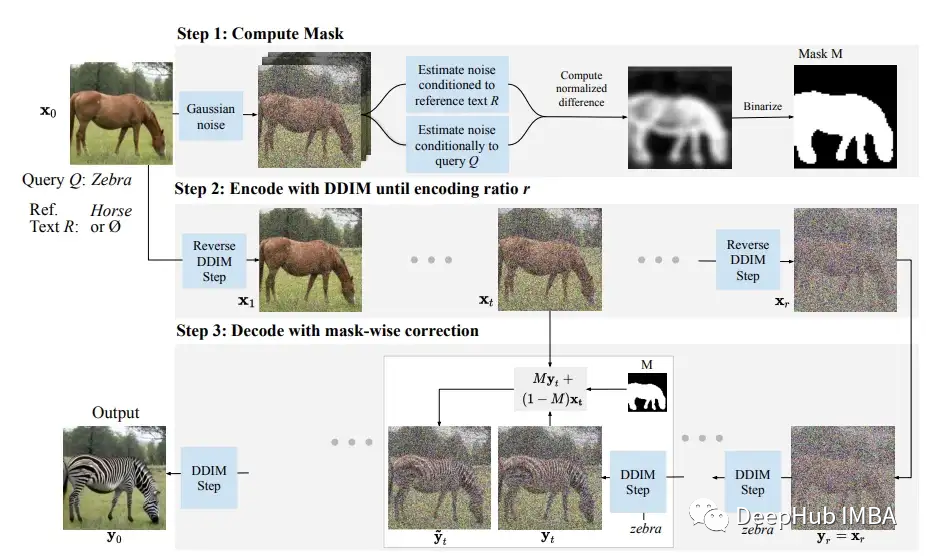
使用HuggingFace实现 DiffEdit论文的掩码引导语义图像编辑
在本文中,我们将实现Meta AI和Sorbonne Universite的研究人员最近发表的一篇名为DIFFEDIT的论文。对于那些熟悉稳定扩散过程或者想了解DiffEdit是如何工作的人来说,这篇文章将对你有所帮助。
基于BP神经网络的PID智能控制
PID控制要获得较好的控制效果,就必须通过调整好比例、积分和微分三种控制作用,形成控制量中既相互配合又相互制约的关系,这种关系不一定是简单的“线性组合”,从变化无穷的非线性组合中可以找出最佳的。神经网络所具有的任意非线性表达的能力,可以通过对系统性能的学习来实现具有最佳组合的PID控制。
从感知机到神经网络
将输入信号的总和转换为输出信号输入:输入信号的加权总和激活函数:h(a)计算得到结果可以在神经元内部中明确的显示出激活函数的激活过程激活函数是连接感知机和神经网络的桥梁函数输入大于0时,直接输出该值否则输出0。
2022年顶会、顶刊SNN相关论文----------持续更新中
2022年顶会、顶刊脉冲神经网络相关优秀论文收集
一文通俗入门·脉冲神经网络(SNN)·第三代神经网络
一文通俗入门脉冲神经网络(snn)动力学方程,前向传播过程,学习算法,脉冲编码方式
ECCV2022论文列表(中英对照)
ECCV2022论文列表(中英对照)
【ResNet】Pytorch从零构建ResNet18
Pytorch从零构建ResNet18ResNet 目前是应用很广的网络基础框架,所以有必要了解一下.本文从简单的ResNet18开始,详细分析了ResNet18的网络结构,并研究BasicBlock的结构。,使得整个结构非常清晰,再之后手工构建ResNet18网络就没有那么困难了。
【YOLO系列】YOLOv5、YOLOX、YOOv6、YOLOv7网络模型结构
YOLOv5、YOLOX、YOLOv6、YOLOv7模型结构图
【网络流量识别】总结篇1:机器学习方法在网络流量识别的应用
