
文章目录
6.1 间隔与支持向量
从几何角度,对线性可分数据集,支持向量机就是找距离正负样本都最远的超平面,相比于感知机,其解是唯一的,且不偏不倚,泛化性能更好。
给定训练样本集,分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开,支持向量机倾向找到产生分类结果具有鲁棒性,对未见示例的泛化能力最强的划分超平面。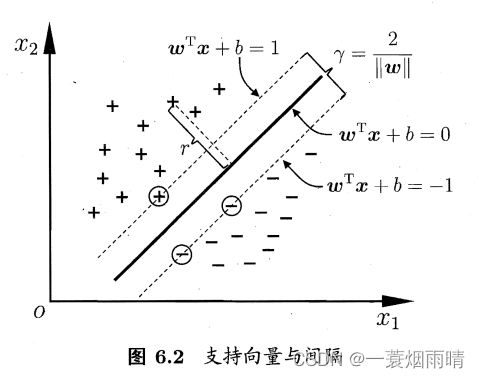
假设超平面能将训练样本正确分类,即
{
w
T
x
i
+
b
⩾
+
1
,
y
i
=
+
1
w
T
x
i
+
b
⩽
−
1
,
y
i
=
−
1
\begin{cases}\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \geqslant+1, & y_{i}=+1 \\ \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \leqslant-1, & y_{i}=-1\end{cases}
{wTxi+b⩾+1,wTxi+b⩽−1,yi=+1yi=−1
距离超平面最近的几个训练样本点使得上式的等号成立,它们被称为“支持向量”,两个异类支持向量到超平面的距离之和为
γ
=
2
∥
w
∥
\gamma=\frac{2}{\|\boldsymbol{w}\|}
γ=∥w∥2
它被称为“间隔”。
支持向量机是要找到具有“最大间隔”的划分超平面,即建立如下基本型:
min
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
T
x
i
+
b
)
⩾
1
,
i
=
1
,
2
,
…
,
m
\begin{aligned} \min _{\boldsymbol{w}, b} & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, m \end{aligned}
w,bmin s.t. 21∥w∥2yi(wTxi+b)⩾1,i=1,2,…,m
此处,有另一种解释得到上式
6.2 对偶问题
注意到本身上式是一个凸优化规划问题,能直接用现成的优化计算包求解,但是我们可以有更高效的方法。
下图来自B站白板推导
原问题等价于对偶问题的充要条件就是满足KKT条件
如何从下式求解
α
i
\alpha_i
αi呢?
max
α
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
