
文档理解是文档处理和提取中最重要的步骤。这是从非结构化或半结构化文档中提取信息并将其转换为结构化形式的过程。提取后的结构化表示可以支持各种下游任务,例如信息检索,汇总,分类等。有许多不同的方法可以理解文档,但它们都有一个共同的目标:创建文档内容的结构化表示,以便用于进一步的处理。
对于半结构化文档,例如发票,收款或合同,Microsoft的Layoutlm模型可以良好的进行工作。

在本文中,我们将在微软的最新Layoutlm V3上进行微调,并将其性能与Layoutlm V2模型进行比较。
LayoutLM v3
LayoutLM v3相对于其前两个版本的主要优势是多模态transformer 架构,它以统一的方式将文本和图像嵌入结合起来。文档图像不依赖CNN进行处理,而是将图像补丁块表示为线性投影,然后线性嵌入与文本标记对齐,如下图所示。这种方法的主要优点是减少了所需的参数和整体计算量。
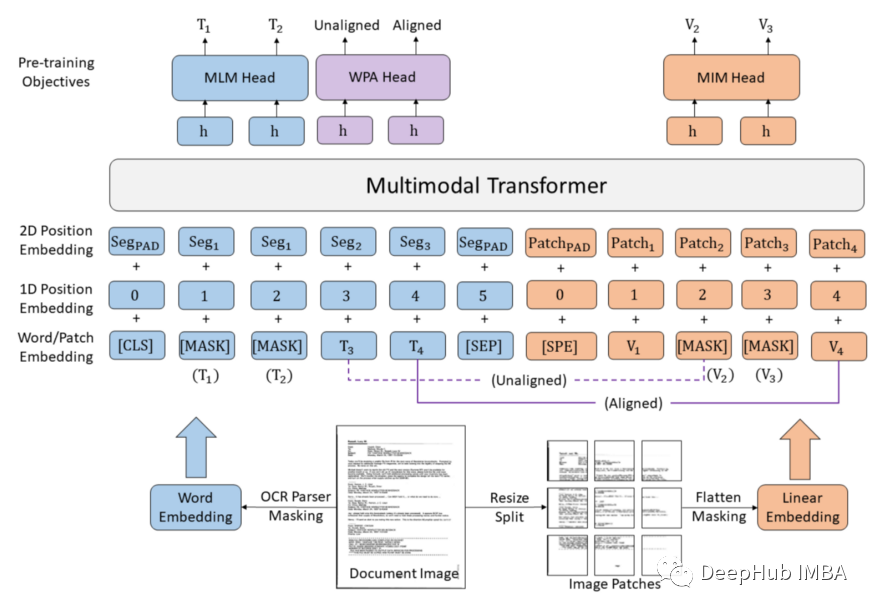
论文的作者表示,“LayoutLMv3不仅在以文本为中心的任务(包括表单理解、票据理解和文档视觉问题回答)中实现了最先进的性能,而且还在以图像为中心的任务(如文档图像分类和文档布局分析)中实现了最先进的性能。”
微调LayoutLM v3
我们将使用相同的220个带注释的发票数据集来微调layoutLM v3模型。为了进行标注,我使用了UBIAI文本注释工具,因为它支持OCR解析,原生PDF/图像注释,并可以用LayoutLM模型兼容的格式导出,这样就可以节省后期处理的工作。
从UBIAI导出注释文件后,我们将使用谷歌colab进行模型训练和推理。源代码地址在最后提供,我们这里简述工作的流程
第一步是打开colab,安装相应的库。与layoutLMv2不同,我们没有使用detectron 2包对实体提取的模型进行微调。但是对于布局检测(不在本文讨论范围内),需要使用detectorn 2包:
from google.colab import drive
drive.mount('/content/drive')
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q git+https://github.com/huggingface/datasets.git "dill<0.3.5" seqeval
接下来,使用preprocess.py脚本来处理从UBIAI导出的ZIP文件:
! rm -r layoutlmv3FineTuning
! git clone -b main https://github.com/UBIAI/layoutlmv3FineTuning.git
#!/bin/bash
IOB_DATA_PATH = "/content/drive/MyDrive/LayoutLM_data/Invoice_Project_mkWSi4Z.zip"
! cd /content/
! rm -r data! mkdir data
! cp "$IOB_DATA_PATH" data/dataset.zip
! cd data && unzip -q dataset && rm dataset.zip
! cd ..
