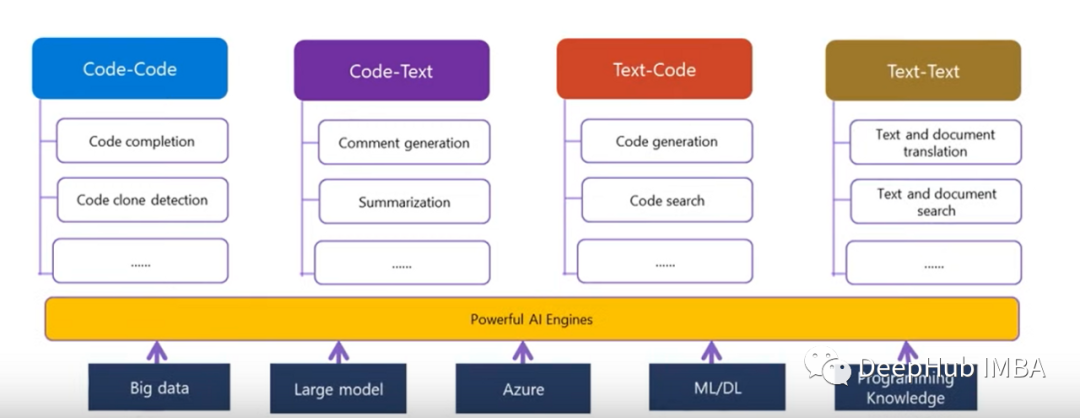
在深入研究这篇论文之前,让我们先介绍一下CodeBERT可以支持的下游任务用例和。这些用例中的一些已经在MS工具中实现,例如visual studio- IntelliCode。
CodeBert 的用例
代码转换或代码翻译:例如,当开发人员想要编写与现有python 代码相同的的 java 代码时,代码到代码翻译可以帮助翻译此代码块。
代码自动注释:可以帮助开发人员进行代码摘要。当开发人员看到不熟悉的代码时,模型可以将代码翻译成自然语言并为开发人员进行总结。
文本到代码:类似代码搜索的功能,这种搜索可以帮助用户检索基于自然语言查询的相关代码。除此以外还可以根据注释生成相应的代码。
文本到文本:可以帮助将代码域文本翻译成不同的语言。
BERT架构
BERT ((Bidirectional Encoder Representations from Transformers) 是谷歌在 2018 年提出的自监督模型。
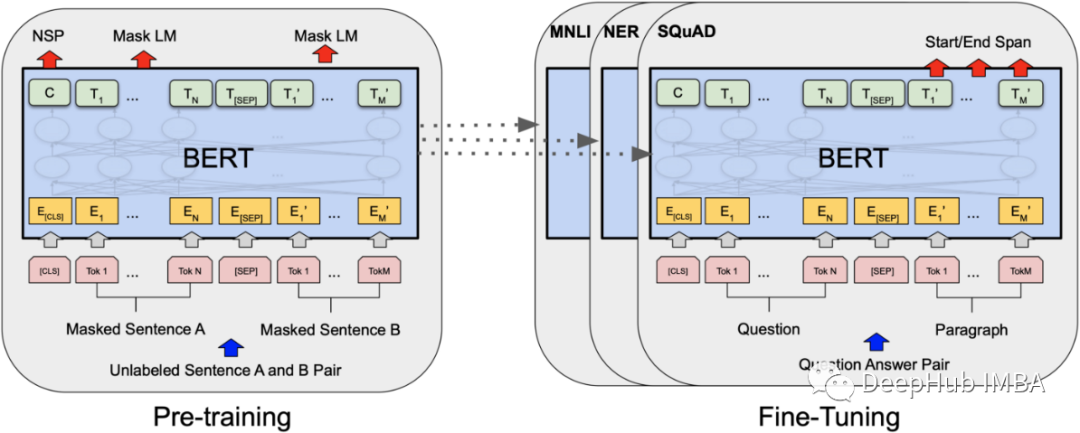
BERT 本质上是由多个自注意力“头”组成的 Transformer 编码器层堆栈(Vaswani 等人,2017 年)。对于序列中的每个输入标记,每个头计算键、值和查询向量,用于创建加权表示/嵌入。