\max _{\boldsymbol{\alpha}} \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
s.t.
∑
i
=
1
m
α
i
y
i
=
0
α
i
⩾
0
,
i
=
1
,
2
,
…
,
m
\begin{array}{ll} \text { s.t. } & \sum_{i=1}^{m} \alpha_{i} y_{i}=0 \\ & \alpha_{i} \geqslant 0, \quad i=1,2, \ldots, m \end{array}
s.t. ∑i=1mαiyi=0αi⩾0,i=1,2,…,m
人们通过利用问题本身的特性,提出了很多高效算法,SMO是其中一个著名的代表。
6.3 核函数
在前面的讨论中,我们假设训练样本是线性可分的,然而现实中原始样本空间内也许并不存在一个能正确划分两类样本的超平面。
幸运的是,如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。
但是直接计算
ϕ
(
x
i
)
T
ϕ
(
x
j
)
\phi\left(\boldsymbol{x}_{i}\right)^{\mathrm{T}} \phi\left(\boldsymbol{x}_{j}\right)
ϕ(xi)Tϕ(xj)通常是困难的,为了避开这个障碍,可以设想这样一个函数,即核函数:
κ
(
x
i
,
x
j
)
=
⟨
ϕ
(
x
i
)
,
ϕ
(
x
j
)
⟩
=
ϕ
(
x
i
)
T
ϕ
(
x
j
)
\kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left\langle\phi\left(\boldsymbol{x}_{i}\right), \phi\left(\boldsymbol{x}_{j}\right)\right\rangle=\phi\left(\boldsymbol{x}_{i}\right)^{\mathrm{T}} \phi\left(\boldsymbol{x}_{j}\right)
κ(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩=ϕ(xi)Tϕ(xj)
以下是常用的几个核函数:
6.4 软间隔与正则化
现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分;退一步说,即便恰好找到了某个核函数使训练集在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合所造成的。