运行预处理脚本:
#!/bin/bash
TEST_SIZE = 0.33
DATA_OUTPUT_PATH = "/content/"
! python3 layoutlmv3FineTuning/preprocess.py --valid_size $TEST_SIZE --output_path $DATA_OUTPUT_PATH
加载处理后数据集:
from datasets import load_metric
from transformers import TrainingArguments, Trainer
from transformers import LayoutLMv3ForTokenClassification,AutoProcessor
from transformers.data.data_collator import default_data_collator
import torch
from datasets import load_from_disk
train_dataset = load_from_disk(f'/content/train_split')
eval_dataset = load_from_disk(f'/content/eval_split')
label_list = train_dataset.features["labels"].feature.names
num_labels = len(label_list)
label2id, id2label = dict(), dict()
for i, label in enumerate(label_list):
label2id[label] = i
id2label[i] = label
定义评估指标:
metric = load_metric("seqeval")
import numpy as np
return_entity_level_metrics = False
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels,zero_division='0')
if return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
对模型进行训练和评估:
model = LayoutLMv3ForTokenClassification.from_pretrained("microsoft/layoutlmv3-base",
id2label=id2label,
label2id=label2id)
processor = AutoProcessor.from_pretrained("microsoft/layoutlmv3-base", apply_ocr=False)
NUM_TRAIN_EPOCHS = 50
PER_DEVICE_TRAIN_BATCH_SIZE = 1
PER_DEVICE_EVAL_BATCH_SIZE = 1
LEARNING_RATE = 4e-5
training_args = TrainingArguments(output_dir="test",
# max_steps=1500,
num_train_epochs=NUM_TRAIN_EPOCHS,
logging_strategy="epoch",
save_total_limit=1,
per_device_train_batch_size=PER_DEVICE_TRAIN_BATCH_SIZE,
per_device_eval_batch_size=PER_DEVICE_EVAL_BATCH_SIZE,
learning_rate=LEARNING_RATE,
evaluation_strategy="epoch",
save_strategy="epoch",
# eval_steps=100,
load_best_model_at_end=True,
metric_for_best_model="f1")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=processor,
data_collator=default_data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.evaluate()
训练完成后,对测试数据集进行评估。以下为评价后的模型得分:
{'epoch': 50.0,
'eval_accuracy': 0.9521988527724665,
'eval_f1': 0.6913439635535308,
'eval_loss': 0.41490793228149414,
