
RepVGG: Making VGG-style ConvNets Great Again 是2021 CVPR的一篇论文,正如他的名字一样,使用structural re-parameterization的方式让类VGG的架构重新获得了最好的性能和更快的速度。在本文中首先对论文进行详细的介绍,然后再使用Pytorch复现RepVGG模型.
论文详解
1、多分支模型的问题
速度:
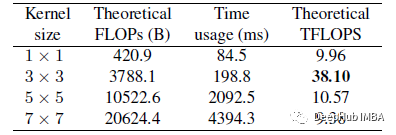
上图可以看到3×3 conv的理论计算密度大约是其他计算密度的4倍,这表明理论总FLOPs不是不同架构之间的实际速度的可比指标。例如,VGG-16比effentnet - b3大8.4×,但在1080Ti上运行却速度快1.8×。
在Inception的自动生成架构中,使用多个小的操作符,而不是几个大的操作符的多分支拓扑被广泛采用。
NASNet-A中的碎片化量为13,这对GPU等具有强大并行计算能力的设备不友好。
内存:
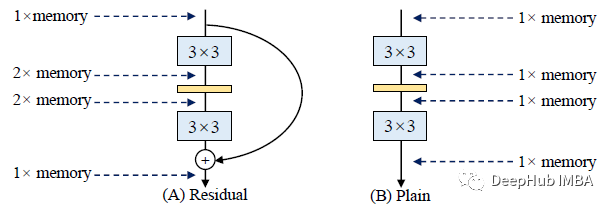
多分支的内存效率很低,因为每个分支的结果都需要保存到残差连接或连接为止,这会显著提高内存占用的峰值。上图显示,一个残差块的输入需要一直保持到加法。假设块保持feature map的大小,额外内存占用的峰值为为输入的2倍。
2、RepVGG
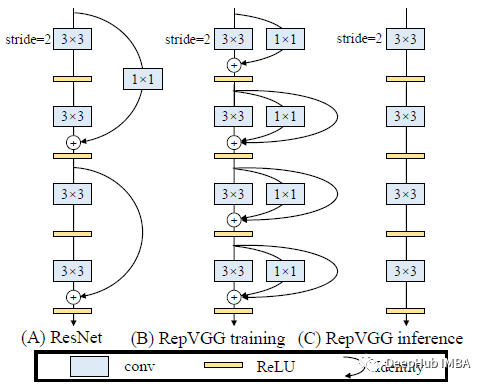
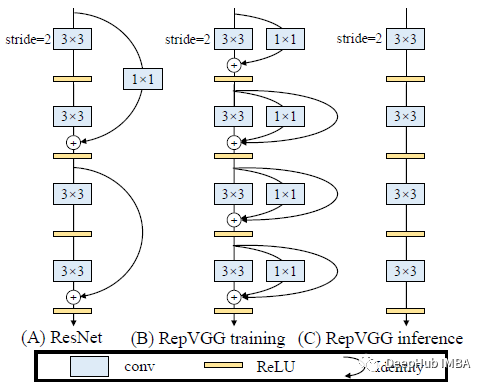
(a) ResNet:它在训练和推理过程中都得到了多路径拓扑,速度慢,内存效率低。
(b) RepVGG训练 :仅在训练时得到多路径拓扑。
(c) RepVGG推理:只在推理时得到单路径拓扑,推理时间快。
对于多分支,ResNets成功解释了这样的多分支架构使模型隐式地集成了许多较浅的模型。具体来说,当有n个块时,模型可以解释为2^n个模型的集合,因为每个块都将流分支为两条路径。由于多分支拓扑在推理方面存在缺陷,但是分支有利于训练,因此使用多分支来实现众多模型的集成只在训练时花费很多时间。
repvgg使用类似于 identity层(尺寸匹配时,输入就是输出,不做操作)和1×1卷积,因此构建块的训练时间信息流为y = x+g(x)+f(x),如上图的(b) 。所以模型变成了3^n个子模型的集合,包含n个这样的块。
为普通推断时间模型重新设置参数:
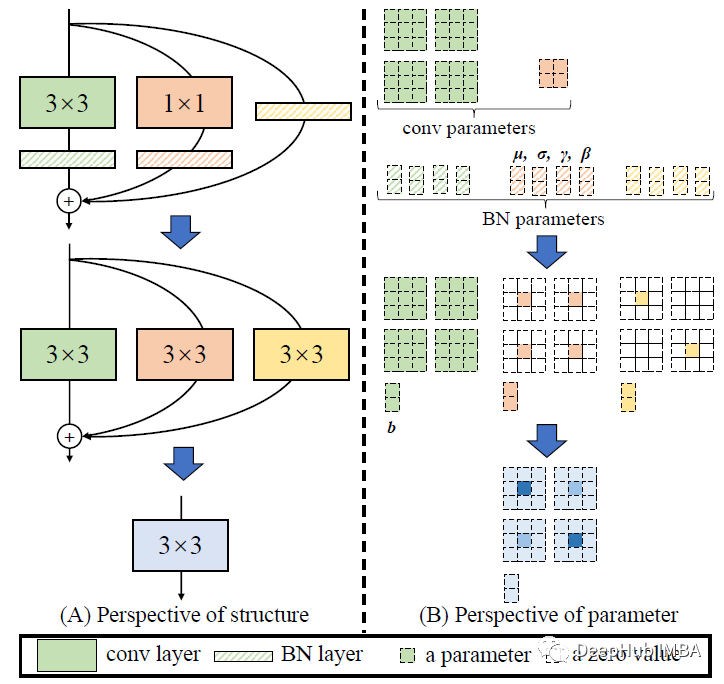
BN在每个分支中都在加法之前使用。
设大小为C2×C1×3×3的W(3)表示3×3 核,其C1输入通道和C2输出通道,而大小为C2×C1的W(1)表示1×1分支核
μ(3)、 σ(3)、γ(3)、β(3)分别为3×3卷积后BN层的累积均值、标准差、学习尺度因子和偏差。
1×1 conv后的BN参数与μ(1)、 σ(1)、γ(1)、β(1)相似,同分支的BN参数与μ(0)、(0)、γ(0)、β(0)相似。