缓解该问题的一个方法是允许支持向量机在一些样本上出错。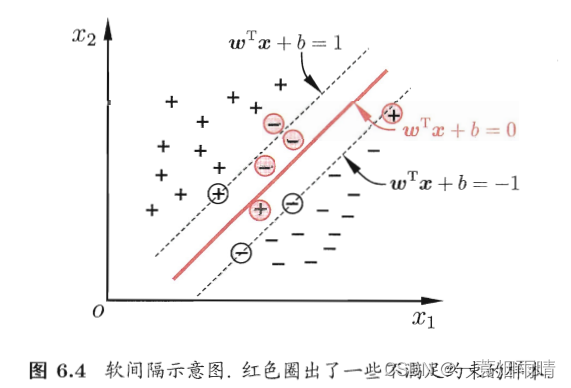
软间隔允许某些样本不满足约束,但在最大化间隔的同时,不满足约束的样本应尽可能少。于是有如下优化目标:
min
w
,
b
1
2
∥
w
∥
2
+
C
∑
i
=
1
m
ℓ
0
/
1
(
y
i
(
w
T
x
i
+
b
)
−
1
)
,
\min _{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2}+C \sum_{i=1}^{m} \ell_{0 / 1}\left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1\right),
w,bmin21∥w∥2+Ci=1∑mℓ0/1(yi(wTxi+b)−1),
其中C>0是一个常数,
ℓ
0
/
1
\ell_{0 / 1}
ℓ0/1是“0/1损失函数”
ℓ
0
/
1
(
z
)
=
{
1
,
if
z
<
0
0
,
otherwise
\ell_{0 / 1}(z)= \begin{cases}1, & \text { if } z<0 \\ 0, & \text { otherwise }\end{cases}
ℓ0/1(z)={1,0, if z<0 otherwise
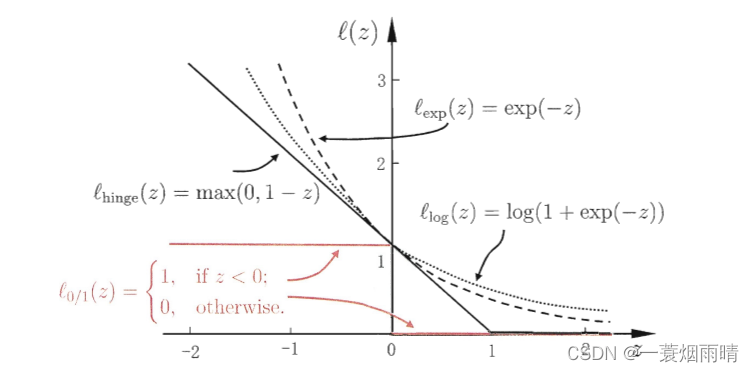
然而
ℓ
0
/
1
\ell_{0 / 1}
ℓ0/1非凸、非连续,数学性质不太好,有其他损失函数一般具有较好的数学性质,如它们通常是凸的连续函数却是
ℓ
0
/
1
\ell_{0 / 1}
ℓ0/1的上界。
6.5 支持向量回归
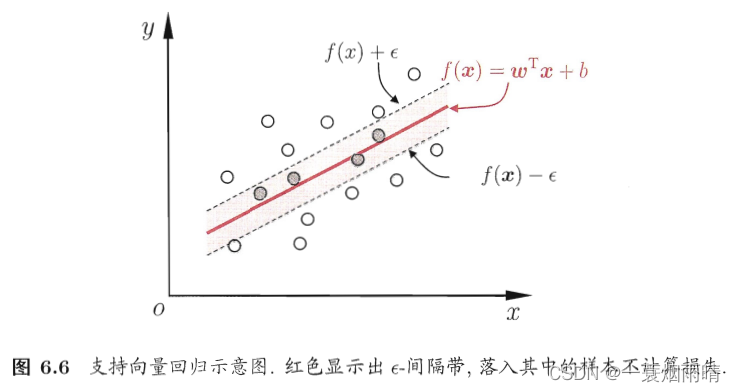
传统回归模型通常直接基于模型输出
f
(
x
)
f(x)
f(x)与真实输出y之间的差别来计算损失,当且仅当f(x)与y完全相同时,损失才为零。与此不同,支持向量回归假设我们能容忍f(x)与y之间最多有一定的偏差。
6.6 核方法
非线性带来高维转换(从模型角度)
对偶表示带来内积(优化角度)
代码实现
来自datawhale
线性SVM
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
