
1、mixup
论文地址:https://arxiv.org/pdf/1710.09412.pdf
mixup通过以下方式构建虚拟的训练样本:
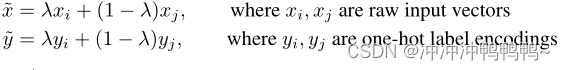
式中,(xi,yi)和(xj,yj)是从训练数据中随机抽取的两个样本,且λ∈[0,1]。因此,mixup通过结合先验知识,即特征向量的线性插值应导致相关标签的线性插值,来扩展训练分布。
代码实现:

2、SpecAugment
论文地址:https://arxiv.org/pdf/1904.08779.pdf
SpecAugment 是一种对输入音频的logmel谱图而不是对原始音频进行操作的增强方法。增强策略包括time wrapping、time masking和frequency masking。
(1)time wrapping:通过tensorflow的sparse_image_warp函数实现。time wrapping给模型性能带来的影响虽然很小,但仍然存在。time wrapping,考虑到任何预算限制,作为这项工作中讨论的最昂贵、影响最小的增强方法,应该是第一个被舍弃的。
(2)Frequency masking:掩蔽[f0,f0+f)的f个连续的mel频率通道,其中f从0到频率掩码参数F的均匀分布中选择,f0从[0,ν-f)中选择 。ν是mel频率通道的数量。
代码实现:
tensorflow
import tensorflow_io as tfio
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
pytorch
import torchaudio.transforms as T
torch.random.manual_seed(4)
spec = get_spectrogram()
masking = T.FrequencyMasking(freq_mask_param=80)
spec = masking(spec)
(3)Time masking:掩蔽[t0,t0+t)的t个连续的时间步,其中t从0到时间掩蔽参数t的均匀分布中选择,t0从[0,τ-t)中选择。
代码实现:
tensorflow
import tensorflow_io as tfio
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
pytorch
import torchaudio.transforms as T
torch.random.manual_seed(4)
spec = get_spectrogram()
masking = T.TimeMasking(time_mask_param=80)
spec = masking(spec)
参考地址:Audio Feature Augmentation — PyTorch Tutorials 1.11.0+cu102 documentation
https://www.tensorflow.org/io/tutorials/audio
下图显示了应用于单个输入的单个增强的示例

版权归原作者 冲冲冲鸭鸭鸭~ 所有, 如有侵权,请联系我们删除。