
在本篇文章中,我们将讨论机器学习和深度学习的不同领域中的一个热门话题:零样本和少样本学习(Zero and Few Shot learning),它们在自然语言处理到计算机视觉中都有不同的应用场景。
少样本学习
在监督分类器中,所有的模型试图学习的是区分不同的对象的的特征,无论数据是什么形式存在的,例如图像、视频还是文本都是一样的。而·少样本学习的思想是通过比较数据来学习区分类,这样模型使用的数据更少,并且比经典模型表现得更好。在少样本学习中通常会使用支持集(support set)代替训练集。
少样本学习是一种元学习技术。元学习的意思是:学会学习。元学习是元认知的一个分支,研究的是对自身学习和学习过程的方法和认知过程。
支持集
支持集其实与训练集的数据是一样的,但由于学习方法不同所以我们称之为支持集。
K-Way N-Shot支持集:支持集具有K类,每个类都有N样本。N-Shot意味着为每个类提供的样本数。如果每个另类都有更多样本,模型可以学习的更好。
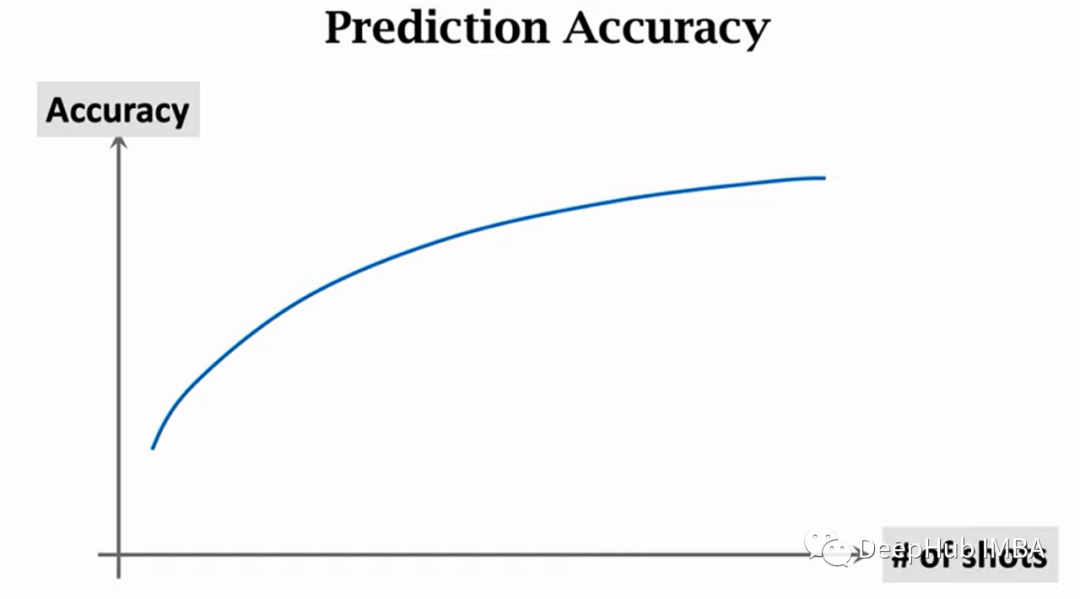
在较少的类中,模型可以更轻松地对数据进行分类。总的来说,我们可以说:更少的k和更多的n更好。
为什么把他成做支持集呢?还记得SVM中的支持向量吗,就是SVM中区别分类边界的数据,支持集也是这个意思。
相似性函数
少样本学习的想法是相似性函数。这意味着应该计算SIM(X,X’),其中“ SIM”是相似性函数,而X和X’是样本。首先要做的是从大型数据集中学习相似性函数。然后将相似性函数应用于预测。
孪生网络
孪生网络使用正面和负样本进行分类。以下是正和负样本的示例:
(Tiger1,Tiger2,1)| (CAR1,CAR2,1)
(Tiger1,Car2,0)| (Tiger1,Car1,0)
网络结构就是这样:
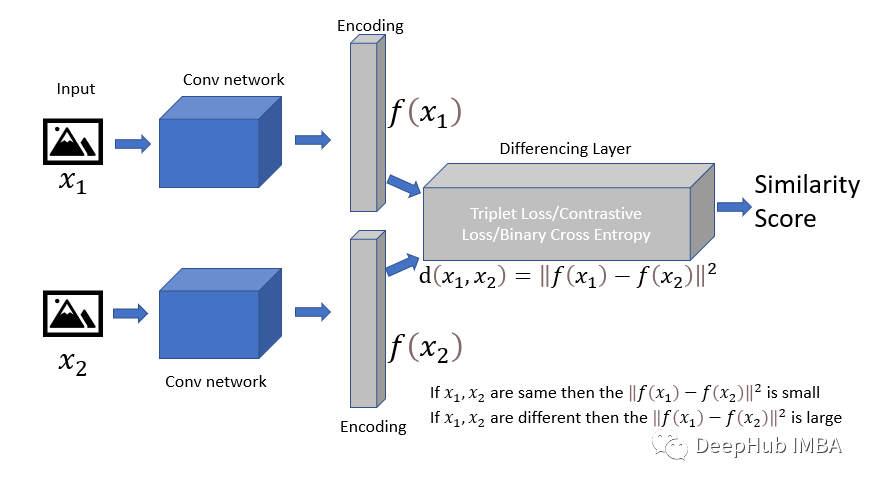
孪生网络首先使用数据集中的两个图像,然后使用一些层(在这里的图像数据示例,使用卷积层),创建输入的编码向量。最后使用差异层和不同的损失函数尝试学习相似性函数。
输入该网络的数据是:
- XA:锚数据:从数据集随机选择
- X+:正数据:与锚相同的类
- X-:负数据:锚不同的类别
F函数(CNN)用于创建编码向量。在编码向量后,我们可以使用:
D+ = || f(x^+) - f(x^a)||²
d- = || f(x^a)-f(x^ - )||²
有了边缘alpha和相似性值,我们可以决定样本的类别。
我们希望d-> =(d +) + alpha,否则,损失为(d +) + alpha-(d-)。
因此损失函数是:max {(d +) + alpha-(d-)}
Few-Shot
少样本学习的基本思想是给定一个k-way n-shot的支持集,在大规模训练集上训练一个暹罗网络。然后使用查询的方式来预测样本的类别。
在训练少样本学习之前,首先我们预训练CNN的特征提取(又称嵌入),使用标准监督学习或Siamese网络对CNN进行预训练。
在微调中,(x_j, y_j)是支持集中有标记的样本。f(x_j)是经过预训练的CNN提取的特征向量。P_j = Softmax(W.f(x_j)+b)作为预测。这可以通过使用微调来让W = M,b = 0。,这意味着在支持集中学习W和b:
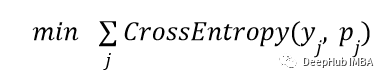
样例
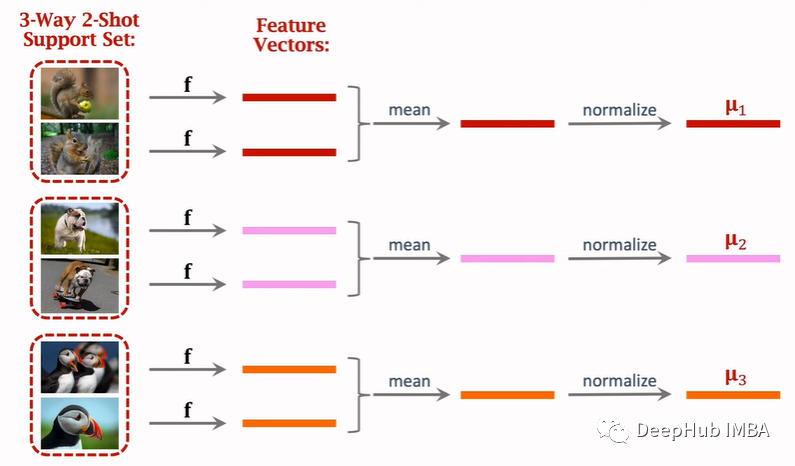
考虑 3-way 2-shot的支持集。在每个图像上应用神经网络F以进行特征提取。由于每个类都有两个图像,因此每个类都有两个特征向量。可以得到这两个向量的均值。由于我们有3类别,我们将有3个平均的向量。现在我们把它们标准化。每个向量是每个类的表示。对于预测,我们输入一个查询图像。得到查询图像的特征向量。我们再将其标准化,然后将这个向量与3个均值向量进行比较。