同一层中所有头的输出被组合并通过一个全连接层。每层都用跳过连接相连,然后进行层规范化(LN)。BERT 的传统工作流程包括两个阶段:预训练和微调。预训练使用两个自监督任务:掩蔽语言建模(MLM,预测随机掩蔽的输入标记)和下一句预测(NSP,预测两个输入句子是否彼此相邻)。微调适用于下游应用程序,通常在最终编码器层之上添加一个或多个全连接层。
CodeBert 架构
BERT 很容易扩展到多模态,即使用不同类型的数据集进行训练。CodeBert 是 Bert 的双模扩展。即 CodeBERT 同时使用自然语言和源代码作为其输入。(与主要关注自然语言的传统 BERT 和 RoBERTa 不同)
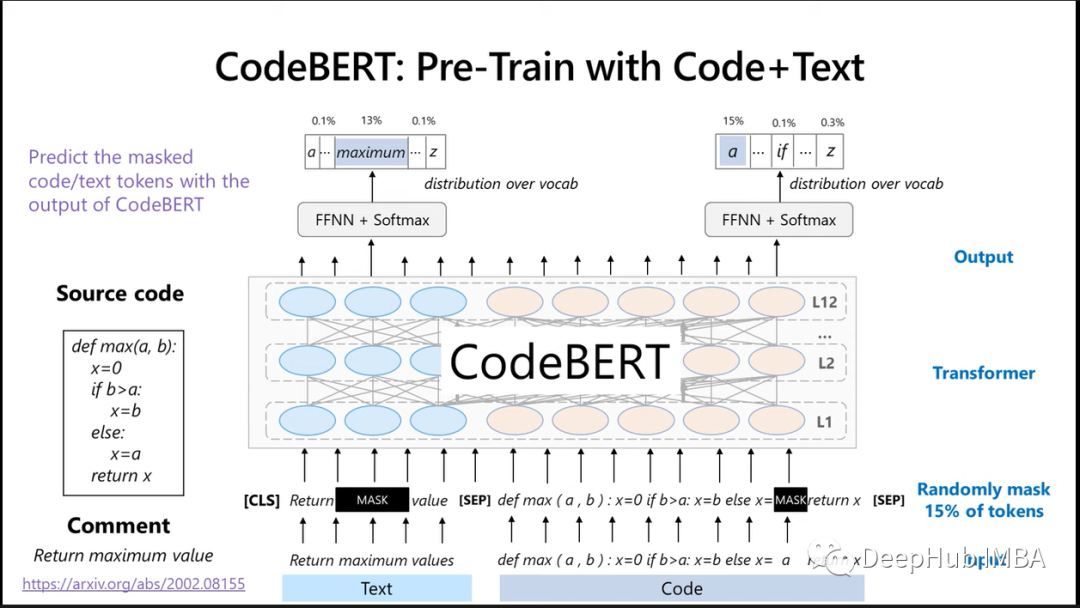
双峰 NL - PL 对:训练 CodeBERT 的典型输入是代码和明确定义的文本注释的组合。
CodeBERT 描述了两个预训练目标:掩码语言建模 (MLM) 和替换标记检测 (RTD)。
使用掩码语言建模训练 CodeBERT:为 NL 和 PL 选择一组随机位置来屏蔽掉,然后用特殊的 [MASK] 标记替换所选位置。MLM 的目标是预测被掩盖的原始标记
带有替换标记检测的训练 CodeBERT:在原始 NL 序列和 PL 序列中,有很少的标记会被随机屏蔽掉。训练一个生成器模型,它是一个类似于 n-gram 的概率模型进行屏蔽词的生成。然后训练一个鉴别器模型来确定一个词是否是原始词(二元分类问题)。