data = np.array([[0.1,0.7],[0.3,0.6],[0.4,0.1],[0.5,0.4],[0.8,0.04],[0.42,0.6],[0.9,0.4],[0.6,0.5],[0.7,0.2],[0.7,0.67],[0.27,0.8],[0.5,0.72]])# 建立数据集
label =[1]*6+[0]*6#前六个数据的label为1后六个为0
x_min, x_max = data[:,0].min()-0.2, data[:,0].max()+0.2
y_min, y_max = data[:,1].min()-0.2, data[:,1].max()+0.2
xx, yy = np.meshgrid(np.arange(x_min, x_max,0.002),
np.arange(y_min, y_max,0.002))# meshgrid如何生成网格print(xx)
model_linear = svm.SVC(kernel='linear', C =0.001)# 线性svm
model_linear.fit(data, label)# 训练
Z = model_linear.predict(np.c_[xx.ravel(), yy.ravel()])# 预测
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap = plt.cm.ocean, alpha=0.6)# contour() 是用来绘制等高线的,此次用来显示预测差异
plt.scatter(data[:6,0], data[:6,1], marker='o', color='r', s=100, lw=3)
plt.scatter(data[6:,0], data[6:,1], marker='x', color='k', s=100, lw=3)
plt.title('Linear SVM')
plt.show()

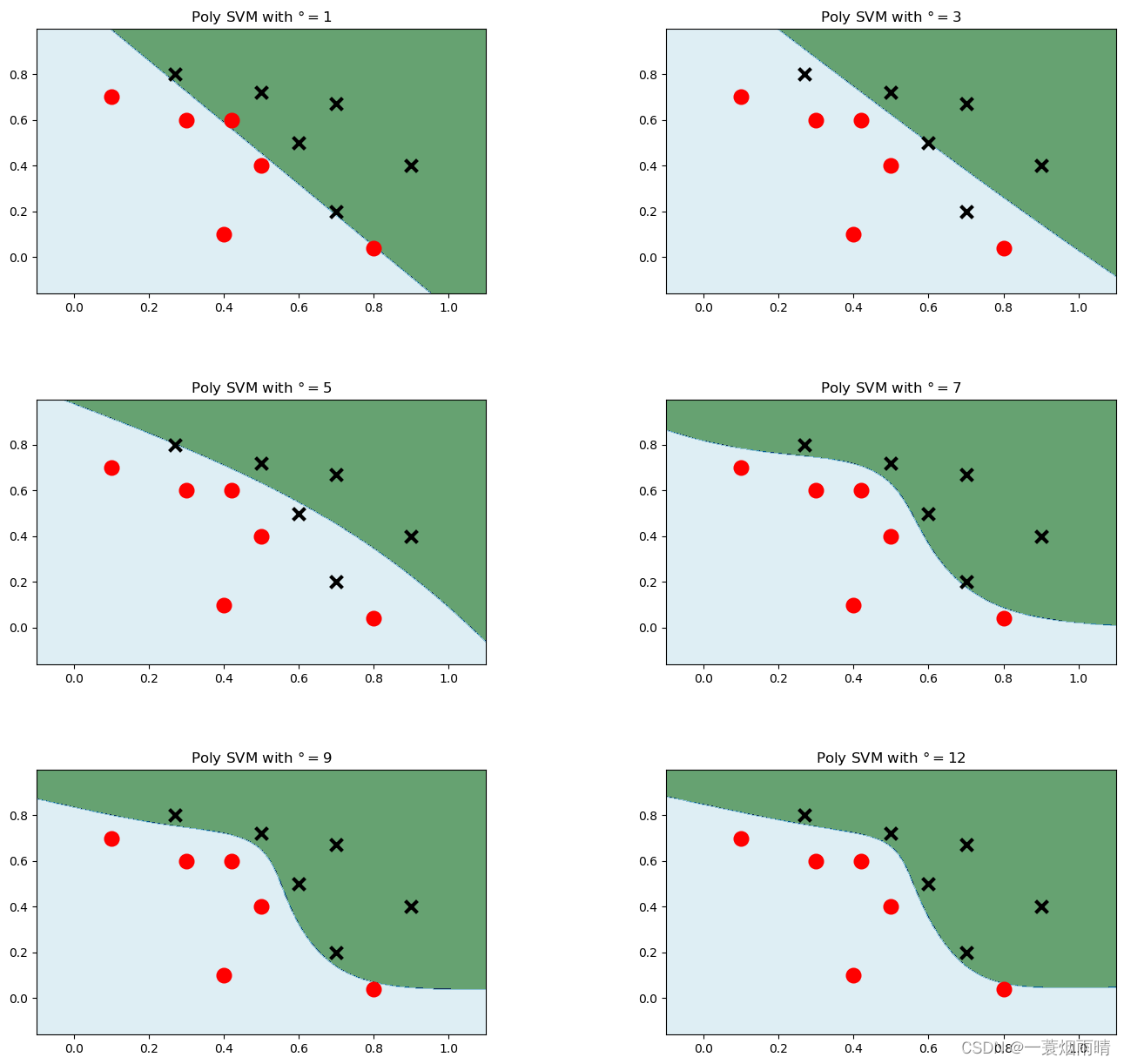
多项式SVM
plt.figure(figsize=(16,15))for i, degree inenumerate([1,3,5,7,9,12]):#多项式次数选择了1,3,5,7,9,12# C: 惩罚系数,gamma: 高斯核的系数
model_poly = svm.SVC(C=0.0001, kernel='poly', degree=degree)# 多项式核
model_poly.fit(data, label)# 训练# ravel - flatten# c_ - vstack# 把后面两个压扁之后变成了x1和x2,然后进行判断,得到结果在压缩成一个矩形