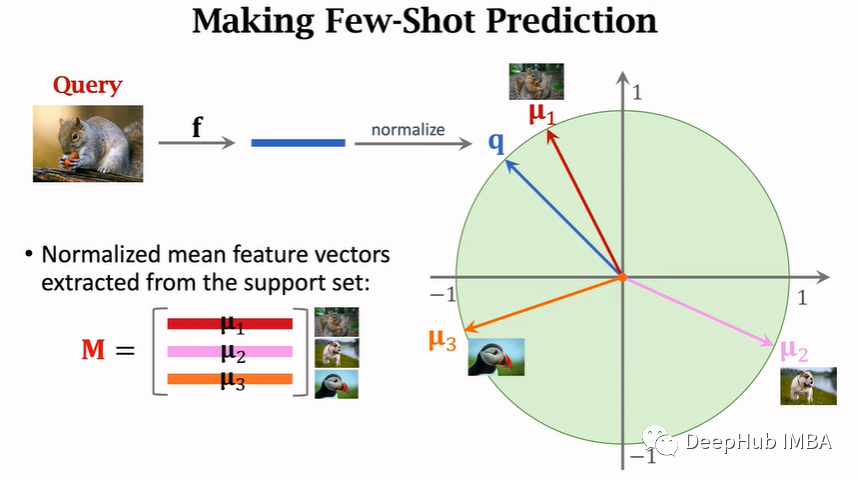
通过比较这样就得到了我们的预测分类
单样本学习
one-shot learning是少样本学习的一种特殊情况,即从一个样本学习并再次识别物体。
单样本的一种方法是使用CNN和带有(n+1)的softmax来检测模型看到的图像中是否存在新的图像。但是当你的训练数据集中没有足够的样本时,他并不能很好地工作。并且除了新的类别外还必须在SoftMax层中使用(M+1)神经元再次训练模型。
但是我们可以使用相似函数。
d(img1, img2) =图像间差异程度,若d(img1, img2) <= r:相同;若d(img1, img2) > r:不同
零样本学习
首先,让我们看看为什么零样本学习很重要。我们面对的是数量庞大且不断增长的类别。很难收集和注释实例。并且新的类别不断出现。
零样本学习是人类可以做到的,但是经典的机器学习不能。例如跨语言字典归纳(每一对语言,每个单词是一个类别)。
从监督到零样本的模式识别
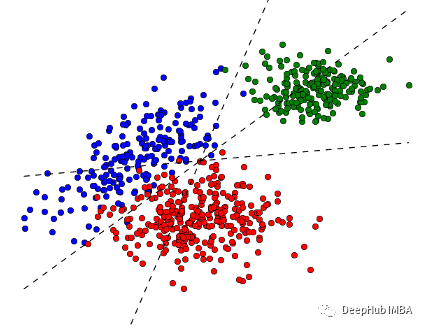
我们以前在经典的分类模型中的做法是这样的:
但当出现新的类别时,该怎么做呢?关键是零样本学习。零样本学习的主要思想是将类别嵌入为向量。
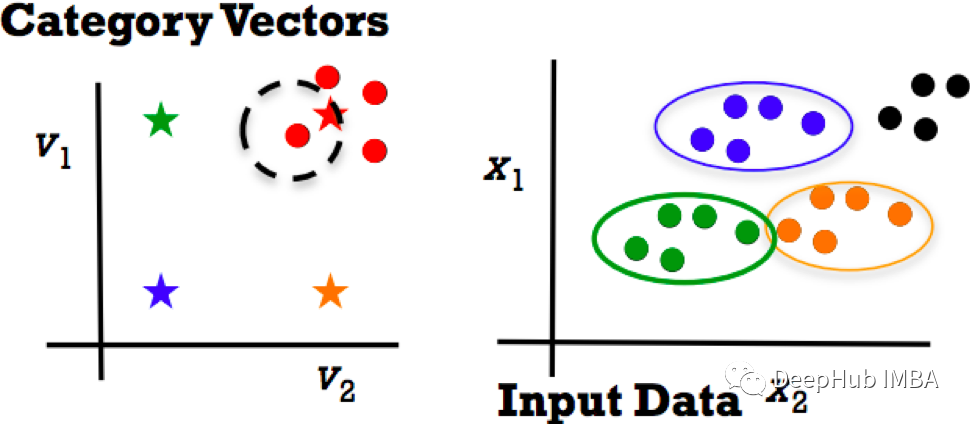
特征类别向量映射:v = f(x)
如果出现了新的类别,我们可以得到其新的类别向量嵌入,然后使用最近的邻居并将这些向量视为标签。数据类别向量图可以推广到新类别。相当于我们正在从过去的经验中进行迁移学习。
零样本学习是如何工作的?
