【2022高教社杯数学建模】C题:古代玻璃制品的成分分析与鉴别方案及代码实现(已经更新完毕)
【2022高教社杯数学建模】C题:古代玻璃制品的成分分析与鉴别方案及代码实现(1)对表1中,统计风化程度与玻璃类型、纹饰、颜色的关系,作出柱状图可视化或者饼状图(2)利用文物采样点结合表1和表2,对不同玻璃类型,再划分有无风化,对化学成分统计,即四种情况求均值求出风化前后的差值(3)线性回归,求风化

使用阈值调优改进分类模型性能
在本文中将演示如何通过阈值调优来提高模型的性能。
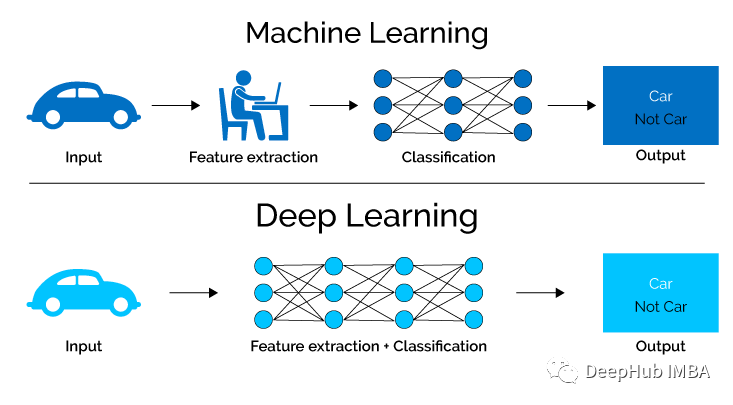
最基本的25道深度学习面试问题和答案
如果你最近正在参加深度学习相关的面试工作,那么这些问题会对你有所帮助。
【机器学习】Logistic 分类回归算法 (二元分类 & 多元分类)
一、线性回归能用于分类吗?二、二元分类2.1假设函数2.1.1例子一2.1.2例子二2.2拟合logistic回归参数\thetaθ三、logistic代价函数3.1 y = 1的图像3.2 y = 0的图像四、 代价函数与梯度下降4.1 线性回归与logistic回归的梯度下降规则相同吗?五、高级
Python 3.14 将比 C++ 更快🤭
使用外推法证明Python 3.14 将比 C++ 更快🤭
哈工大2022机器学习实验一:曲线拟合
本博客采用python的numpy库,用四种方式实现用多项式拟合曲线。
机器学习:过拟合、欠拟合、正则化之间的纸短情长~
正则化是何如解决过拟合的,机器学习的主要挑战是我们的算法能够在为观测的数据上误差较小,而不是在只在训练集上表现良好,我们这种能力我们称之为泛化。
CNN天气识别
本文将采用CNN实现多云、下雨、晴、日出四种天气状态的识别。本文为了增加模型的泛化能力,新增了Dropout层并且将最大池化层调整成了平均池化层。
SVM 支持向量机算法(Support Vector Machine )【Python机器学习系列(十四)】
SVM 支持向量机算法(Support Vector Machine )【Python机器学习系列(十四)】1.SVM简介2. SVM 逻辑推导2.1 Part1 化简限制条件2.2 Part2 SVM拉格朗日乘子法求解2.3 Part3 求解超平面3.核函数4. 软间隔支持向量机5. 支持向量回归