Z = model_poly.predict(np.c_[xx.ravel(), yy.ravel()])#预测
Z = Z.reshape(xx.shape)
plt.subplot(3,2, i +1)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
plt.contourf(xx, yy, Z, cmap=plt.cm.ocean, alpha=0.6)# 画出训练点
plt.scatter(data[:6,0], data[:6,1], marker='o', color='r', s=100, lw=3)
plt.scatter(data[6:,0], data[6:,1], marker='x', color='k', s=100, lw=3)
plt.title('Poly SVM with $\degree=$'+str(degree))
plt.show()
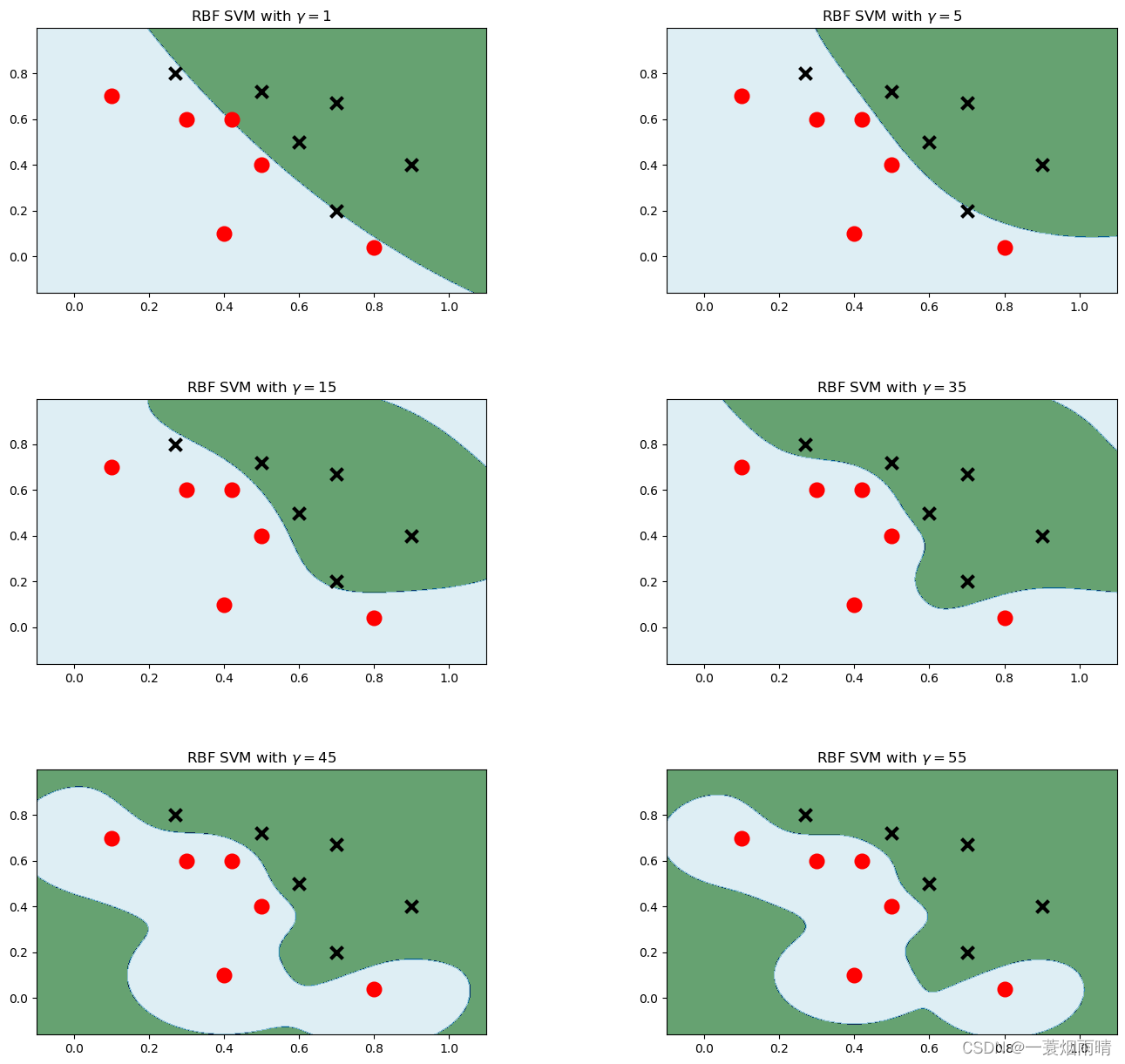
高斯核SVM
plt.figure(figsize=(16,15))for i, gamma inenumerate([1,5,15,35,45,55]):# C: 惩罚系数,gamma: 高斯核的系数
model_rbf = svm.SVC(kernel='rbf', gamma=gamma, C=0.0001).fit(data, label)# ravel - flatten# c_ - vstack# 把后面两个压扁之后变成了x1和x2,然后进行判断,得到结果在压缩成一个矩形
Z = model_rbf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.subplot(3,2, i +1)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
plt.contourf(xx, yy, Z, cmap=plt.cm.ocean, alpha=0.6)# 画出训练点
plt.scatter(data[:6,0], data[:6,1], marker='o', color='r', s=100, lw=3)
plt.scatter(data[6:,0], data[6:,1], marker='x', color='k', s=100, lw=3)
plt.title('RBF SVM with $\gamma=$'+str(gamma))
plt.show()
版权归原作者 一蓑烟雨晴 所有, 如有侵权,请联系我们删除。