设M(1)的大小为N×C1×H1×W1, M(2)的大小为N×C2×H2×W2,分别为输入和输出,设*为卷积算子。
如果C1=C2, H1=H2, W1=W2,我们得到:
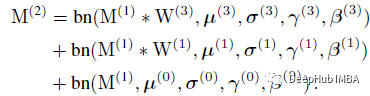
式中bn为推理时间bn函数:
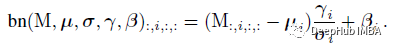
BN与Conv合并:首先将每一个BN及其前一卷积层转换为带有偏置矢量的卷积。设{W ', b '}为转换后的核和偏置:
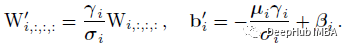
则推理时bn为:
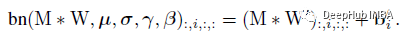
所有分支合并:这种转换也适用于 identity分支,因为可以将 identity层视为1×1 conv,将单位矩阵作为核。在这些转换之后将拥有一个3×3核、两个1×1内核和三个偏置向量。然后我们将三个偏置向量相加,得到最终的偏置。最后是3×3核,将1×1核添加到3×3核的中心点上,这可以通过将两个1×1内核的零填充到3×3并将三个核相加来实现,如上图所示。
RepVGG架构如下

3×3层分为5个阶段,阶段的第一层则是stride= 2。为了进行图像分类,全局平均合并后,然后将完连接的层用作分类头。对于其他任务,特定于任务的部可以在任何一层产生的特征上使用(例如分割、检测需要的多重特征)。
五个阶段分别具有1、2、4、14、1层,构建名称为RepVGG-B。
更深的RepVGG-B,在第2、3和4阶段中有2层。
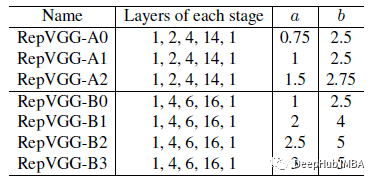
也可以使用不同的a和b产生不同的变体。A用于缩放前四个阶段,而B用于最后阶段,但是要保证b> a。为了进一步减少参数和计算量,采用了interleave groupwise的3×3卷积层以换取效率。其中,RepVGG-A的第3、5、7、…、21层以及RepVGG-B额外的第23、25、27层设置组数g。为了简单起见,对于这些层,g被全局地设置为1、2或4,而没有进行分层调整。
3、实验结果
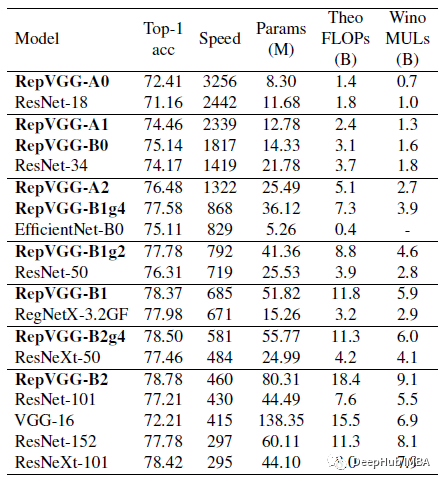
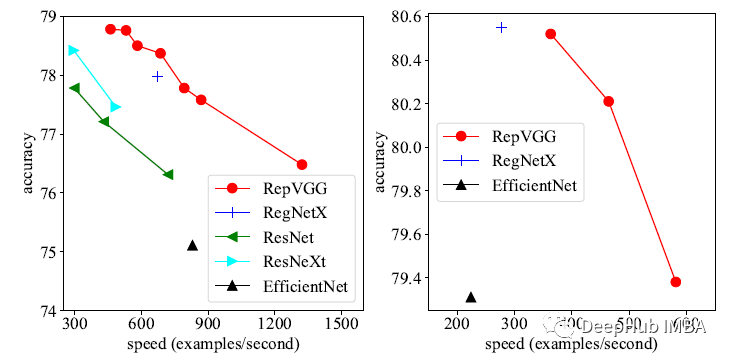
REPVGG-A0在准确性和速度方面比RESNET-18好1.25%和33%,REPVGGA1比RESNET-34好0.29%/64%,REPVGG-A2比Resnet-50好0.17%/83%。
通过分组层(g2/g4)的交错处理,RepVGG模型的速度进一步加快,精度下降较为合理:RepVGG- b1g4比ResNet-101提高了0.37%/101%,RepVGGB1g2在精度相同的情况下比ResNet-152提高了2.66倍。