在回归/分类方法的训练步骤中,我们会得到一些已知的类-类别向量v和数据x。而我们想要学习的是数据属性v=f(x)。例如使用支持向量机(SVM)。
在测试阶段,我们想要为新类指定向量v。然后使用f(x)来查找新的分类。这种方法简单且快速,而且还具有类别的可分离性。
在零样本学习中,使用energy函数来判断类别是否匹配。设x是数据,v是类别向量。在训练阶段,我们训练energy函数E(x,v)=x 'Wv(这被称为返回标量的双线性嵌入)。
数据和任务匹配(x=v)时E_w(x,v)会变得很大,当数据和任务不匹配时(x!=v),E_w(x,b)很小。训练的目标是最大化这个函数的边缘间距。
而在测试阶段:
分类新类实例x*,为一些新类指定v向量计算每个v的E(x, v),找到最大边际的类别,最大边际可分离性意味着更高的准确性,但与经典的机器学习模型不同,它是复杂和缓慢的。
从哪里获得类别向量呢?
“监督”来源:(1)类属性的手工标注,(2)分类类层次的矢量编码
“无监督”来源:现有的非结构化数据(Word2Vec就是一个例子)
零样本学习的一些问题
1、领域转移时零样本学习需要重新训练/测试
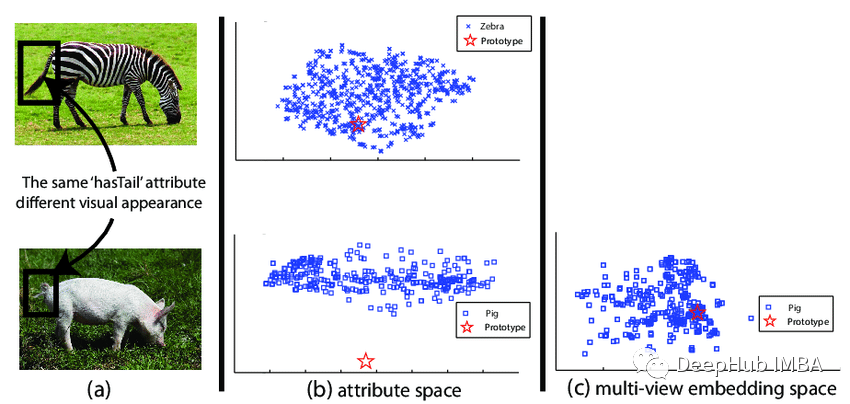
2、多标签zero-shot
有时我们想要多标签分类,而不是单标签分类,这是处理分类向量就会很麻烦,这时可以添加每一个可能的组合向量,例如:树,树+山,树+海滩,…,但是这其实造成了实际分类数量的成倍的增长。
3、深度网络能够进行零样本学习
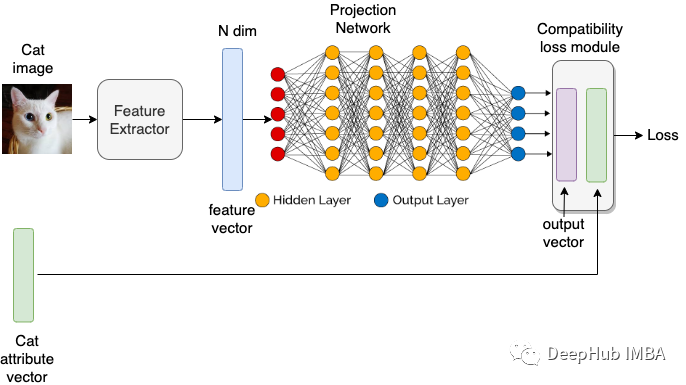
将许多经典的和最新的迁移学习算法作为特殊情况目前还无法验证否有好处
目前零样本学习的进展和应用
1、将其用于音频识别|无人机视觉类向量=>上下文向量,通过上下文向量对任何新的上下文进行泛化例如在无人机视觉中,协变量上下文向量:距离、俯仰、速度、横摇、偏航等
2、跨语言词典归纳:查找不同语言的单词对应
总结
零样本和少样本学习方法减少了对注释数据的依赖。因此对于新的领域和收集数据的困难的领域他们是很重要的。少样本(Few-Shot Learning FSL)是一种机器学习问题(由E, T和P指定),其中E只包含有限数量的例子,并带有监督信息。现有的FSL问题主要是监督学习问题。零样本学习(Zero-shot learning, ZSL)是机器学习中的一个问题解决方案,学习者在测试时从训练中没有观察到的类中观察样本,并预测他们所属的类。
作者:Amirhossein Abaskohi