
系列文章目录
- 手把手带你玩转Spark机器学习-专栏介绍
- 手把手带你玩转Spark机器学习-问题汇总
- 手把手带你玩转Spark机器学习-Spark的安装及使用
- 手把手带你玩转Spark机器学习-使用Spark进行数据处理和数据转换
- 手把手带你玩转Spark机器学习-使用Spark构建分类模型
- 手把手带你玩转Spark机器学习-使用Spark构建回归模型
- 手把手带你玩转Spark机器学习-使用Spark构建聚类模型
- 手把手带你玩转Spark机器学习-使用Spark进行数据降维
文章目录
前言
本章,我们将继续讲解无监督学习模型中降低数据维度的方法。
不同于我们之前分享的回归、分类和聚类,降维方法并不是用来做模型预测的。降维方法从一个D维的数据输入提取出k维表示,k一般远远小于D。因此,降维方法本身是一种预处理方法,或者说是一种特征转换的方法,而不是模型预测的方法。
降维方法中尤为重要的是,被抽取出的维度表示应该仍能捕捉大部分的原始数据的变化和结构。这源于一个基本想法:大部分数据源包含某种内部结构,这种结构一般来说是未知的(常被称为隐含特征或潜在特征),但如果能发现结构中的一些特征,我们的模型就可以学习这种结构并从中预测,而不用从大量无关的充满噪音特征的原始数据中去学习预测。简言之,缩减维度可以排除数据中的噪音并保留数据原有的隐含结构。
有时候,原始数据的维度远高于我们拥有的数据点数目。不降维,直接使用分类、回归等方法进行机器学习建模将非常困难。因为需要拟合的参数数目远大于训练样本的数目(从这个意义上讲,这种方法和我们在分类和回归中用的正则化方法相似)。
我们常常在一些场景中使用上述的降维技术,比如说探索性数据分析、提取体征去训练其他机器学习模型、降低大型模型在预测阶段的存储和计算需求、以及处理文本、声音、图像、视频等非常高维的数据。
本文以银行营销数据集为例,演示如何利用PCA进行数据降维,并将其可视化,方便大家的理解。
文章中涉及到的code可到本人github处下载:SparkML
一、获取数据集
银行营销数据集来自于UCL ML数据库,它包含有以下字段:
[‘age’, ‘job’, ‘marital’,‘education’, ‘default’, ‘balance’, ‘housing’, ‘loan’, ‘campaign’, ‘pdays’, ‘previous’, ‘poutcome’, ‘y’]
它们是“年龄”、“工作”、“婚姻”、“教育”、“默认”、“平衡”、“住房”、“贷款”、“活动”等特征。
二、数据预处理
1.选择感兴趣的特征列
cols =['age','job','marital','education','default','balance','housing','loan','campaign','pdays','previous','poutcome','y']
df2 = df.select(cols)
df2.show(4)

如上图所示,我们可以根据经验,选择对我们模型建模有效的一些特征列。
2.删除缺失数据
同时由于数据中存在一些缺失值,因此我们也可以将一些含有缺失数据的行删除:
df2.createOrReplaceTempView("bank")
df2 = spark.sql("SELECT * FROM bank WHERE bank.poutcome='success' or bank.poutcome='failure'")
df2.createOrReplaceTempView("bank")
df2 = df2.filter(~df.age.contains("unknown"))
df2 = df2.filter(~df.job.contains("unknown"))
df2 = df2.filter(~df.marital.contains("unknown"))
df2 = df2.filter(~df.education.contains("unknown"))
df2 = df2.filter(~df.default.contains("unknown"))
df2 = df2.filter(~df.balance.contains("unknown"))
df2 = df2.filter(~df.housing.contains("unknown"))
df2 = df2.filter(~df.loan.contains("unknown"))
df2 = df2.filter(~df.campaign.contains("unknown"))
df2 = df2.filter(~df.pdays.contains("unknown"))
df2 = df2.filter(~df.previous.contains("unknown"))
df2 = df2.filter(~df.poutcome.contains("unknown"))
df2 = df2.filter(~df.y.contains("unknown"))
df2.show(4)