7个有用的Jupyter扩展
今天将介绍7个不常见但是却很好用且能够提高效率的Jupyter扩展
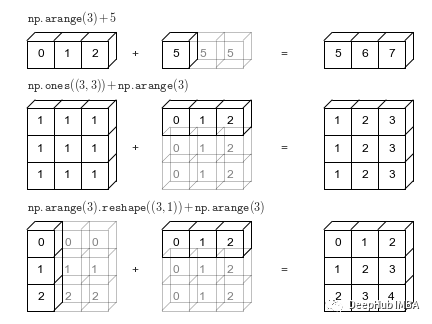
NumPy和Pandas中的广播
在本文中介绍Numpy的广播机制和Pandas中的一些广播的函数,并使用泰坦尼克的数据集演示了pandas上常用的转换/广播操作。
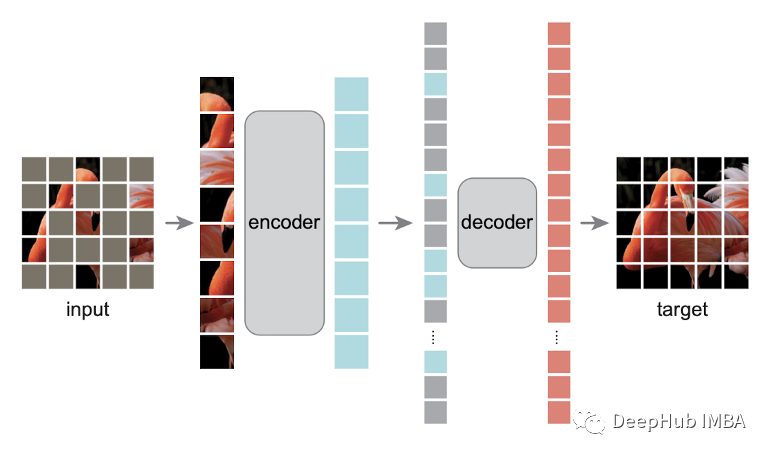
带掩码的自编码器MAE在各领域中的应用总结
NLP,图像,视频,多模态,设置时间序列和图机器学习中都出现了MAE的身影
2022 年最值得关注的颠覆性技术
颠覆性技术是一种创新,会导致消费者、企业和行业运营方式发生重大变化。颠覆性技术有可能通过其可衡量和优越的属性来取代现有的系统或习惯。简单来说,颠覆性技术是一种新技术,它显着改变了现有市场或行业的运作方式。颠覆性技术最初往往会遭到现有企业的抵制,因为它们有可能颠覆现状。然而,随着时间的推移,它们可以彻

使用机器学习创建自己的Emojis 表情
在本文中,我们将描述一种图像生成方法,该方法无需额外的模型训练和昂贵的设备就可以在不同的图像风格之间切换。
写完Numpy100道基础练习题后的错误总结和语法总结
numpy100题错误总结和语法总结!!我都已经踩了无数个雷了!!
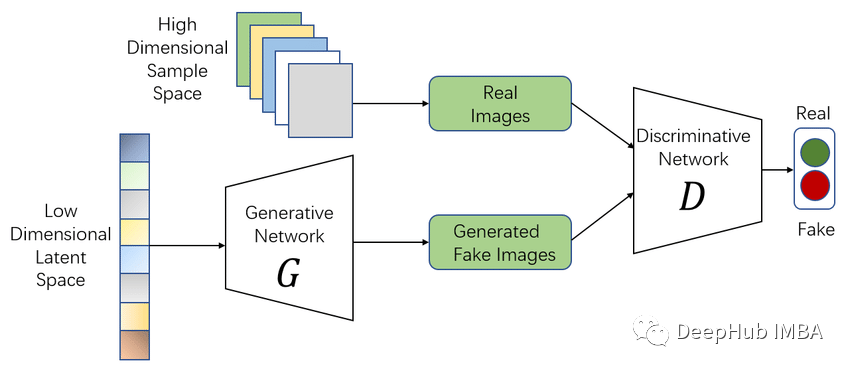
GANs的优化函数与完整损失函数计算
本文详细解释了GAN优化函数中的最小最大博弈和总损失函数是如何得到的。将介绍原始GAN中优化函数的含义和推理,以及它与模型的总损失函数的区别,这对于理解Generative Adversarial Nets是非常重要的

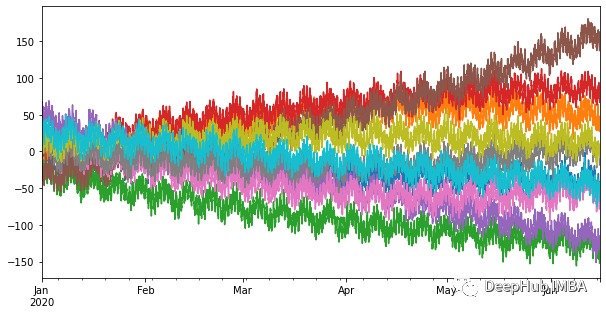
时间序列中的特征选择:在保持性能的同时加快预测速度
在这篇文章中,我们展示了特征选择在减少预测推理时间方面的有效性,同时避免了性能的显着下降。tspiral 是一个 Python 包,它提供了各种预测技术。并且它与 scikit-learn 可以完美的集成使用。
【毕业设计】基于机器学习与大数据的糖尿病预测
本项目以体检数据集为样本进行了机器学习的预测,但是需要注意几个问题:体检数据量太少,仅有1006条可分析数据,这对于糖尿病预测来说是远远不足的,所分析的结果代表性不强。这里的数据糖尿病和正常人基本相当,而真实的数据具有很强的不平衡性。也就是说,糖尿病患者要远少于正常人,这种不平衡的数据集给真实情况下
分类模型评估的实际编码
从实际编码的角度出现看看如何用代码评价分类模型的好坏。