'eval_precision': 0.6362683438155137,
'eval_recall': 0.756857855361596,
'eval_runtime': 9.7501,
'eval_samples_per_second': 9.846,
'eval_steps_per_second': 9.846}
该模型f1得分为0.69,召回率为0.75,准确率为0.63。
让我们在不属于训练数据集的新发票上运行模型。
使用LayoutLM v3进行预测
为了进行预测,我们将使用Tesseract对发票进行OCR,并将信息输入到训练好的模型中进行预测。为了简化这一过程,我创建了一个自定义脚本,其中只包含几行代码,允许接收OCR输出并使用模型运行预测。
第一步,让我们导入一些重要的库并加载模型:
from google.colab import drive
drive.mount('/content/drive')
!pip install -q git+https://github.com/huggingface/transformers.git
! sudo apt install tesseract-ocr
! sudo apt install libtesseract-dev
! pip install pytesseract
! git clone https://github.com/salmenhsairi/layoutlmv3FineTuning.git
import os
import torch
import warnings
from PIL import Image
warnings.filterwarnings('ignore')
os.makedirs('/content/images',exist_ok=True)
for image in os.listdir():
try:
img = Image.open(f'{os.curdir}/{image}')
os.system(f'mv "{image}" "images/{image}"')
except:
pass
model_path = "/content/drive/MyDrive/LayoutLM_data/layoutlmv3.pth" # path to Layoutlmv3 model
imag_path = "/content/images" # images folder
if model_path.endswith('.pth'):
layoutlmv3_model = torch.load(model_path)
model_path = '/content/pre_trained_layoutlmv3'
layoutlmv3_model.save_pretrained(model_path)
使用模型进行预测
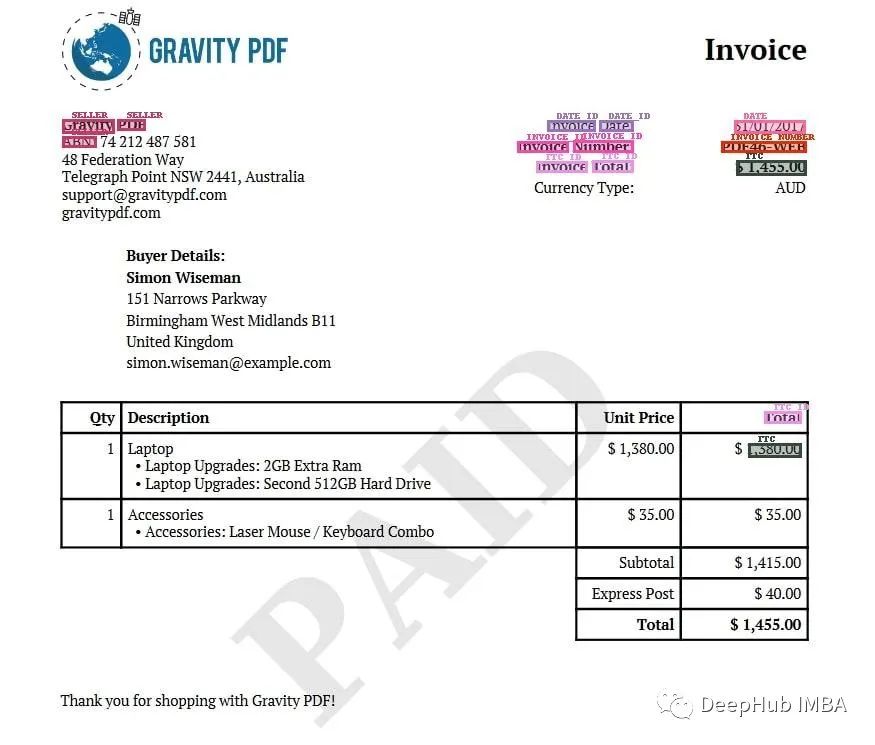
我们使用了220张带标注的发票进行训练,该模型能够正确预测卖方名称、日期、发票编号和总价(TTC)!
如果仔细观察,就会发现把笔记本电脑总价当作发票总价的做法是错误的(上图)。这并不奇怪,我们可以用更多的训练数据来解决这个问题。
比较LayoutLM v2和LayoutLM v3
除了计算量更少之外,layoutLM V3是否比它的v2版本提供了性能提升?为了回答这个问题,我们比较了相同发票的两个模型输出。下面相同数据下layoutLM v2输出:
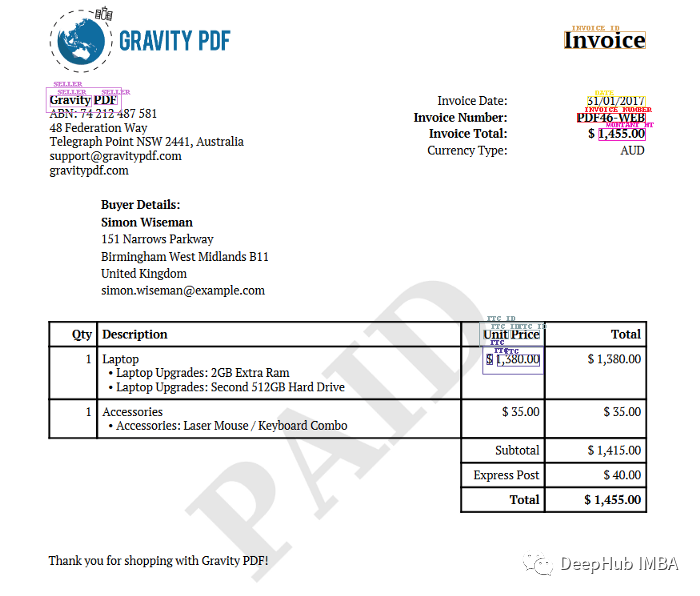
v3模型能够正确地检测到大多数的项目,而v2不能检测invoice_ID、发票number_ID和Total_ID
v2型号错误地将Total price $ 1445 .00标为MONTANT_HT(法语中是税前总价),而v3正确地预测了总价。
两个模型都错误地将笔记本电脑的价格标为Total。
基于这个例子,layoutLM V3显示了更好的整体性能,但我们需要在更大的数据集上进行测试。
总结
本文中展示了如何在发票数据提取的特定用例上微调layoutLM V3。然后将其性能与layoutLM V2进行了比较,发现它的性能略有提高,但仍需要在更大的数据集上验证。
基于性能和计算收益,我强烈建议使用新的layoutLM v3。
本文的一些有用的资料:
UBIAI注解工具介绍:
https://www.youtube.com/watch?v=o4ONgmRP0ss
训练代码:
https://colab.research.google.com/drive/1TuPQ1HdhMYjfQI9VRV3FMk7bpPYD4g6w?authuser=2
预测代码:
作者:Walid Amamou