3.分类变量编码
数据包含工作、婚姻、教育、违约、住房、贷款等分类变量。我们首先使用 StringIndexer 将分类值转换为类别索引,然后由 OneHotEncoder 为每一列将其转换为二进制向量列,如下所示:
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, OneHotEncoder
stringIndexer = StringIndexer(inputCol="job", outputCol="job_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="job_index", outputCol="job_vec")
encoded = encoder.transform(indexed)
df2 = encoded
stringIndexer = StringIndexer(inputCol="marital", outputCol="marital_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="marital_index", outputCol="marital_vec")
encoded = encoder.transform(indexed)
df2 = encoded
stringIndexer = StringIndexer(inputCol="education", outputCol="education_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="education_index", outputCol="education_vec")
encoded = encoder.transform(indexed)
df2 = encoded
stringIndexer = StringIndexer(inputCol="default", outputCol="default_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="default_index", outputCol="default_vec")
encoded = encoder.transform(indexed)
df2 = encoded
stringIndexer = StringIndexer(inputCol="housing", outputCol="housing_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="housing_index", outputCol="housing_vec")
encoded = encoder.transform(indexed)
df2 = encoded
stringIndexer = StringIndexer(inputCol="loan", outputCol="loan_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="loan_index", outputCol="loan_vec")
encoded = encoder.transform(indexed)
df2 = encoded
stringIndexer = StringIndexer(inputCol="poutcome", outputCol="poutcome_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="poutcome_index", outputCol="poutcome_vec")
encoded = encoder.transform(indexed)
df2 = encoded
stringIndexer = StringIndexer(inputCol="y", outputCol="y_index")
model = stringIndexer.fit(df2)
indexed = model.transform(df2)
encoder = OneHotEncoder(dropLast=False, inputCol="y_index", outputCol="y_vec")
encoded = encoder.transform(indexed)
df2 = encoded
df2.show(4)

4.缩放标准化
数据通过缩放标准化,如下所示,我们对连续类别的数据进行缩放标准化:
from pyspark.ml.feature import MinMaxScaler
cols =['job','marital','education','default','housing','loan','poutcome','y']for col in cols:
scaler = MinMaxScaler(inputCol=col+"_vec", outputCol=col+"_vec_scaled")
scalerModel = scaler.fit(df2)
scaledData = scalerModel.transform(df2)
df2 = scaledData
df2.show(4)

5.PCA降维
我们利用PCA对上述特征进行特征降维,为了方便可视化,我们k选择为2
from pyspark.ml.feature import PCA
import matplotlib.pyplot as plt
pca = PCA(k=2, inputCol="features", outputCol="pcaFeatures")
model = pca.fit(df3)
result = model.transform(df3).select("pcaFeatures")
pandasDf = result.toPandas()
dataX =[]
dataY =[]for vec in pandasDf.values:
dataX.extend([vec[0][0]])
dataY.extend([vec[0][1]])
plt.scatter(dataX, dataY)
plt.show()
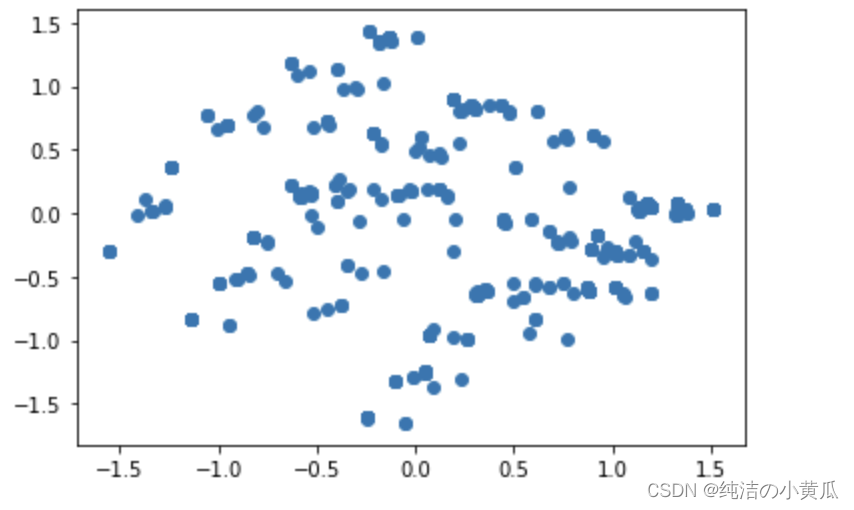
如上图,可以看出有明显三个簇,我们可以再利用无监督算法k-means,进行聚类,聚成三类,看看对应的id是不是能匹配上,如果能匹配上,说明PCA降维还是保留了原始数据的结构。
总结
本文以银行营销数据集为例,演示了数据获取、缺失值处理、特征选择及标准化操作,最后讲解了如何利用PCA进行数据降维。PCA作为一种数据降维方法,在遇到内存瓶颈及时间瓶颈下尤为有效,可以迅速在保证效果的前提下,降低数据维度,降低内存,提高模型训练速度。
版权归原作者 纯洁の小黄瓜 所有, 如有侵权,请联系我们删除。