本文总结深度学习方法在流量识别方面的应用,也是对前四篇文章的总结。主要包括数据集,特征提取方法,深度学习网络,性能比较等几方面的介绍。一、概述网络入侵检测系统(N-IDS)是根据网络类型及其行为,对网络网络流量数据分类的主要方法有(1)误用检测;(2)异常检测;(3)状态完整协议分析机器学习方法是目
YOLOv5 人脸口罩识别 免费提供数据集
本文分享快速使用YOLOv5训练自己的人脸口罩数据集。第一步是搞数据,并把标注文件处理成YOLOv5格式,这其实是最麻烦的,此处省略1W字,我给同学们整了一个6000张的:人脸口罩数据集。拿走不蟹~下载YOLOv5-3.1版本和模型权重,考虑到模型权重可能下载缓慢,我还上传了一份:模型权重。真是太贴
超分之EDSR
这篇文章是SRResnet的升级版——EDSR,其对网络结构进行了优化(去除了BN层),省下来的空间可以用于提升模型的size来增强表现力。此外,作者提出了一种基于EDSR且适用于多缩放尺度的超分结构——MDSR。EDSR在2017年赢得了NTIRE2017超分辨率挑战赛的冠军。参考目录:①深度学习
深度学习之BP神经网络
算法是神经网络深度学习中最重要的算法之一,是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的神经网络模型之一。基本结构如图:其主要包含三部分(由左到右)1:输入层:输入数据2:隐含层:输入与输出之间的数据分析加工厂,通过各种参数(权重,偏差值)以及激活函数等其他数据处理方法与两边建立联
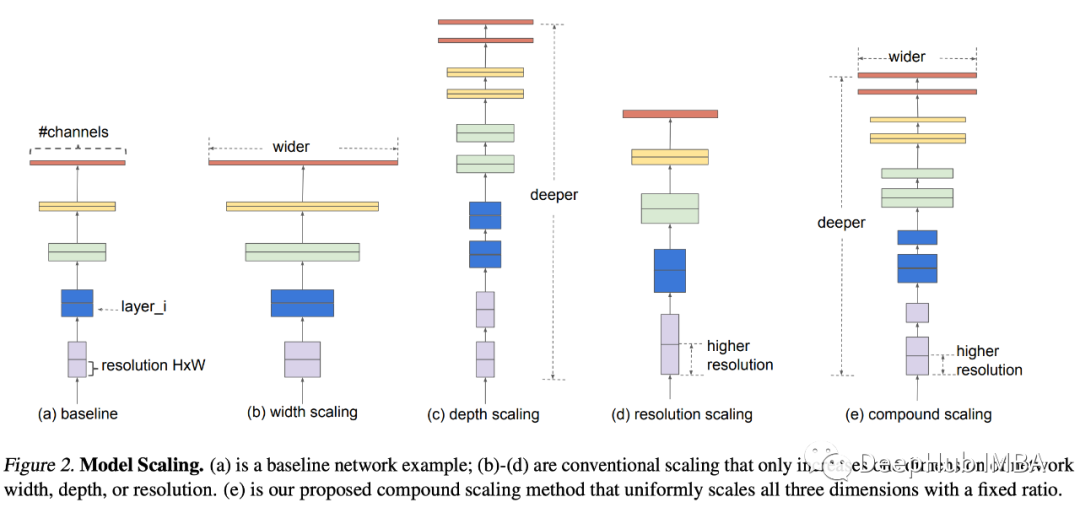
经典CNN设计演变的关键总结:从VGGNet到EfficientNet
卷积神经网络设计史上的主要里程碑:模块化、多路径、因式分解、压缩、可扩展
语义分割系列15-UPerNet(pytorch实现)
本文介绍了UPerNet论文思想,介绍了UPerNet作者如何创建Multi-task数据集以及如何设计UPerNet网络和检测头来解决Multi-task任务。本文对于UPerNet语义分割部分的模型进行单独复现,所有代码基于pytorch框架,并在Camvid数据集上进行训练和测试。......