虽然参数的数量不是主要问题,但可以看到以上所有的RepVGG模型都比ResNets更有效地利用参数。
与经典的VGG-16相比,RepVGG-B2的参数仅为58%,运行速度提高10%,准确率提高6.57%。
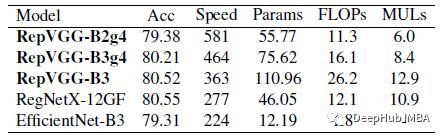
RepVGG模型在200个epoch的精度达到80%以上。RepVGG-A2比effecentnet - b0性能好1.37%/59%,RepVGG-B1比RegNetX-3.2GF性能好0.39%,运行速度也略快。
4、消融研究
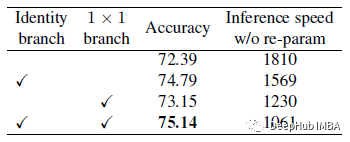
去除上图所示的这两个分支后,训练时间模型退化为普通模型,准确率仅为72.39%。
使用仅使用1×1卷积和identity层精度都有所下降为 74.79%和73.15%
全功能RepVGGB0模型的准确率为75.14%,比普通普通模型高出2.75%。
分割:
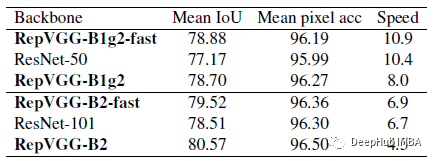
上图为使用修改后的PSPNET框架结果,修改后的PSPNET的运行速度比Resnet-50/101-backbone快得多。REPVGG 的backbone表现都优于Resnet-50和Resnet-101。
下面我们开始使用Pytorch实现
Pytorch实现RepVGG
1、单与多分支模型
要实现RepVGG首先就要了解多分支,多分支就是其中输入通过不同的层,然后以某种方式汇总(通常是相加)。
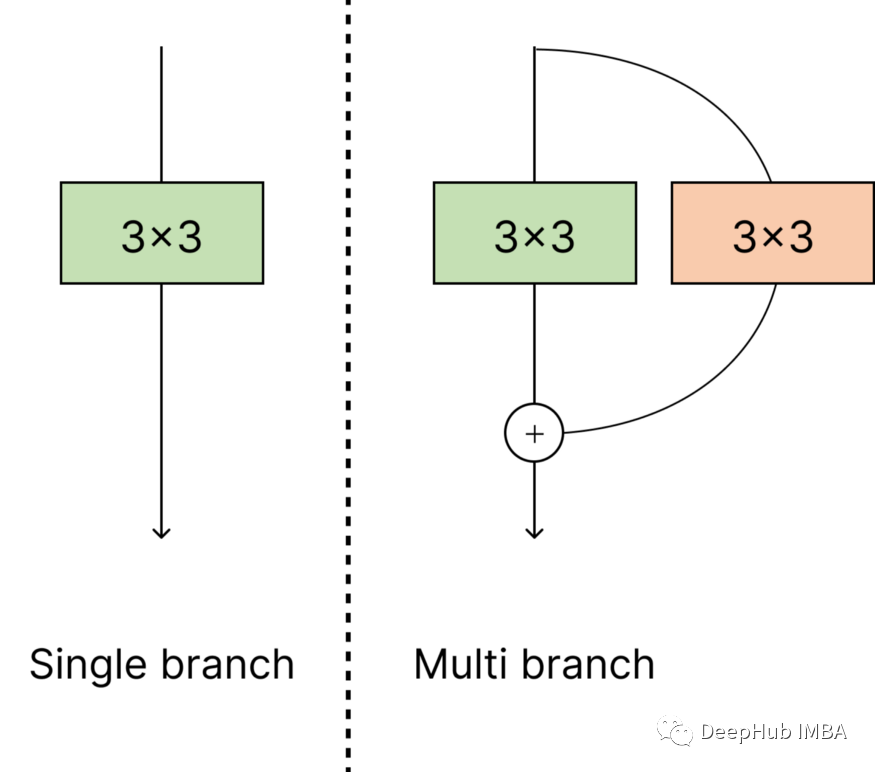
论文中也提到了它使众多较浅模型的隐式集合制造了多分支模型。更具体地说,该模型可以解释为2^n模型的集合,因为每个块将流量分为两个路径。
多分支模型比单分支的模型更慢并且需要消耗更多的内存。我们先创建一个经典的块来了解原因
import torch
from torch import nn, Tensor
from torchvision.ops import Conv2dNormActivation
from typing import Dict, List
torch.manual_seed(0)
class ResNetBlock(nn.Module):
def __init__(self, in_channels: int, out_channels: int, stride: int = 1):
super().__init__()
self.weight = nn.Sequential(
Conv2dNormActivation(
in_channels, out_channels, kernel_size=3, stride=stride
),
Conv2dNormActivation(
out_channels, out_channels, kernel_size=3, activation_layer=None
),
)
self.shortcut = (