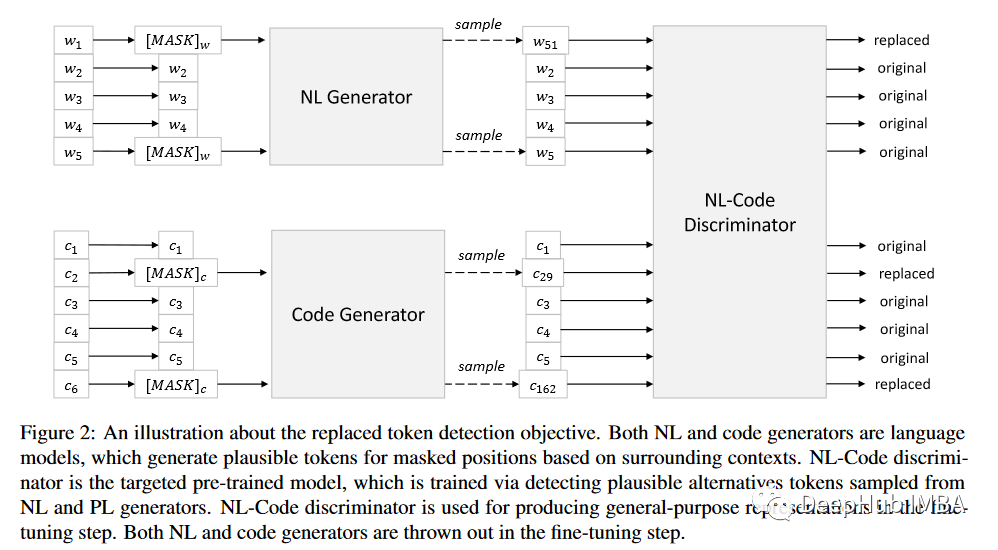
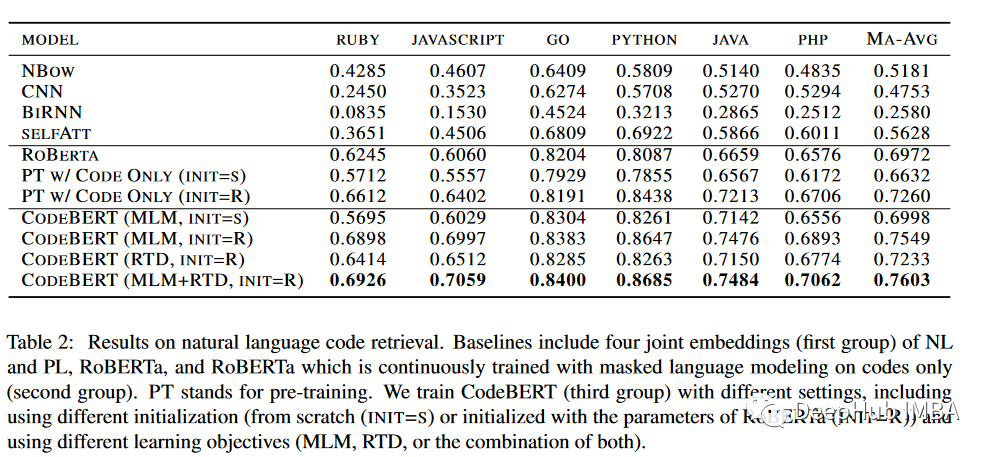
CodeBERT使用12层Transformer总计包含 125M 参数, 在 FP16精度上使用NVIDIA DGX-2 上进行 250 小时的训,结果显示当 CodeBERT 与来自 RoBERTa 模型的预训练表示一起使用时(RoBERTa 模型已使用来自 Code-SearchNet 的代码进行训练)与从头开始训练时的对比。使用 RoBERTa 初始化 CodeBERT 性能更好。
使用 CodeBERT进行微调
详细使用方法可以参考 CodeBERT 论文 在这里简要介绍如何使用 CodeBERT,并以代码文档生成为例。
安装相应的包
pip3 install torch==1.4.0
pip3 install transformers==2.5.0
pip3 install filelock
数据预处理
本任务中的数据预处理如下:
- 删除代码中的注释
- 删除代码无法解析为抽象语法树的示例。
- 删除文档的#tokens < 3 或 >256 的示例
- 删除文档包含特殊标记的示例(例如 <img ...> 或 https:...)
