分类判别式模型——逻辑斯特回归曲线
本文介绍了分类的判别式模型,从以往机器学习的三大步骤引入;在寻找最优解中,比较了与线性回归梯度下降法的不同;在损失函数层面,比较了交叉熵和square error的差异;在分类模型上,比较是本专栏上文的分类生成模型。最后在多分类问题上进行了扩展,在无法解决的同或问题中引入了特征映射和神经网络的概念。
带掩码的自编码器(MAE)最新的相关论文推荐
7-9月的MAE相关的9篇论文推荐
哈工大2022机器学习实验二:逻辑回归
逻辑回归,又意译为对率回归,虽然它的名字中带“回归”,但它是一个分类模型。它的基本思想是直接估计条件概率P(Y|X)的表达式,即给定样本X=x,其属于类别Y的概率。
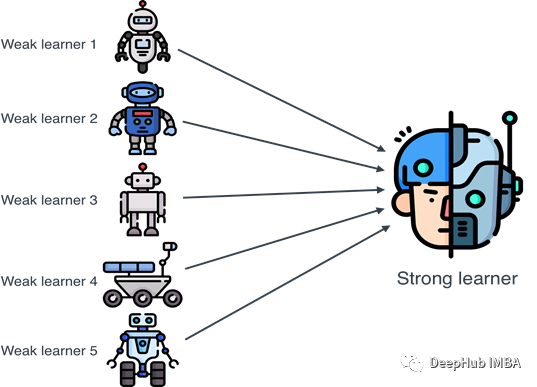
机器学习模型的集成方法总结:Bagging, Boosting, Stacking, Voting, Blending
集成学习是一种元方法,通过组合多个机器学习模型来产生一个优化的模型,从而提高模型的性能。集成学习可以很容易地减少过拟合,避免模型在训练时表现更好,而在测试时不能产生良好的结果。
Python中的层次聚类,详细讲解
机器学习中的层次聚类,python实现
“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享
“华为杯”第十八届中国研究生数学建模竞赛一等奖经验分享。
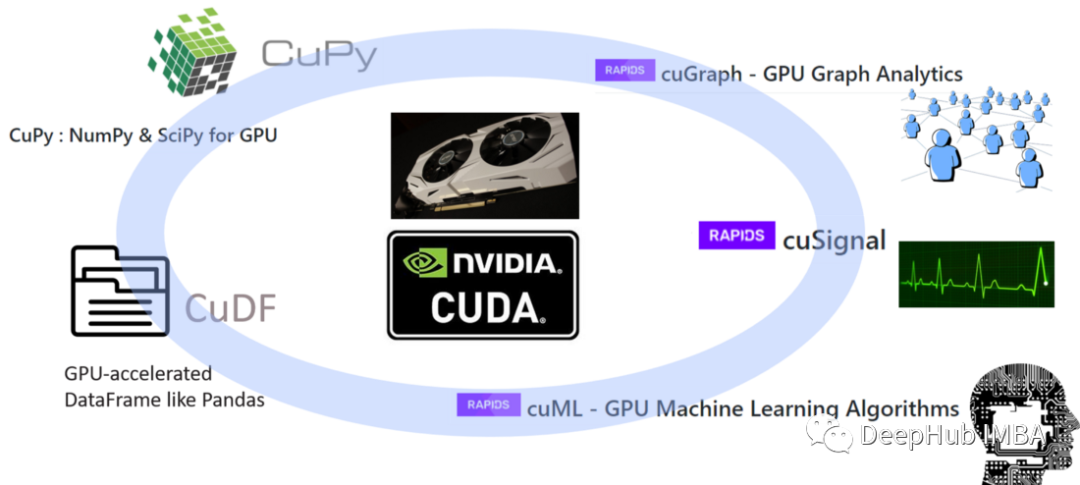
在gpu上运行Pandas和sklearn
Pandas和sklearn这两个是我们最常用的基本库,Rapids将Pandas和sklearn的功能完整的平移到了GPU之上

超长时间序列数据可视化的6个技巧
本文展示了6种用于绘制长时间序列数据的可视化方法,通过使用交互函数和改变视角,我可以使结果变得友好并且能够帮助我们更加关注重要的数据点。
Python实现基于机器学习的手写数字识别系统
安装好的OpenCV中有自带的分类器,但是很不幸的是自带的分类器仅有关于人脸识别方向的,如果是做人脸识别方向的研究使用该分类器将会非常方便。本章将介绍如何使用计算机视觉库OpenCV调用电脑摄像头、找到帧画面中的数字并对数字进行识别前的处理,最后调用训练好的手写数字模型将识别结果在原帧画面中显示出来
机器学习:详解半朴素贝叶斯分类AODE原理(附Python实现)
朴素贝叶斯中的属性独立性假设在实际上很难成立,因此引入半朴素贝叶斯分类器,其核心思想是:适当考虑部分属性的相互依赖。本文介绍典型的半朴素贝叶斯分类AODE原理及Python实现

生成模型VAE、GAN和基于流的模型详细对比
生成算法有很多,但属于深度生成模型类别的最流行的模型是变分自动编码器(VAE)、gan和基于流的模型。
python大数据之异常值处理
对于数据异常值处理,我的理解是,这里的异常值不是代表数据出现的异常,而是对于你需要建立的模型来说,处于异常值。比如你需要正太分布的数据,那么一些不符合正太分布,或者离群太远的值,可以更具你的需要去进行删除,这样你的模型效果就会更好
嵌入式软件编程模式
这里讨论的编程模式主要针对没有操作系统的嵌入式软件运行环境,在这种情况下,CPU的全部算力可以分配到和应用相关的计算,不需要额外执行IO资源状态、内存清理、调度等软件操作系统的管理任务,因此运行效率和内存使用效率会更高,但付出的代价是需要手动管理任务并发、IO状态检查、资源共享等,对开发者有更高的要
《计算机视觉基础知识蓝皮书》第2篇 深度学习基础
深度学习基础知识精讲
【python-Unet】计算机视觉~舌象舌头图片分割~机器学习
舌象数据集包含舌象原图以及分割完成的二元图,共979*2张,示例图片如下:U-Net是一个优秀的语义分割模型,在中e诊中U-Net共三部分,分别是主干特征提取部分、加强特征提取部分、预测部分。利用主干特征提取部分获得5个初步有效的特征层,之后通过加强特征提取部分对上述获取到的5个有效特征层进行上采样

[数据结构] 链表(图文超详解讲解)
根据本文对链表的介绍后大家能对链表有更深的理解相信大家在过后时间能够保持求学的态度,我们一起加油!offer拿到手软!对博主感兴趣可以关注博主,我会继续更新博客,努力完善我的文章内容不会辜负大家的期待!
Nature子刊:一个从大脑结构中识别阿尔茨海默病维度表征的深度学习框架
脑部疾病的异质性是精准诊断/预后的一个挑战。作者描述并验证了一种名为Smile-GAN(SeMI-supervised cLustEring-Generative Adversarial Network),的半监督深度聚类方法,它研究了与正常大脑结构对比的神经解剖学异质性,从而通过神经影像特征识别疾
【国庆特辑文章】时间序列~动态时间规整(Dynamic Time Wraping)
解决的问题:测量两端时间序列的相似性