Conv2dNormActivation(
in_channels,
out_channels,
kernel_size=1,
stride=stride,
activation_layer=None,
)
if in_channels != out_channels
else nn.Identity()
)
self.act = nn.ReLU(inplace=True)
def forward(self, x):
res = self.shortcut(x) # <- 2x memory
x = self.weight(x)
x += res
x = self.act(x) # <- 1x memory
return x
存储残差会的有2倍的内存消耗。在下面的图像中,使用上面的图
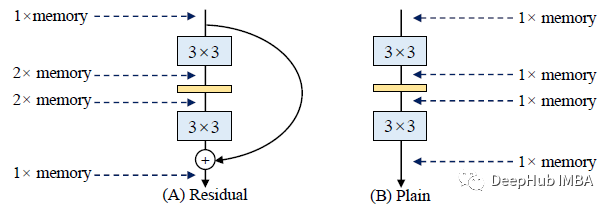
多分支的结构仅在训练时才有用。因此,如果可以在预测时间删除它,是可以改善模型速度和内存消耗的,我们来看看代码怎么做:
2、从多分支到单分支
考虑以下情况,有两个由两个3x3 Convs组成的分支
class TwoBranches(nn.Module):
def __init__(self, in_channels: int, out_channels: int):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=3)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x)
return x1 + x2
看看结果
two_branches = TwoBranches(8, 8)
x = torch.randn((1, 8, 7, 7))
two_branches(x).shape
torch.Size([1, 8, 5, 5])
现在,创建一个convv,我们称其为“ conv_fused”,conv_fused(x) = conv1(x) + conv2(x)。我们可以将两个卷积的权重和偏置求和,根据卷积的特性这是没问题的。
conv1 = two_branches.conv1
conv2 = two_branches.conv2
conv_fused = nn.Conv2d(conv1.in_channels, conv1.out_channels, kernel_size=conv1.kernel_size)
conv_fused.weight = nn.Parameter(conv1.weight + conv2.weight)
conv_fused.bias = nn.Parameter(conv1.bias + conv2.bias)
# check they give the same output
assert torch.allclose(two_branches(x), conv_fused(x), atol=1e-5)
让我们对它的速度!