- 删除文档不是英文的示例。
pip3 install gdown
mkdir-p data/code2nl
cd data/code2nl
gdown https://drive.google.com/uc?id=1rd2Tc6oUWBo7JouwexW3ksQ0PaOhUr6h
unzip Cleaned_CodeSearchNet.zip
rm Cleaned_CodeSearchNet.zip
cd ../..
使用tree命令可以看到如下目录结构:
tree data/code2nl/CodeSearchNet/
data/code2nl/CodeSearchNet/
├── go
│ ├── test.jsonl
│ ├── train.jsonl
│ └── valid.jsonl
├── java
│ ├── test.jsonl
│ ├── train.jsonl
│ └── valid.jsonl
├── javascript
│ ├── test.jsonl
│ ├── train.jsonl
│ └── valid.jsonl
├── php
│ ├── test.jsonl
│ ├── train.jsonl
│ └── valid.jsonl
├── python
│ ├── test.jsonl
│ ├── train.jsonl
│ └── valid.jsonl
└── ruby
├── test.jsonl
├── train.jsonl
└── valid.jsonl
6 directories, 18 files
每种语言都有自己的训练、验证、测试数据文件。
运行程序
访问 https://github.com/microsoft/CodeBERT/tree/master/CodeBERT/code2nl 并克隆 run.py、bleu.py、model.py 文件并将它们放入 data/code2nl 文件夹中。
运行以下命令。将batch_size=128改为batch_size=4,这是因为GPU的内存不够,太大的bs会导致OOM。
lang=php
beam_size=10
batch_size=4
source_length=256
target_length=128
output_dir=model/$lang
data_dir=../data/code2nl/CodeSearchNet
dev_file=$data_dir/$lang/valid.jsonl
test_file=$data_dir/$lang/test.jsonl
test_model=$output_dir/checkpoint-best-bleu/pytorch_model.bin #checkpoint for test
python run.py --do_test --model_type roberta --model_name_or_path microsoft/codebert-base --load_model_path $test_model --dev_filename $dev_file --test_filename $test_file --output_dir $output_dir --max_source_length $source_length --max_target_length $target_length --beam_size $beam_size --eval_batch_size $batch_size
这样就开始训练了,训练完成后如何调用 CodeBERT呢?
如果只想使用从 CodeBERT 转换的特征表示,可以使用以下示例代码:
from transformers import AutoTokenizer, AutoModel
import torch
# Init
tokenizer = AutoTokenizer.from_pretrained("microsoft/codebert-base")
model = AutoModel.from_pretrained("microsoft/codebert-base")
# Tokenization
nl_tokens=tokenizer.tokenize("return maximum value")