使用LIME解释CNN
图像与表格数据集有很大不同,我们用突出显示图像中模型预测的重要区域的方法观察可解释性
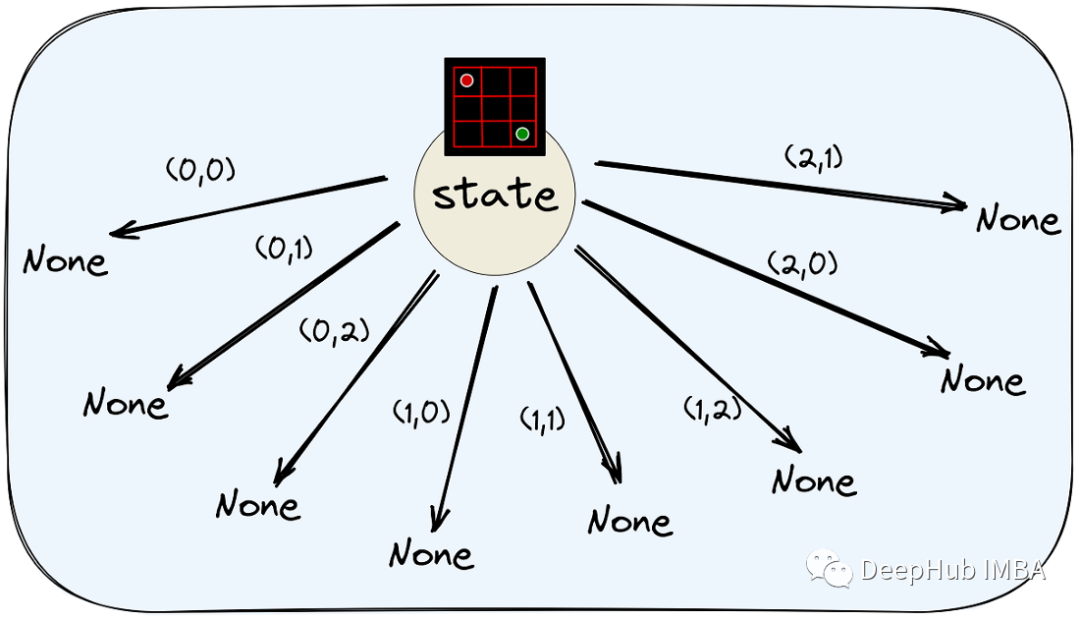
使用PyTorch实现简单的AlphaZero的算法(2):理解和实现蒙特卡洛树搜索
本篇文章将实现AlphaZero的核心搜索算法:蒙特卡洛树搜索
使用PyTorch实现简单的AlphaZero的算法(1):背景和介绍
在本文中,我们将在PyTorch中为Chain Reaction[2]游戏从头开始实现DeepMind的AlphaZero[1]。
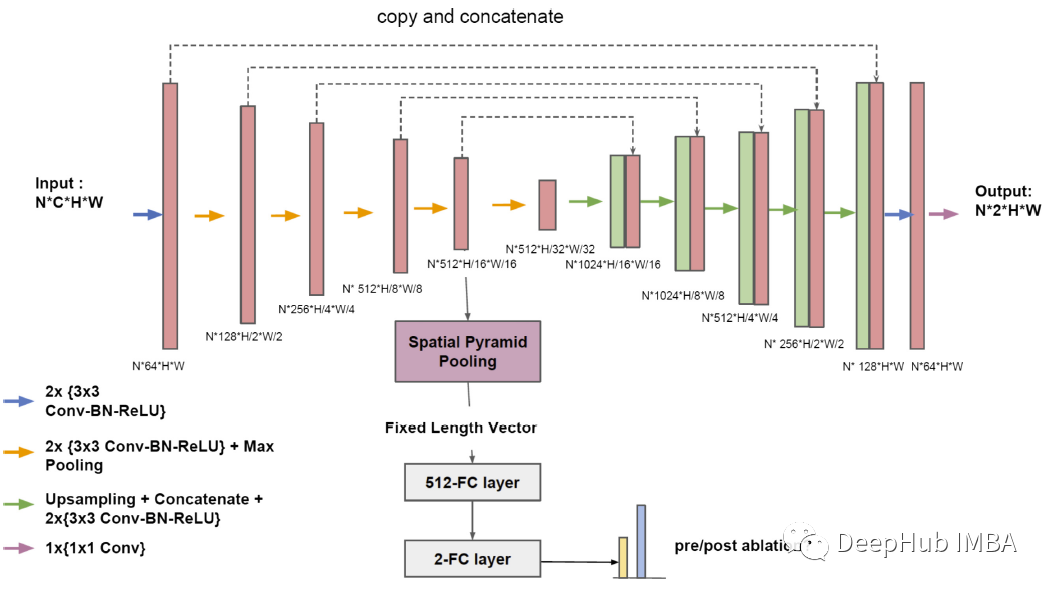
论文推荐:基于GE-MRI的多任务学习
医学图像分析,多任务学习,图像分类,图像分割,U-Net,后处理
语义分割系列6-Unet++(pytorch实现)
本文介绍了Unet++网络,在pytorch框架上复现Unet++,并在Camvid数据集上进行训练。
用pointnet++分类自己的点云数据
这篇博客主要是针对于现有的热门的激光点云处理算法pointnet++如何分类自己的数据集展开的。在介绍基本的pointnet++算法的概念、基本步骤及思想、部分代码讲解之后,会介绍如何使用自己的数据集进行分类(涉及到详细的代码改进方法及步骤)以及打印利用自己数据集跑出的模型后的点云坐标。