from time import perf_counter
two_branches.to("cuda")
conv_fused.to("cuda")
with torch.no_grad():
x = torch.randn((4, 8, 7, 7), device=torch.device("cuda"))
start = perf_counter()
two_branches(x)
print(f"conv1(x) + conv2(x) tooks {perf_counter() - start:.6f}s")
start = perf_counter()
conv_fused(x)
print(f"conv_fused(x) tooks {perf_counter() - start:.6f}s")
速度快了一倍
conv1(x) + conv2(x) tooks 0.000421s
conv_fused(x) tooks 0.000215s
3、Fuse Conv和Batschorm
BATGNORM被用作卷积块之后层。论文中将它们融合在一起,即conv_fused(x) = batchnorm(conv(x))。
论文的2个公式解释这里截图在一起了,为了方便查看:

代码是这样的:
def get_fused_bn_to_conv_state_dict(
conv: nn.Conv2d, bn: nn.BatchNorm2d
) -> Dict[str, Tensor]:
# in the paper, weights is gamma and bias is beta
bn_mean, bn_var, bn_gamma, bn_beta = (
bn.running_mean,
bn.running_var,
bn.weight,
bn.bias,
)
# we need the std!
bn_std = (bn_var + bn.eps).sqrt()
# eq (3)
conv_weight = nn.Parameter((bn_gamma / bn_std).reshape(-1, 1, 1, 1) * conv.weight)
# still eq (3)
conv_bias = nn.Parameter(bn_beta - bn_mean * bn_gamma / bn_std)
return {"weight": conv_weight, "bias": conv_bias}
让我们看看它怎么工作:
conv_bn = nn.Sequential(
nn.Conv2d(8, 8, kernel_size=3, bias=False),
nn.BatchNorm2d(8)
)
torch.nn.init.uniform_(conv_bn[1].weight)
torch.nn.init.uniform_(conv_bn[1].bias)
with torch.no_grad():
# be sure to switch to eval mode!!
conv_bn = conv_bn.eval()
conv_fused = nn.Conv2d(conv_bn[0].in_channels,
conv_bn[0].out_channels,
kernel_size=conv_bn[0].kernel_size)
conv_fused.load_state_dict(get_fused_bn_to_conv_state_dict(conv_bn[0], conv_bn[1]))
x = torch.randn((1, 8, 7, 7))
assert torch.allclose(conv_bn(x), conv_fused(x), atol=1e-5)
论文就是这样的方式融合了Conv2D和BatchRorm2D层。
其实可以看到论文的目标是一个:将整个模型融合成在一个单一的数据流中(没有分支),使网络更快!
作者提出新的RepVgg块。与ResNet类似是有残差的,但通过identity层使其更快.