code_tokens=tokenizer.tokenize("def max(a,b): if a>b: return a else return b")
tokens=[tokenizer.cls_token]+nl_tokens+[tokenizer.sep_token]+code_tokens+[tokenizer.sep_token]
# Convert tokens to ids
tokens_ids=tokenizer.convert_tokens_to_ids(tokens)
context_embeddings=model(torch.tensor(tokens_ids)[None,:])[0]
# Print
print(context)
输出的结果如下:
tensor([[-0.1423, 0.3766, 0.0443, ..., -0.2513, -0.3099, 0.3183],
[-0.5739, 0.1333, 0.2314, ..., -0.1240, -0.1219, 0.2033],
[-0.1579, 0.1335, 0.0291, ..., 0.2340, -0.8801, 0.6216],
...,
[-0.4042, 0.2284, 0.5241, ..., -0.2046, -0.2419, 0.7031],
[-0.3894, 0.4603, 0.4797, ..., -0.3335, -0.6049, 0.4730],
[-0.1433, 0.3785, 0.0450, ..., -0.2527, -0.3121, 0.3207]],
grad_fn=<SelectBackward>)
上面代码我们也看到Huggingface也提供了CodeBERT相关的模型,我们可以直接拿来使用:
import torch
from transformers import RobertaTokenizer,RobertaConfig,RobertaModel
device=torch.device("cuda"if torch.cuda.is_available() else"cpu")
tokenizer=RobertaTokenizer.from_pretrained("microsoft/codebert-base")
model=RobertaModel.from_pretrained("microsoft/codebert-base")
model.to(device)
codebert地址:
https://github.com/microsoft/CodeBERT
基于CodeBERT的其他模型介绍
GraphCodeBert:基于数据流的代码表征预训练模型
https://arxiv.org/abs/2009.08366
利用代码的语义结构来学习代码表征的预训练模型GraphCodeBERT,基于Bert预训练模型实现,除了传统的MLM任务外,本文还提出了两个新的预训练任务(数据流边预测、源代码和数据流的变量对齐),基于数据流学习源代码的向量表征,在4个下游任务上取得了显著的提升效果。
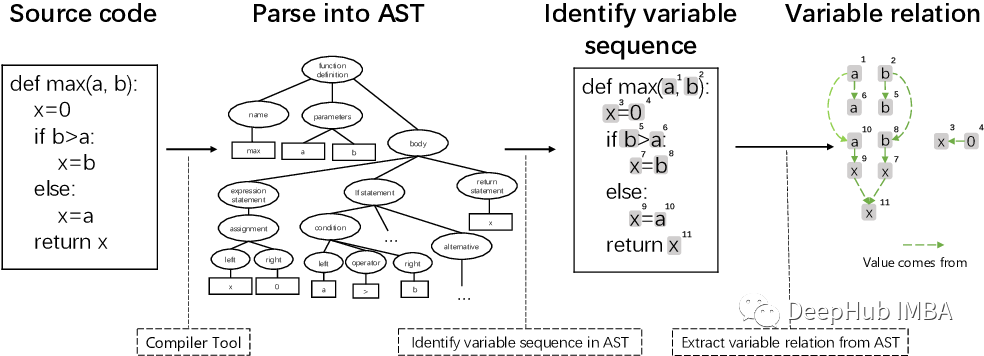
UniXcoder: 统一的跨模式预训练模型
https://arxiv.org/abs/2203.03850
Unixcoder是一种用于编程语言的统一的跨模式预训练模型。该模型利用带有前缀适配器的掩码注意矩阵来控制模型的行为,并利用AST和代码注释等跨模式内容来增强代码表示。为了对并行表示为树的AST进行编码,论文提出了一种一对一的映射方法,可以保留AST中所有结构信息的序列结构。该模型还利用多模态内容通过对比学习来学习代码片段的表示,然后使用跨模态生成任务来对齐编程语言之间的表示。
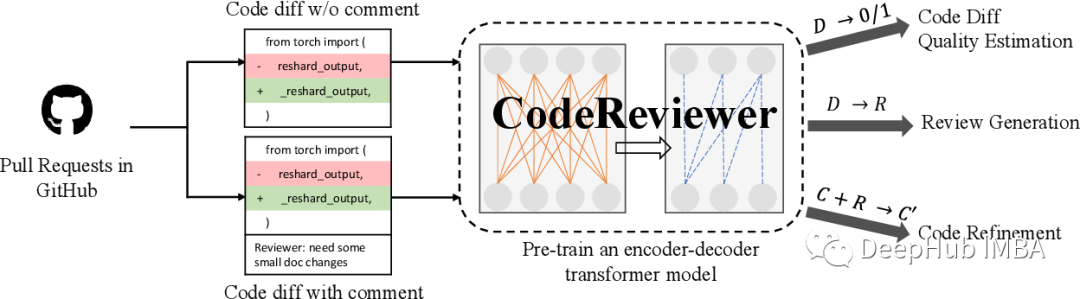
CodeReviewer:自动化代码审查
https://arxiv.org/abs/2203.09095
在上面研究的基础上,又提出了CodeReviewer,这是一个预先训练的模型,它利用了四个专门为代码审查场景量身定制的预先训练任务。模型的重点放在与代码评审活动相关的三个关键任务上,包括代码变更质量评估、评审注释生成和代码优化。模型的测试证明了通过预训练任务和多语言训练数据集可以让模型对代码更改和审查进行自动化的操作。