继续上面的图,pytorch的代码如下:
class RepVGGBlock(nn.Module):
def __init__(self, in_channels: int, out_channels: int, stride: int = 1):
super().__init__()
self.block = Conv2dNormActivation(
in_channels,
out_channels,
kernel_size=3,
padding=1,
bias=False,
stride=stride,
activation_layer=None,
# the original model may also have groups > 1
)
self.shortcut = Conv2dNormActivation(
in_channels,
out_channels,
kernel_size=1,
stride=stride,
activation_layer=None,
)
self.identity = (
nn.BatchNorm2d(out_channels) if in_channels == out_channels else None
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
res = x # <- 2x memory
x = self.block(x)
x += self.shortcut(res)
if self.identity:
x += self.identity(res)
x = self.relu(x) # <- 1x memory
return x
4、参数的重塑
一个3x3 conv-> bn,一个1x1 conv-bn和(有时)一个batchnorm(identity分支)。要想将它们融合在一起,创建一个conv_fused,conv_fused
=
3x3conv-bn(x) + 1x1conv-bn(x) + bn(x),或者如果没有identity层,conv_fused
=
3x3conv-bn(x) + 1x1conv-bn(x)。
为了创建这个conv_fused,我们需要做如下的操作:
- 将3x3conv-bn(x)融合到一个3x3conv中
- 1x1conv-bn(x),然后将其转换为3x3conv
- 将identity的BN转换为3x3conv
- 所有三个3x3convs相加
下图就是论文的总结:
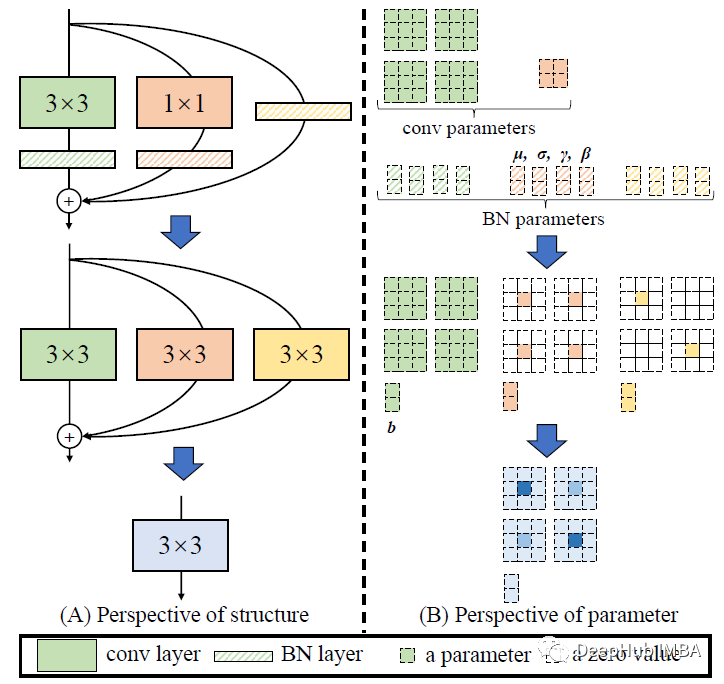
第一步很容易,我们可以在RepVGGBlock.block(主3x3 Conver-bn)上使用get_fused_bn_to_conv_state_dict。
第二步也类似的,在RepVGGBlock.shortcut上(1x1 cons-bn)使用get_fused_bn_to_conv_state_dict。这就是论文说的在每个维度上用1填充融合的1x1的核,形成一个3x3。
identity的bn比较麻烦。论文的技巧(trick)是创建3x3 Conv来模拟identity,它将作为一个恒等函数,然后使用get_fused_bn_to_conv_state_dict将其与identity bn融合。还是通过在对应的内核中心为对应的通道的权重设置成1来实现。
Conv的权重是in_channels, out_channels, kernel_h, kernel_w。如果我们要创建一个identity ,conv(x) = x,我只需要将权重设为1即可,代码如下:
with torch.no_grad():
x = torch.randn((1,2,3,3))
identity_conv = nn.Conv2d(2,2,kernel_size=3, padding=1, bias=False)
identity_conv.weight.zero_()
print(identity_conv.weight.shape)
in_channels = identity_conv.in_channels
for i in range(in_channels):
identity_conv.weight[i, i % in_channels, 1, 1] = 1
print(identity_conv.weight)
out = identity_conv(x)
assert torch.allclose(x, out)
结果
torch.Size([2, 2, 3, 3])
Parameter containing:
tensor([[[[0., 0., 0.],
[0., 1., 0.],
[0., 0., 0.]], [[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]],
[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]], [[0., 0., 0.],
[0., 1., 0.],
[0., 0., 0.]]]], requires_grad=True)
我们创建了一个Conv,它的作用就像一个恒等函数。把所有的东西放在一起,就是论文中的参数重塑。
def get_fused_conv_state_dict_from_block(block: RepVGGBlock) -> Dict[str, Tensor]:
fused_block_conv_state_dict = get_fused_bn_to_conv_state_dict(
block.block[0], block.block[1]
)
if block.shortcut:
# fuse the 1x1 shortcut
conv_1x1_state_dict = get_fused_bn_to_conv_state_dict(
block.shortcut[0], block.shortcut[1]
)
# we pad the 1x1 to a 3x3
conv_1x1_state_dict["weight"] = torch.nn.functional.pad(
conv_1x1_state_dict["weight"], [1, 1, 1, 1]
)
fused_block_conv_state_dict["weight"] += conv_1x1_state_dict["weight"]
fused_block_conv_state_dict["bias"] += conv_1x1_state_dict["bias"]
if block.identity:
# create our identity 3x3 conv kernel
identify_conv = nn.Conv2d(
block.block[0].in_channels,
block.block[0].in_channels,
kernel_size=3,
bias=True,
padding=1,
).to(block.block[0].weight.device)
# set them to zero!
identify_conv.weight.zero_()
# set the middle element to zero for the right channel
in_channels = identify_conv.in_channels
for i in range(identify_conv.in_channels):
identify_conv.weight[i, i % in_channels, 1, 1] = 1
# fuse the 3x3 identity
identity_state_dict = get_fused_bn_to_conv_state_dict(
identify_conv, block.identity
)
fused_block_conv_state_dict["weight"] += identity_state_dict["weight"]
fused_block_conv_state_dict["bias"] += identity_state_dict["bias"]
fused_conv_state_dict = {
k: nn.Parameter(v) for k, v in fused_block_conv_state_dict.items()
}
return fused_conv_state_dict
最后定义一个RepVGGFastBlock。它只是由conv + relu组成
class RepVGGFastBlock(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int, stride: int = 1):
super().__init__()
self.conv = nn.Conv2d(
in_channels, out_channels, kernel_size=3, stride=stride, padding=1
)
self.relu = nn.ReLU(inplace=True)
并在RepVGGBlock中添加to_fast方法来快速创建RepVGGFastBlock
class RepVGGBlock(nn.Module):
def __init__(self, in_channels: int, out_channels: int, stride: int = 1):
super().__init__()
self.block = Conv2dNormActivation(
in_channels,
out_channels,
kernel_size=3,
padding=1,
bias=False,
stride=stride,
activation_layer=None,
# the original model may also have groups > 1
)
self.shortcut = Conv2dNormActivation(
in_channels,
out_channels,
kernel_size=1,
stride=stride,
activation_layer=None,
)
self.identity = (
nn.BatchNorm2d(out_channels) if in_channels == out_channels else None
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
res = x # <- 2x memory
x = self.block(x)
x += self.shortcut(res)
if self.identity:
x += self.identity(res)
x = self.relu(x) # <- 1x memory
return x
def to_fast(self) -> RepVGGFastBlock:
fused_conv_state_dict = get_fused_conv_state_dict_from_block(self)
fast_block = RepVGGFastBlock(
self.block[0].in_channels,
self.block[0].out_channels,
stride=self.block[0].stride,
)
fast_block.conv.load_state_dict(fused_conv_state_dict)
return fast_block
5、RepVGG
switch_to_fast方法来定义RepVGGStage(块的集合)和RepVGG:
class RepVGGStage(nn.Sequential):
def __init__(
self,
in_channels: int,
out_channels: int,
depth: int,
):
super().__init__(
RepVGGBlock(in_channels, out_channels, stride=2),
*[RepVGGBlock(out_channels, out_channels) for _ in range(depth - 1)],
)
class RepVGG(nn.Sequential):
def __init__(self, widths: List[int], depths: List[int], in_channels: int = 3):
super().__init__()
in_out_channels = zip(widths, widths[1:])
self.stages = nn.Sequential(
RepVGGStage(in_channels, widths[0], depth=1),
*[
RepVGGStage(in_channels, out_channels, depth)
for (in_channels, out_channels), depth in zip(in_out_channels, depths)
],
)
# omit classification head for simplicity
def switch_to_fast(self):
for stage in self.stages:
for i, block in enumerate(stage):
stage[i] = block.to_fast()
return self
这样就完成了,下面我们看看测试
6、模型测试
benchmark.py中已经创建了一个基准,在gtx 1080ti上运行不同批处理大小的模型,这是结果:
模型每个阶段有两层,四个阶段,宽度为64,128,256,512。
在他们的论文中,他们将这些值按一定的比例缩放(称为a和b),并使用分组卷积。因为对重新参数化部分更感兴趣,所以这里跳过了,因为这是一个调参的过程,可以使用超参数搜索的方法得出。
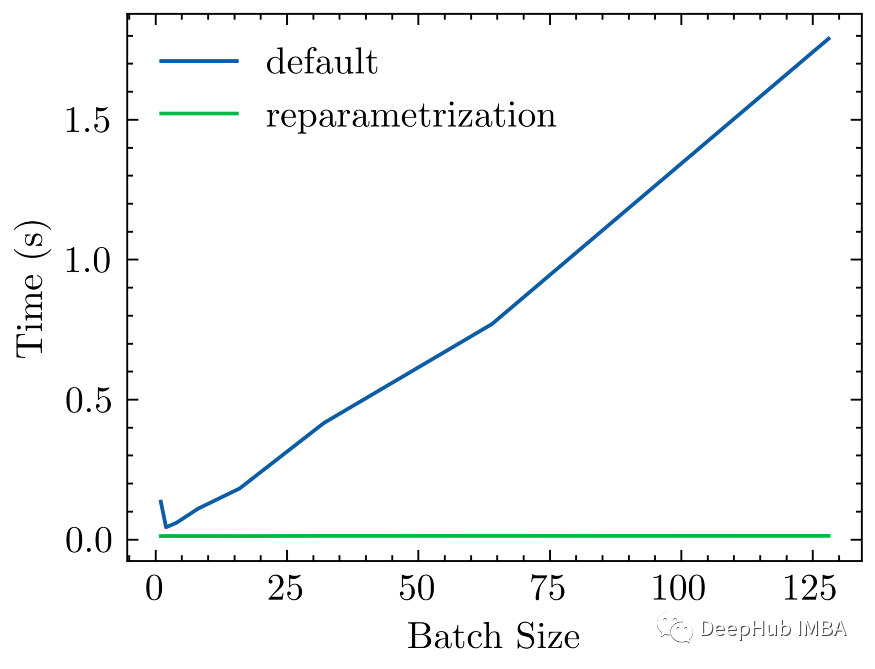
基本上重塑参数的模型与普通模型相比在不同的时间尺度上提升的还是很明显的
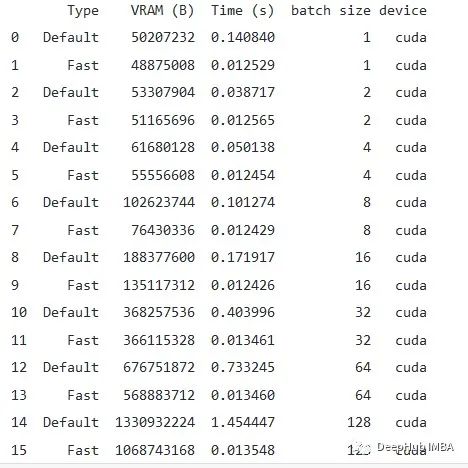
可以看到,对于batch_size=128,默认模型(多分支)占用1.45秒,而参数化模型(快速)只占用0.0134秒。即108倍的提升
总结
在本文中,首先详细的介绍了RepVGG的论文,然后逐步了解了如何创建RepVGG,并且着重介绍了重塑权重的方法,并且用Pytorch复现了论文的模型,RepVGG这种重塑权重技术其实就是使用了过河拆桥的方法,白嫖了多分支的性能,并且还能够提升,你说气不气人。这种“白嫖”的技术也可以移植到其他架构中。
论文地址在这里:
http://arxiv.org/abs/2101.03697
代码在这里:
https://github.com/FrancescoSaverioZuppichini/RepVgg
谢谢阅读!