
一般情况下我们在做数据预处理时都是使用StandardScaler来特征的标准化,如果你的数据中包含异常值,那么效果可能不好。
这里介绍的方法叫Robust Scaling,正如它的名字一样能够获得更健壮的特征缩放结果。与StandardScaler缩放不同,异常值根本不包括在Robust Scaling计算中。因此在包含异常值的数据集中,更有可能缩放到更接近正态分布。
StandardScaler会确保每个特征的平均值为0,方差为1。而RobustScaler使用中位数和四分位数(四分之一),确保每个特征的统计属性都位于同一范围。
公式如下:
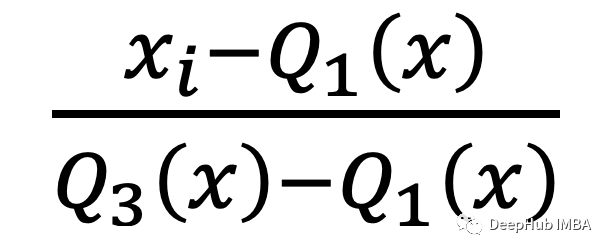
我们使用一些数据看看他的结果,首先创建测试数据
import numpy as np
import matplotlib.pyplot as plt
nb_samples = 200
mu = [1.0, 1.0]
covm = [[2.0, 0.0], [0.0, 0.8]]
X = np.random.multivariate_normal(mean=mu, cov=covm, size=nb_samples)
然后使用三个常用的缩放方法对数据进行预处理:
from sklearn.preprocessing import StandardScaler, RobustScaler, MinMaxScaler
ss = StandardScaler()
X_ss = ss.fit_transform(X)
rs = RobustScaler(quantile_range=(10, 90))
X_rs = rs.fit_transform(X)
mms = MinMaxScaler(feature_range=(-1, 1))
X_mms = mms.fit_transform(X)
可视化:
fig, ax = plt.subplots(2,2, sharex=True, sharey=True, dpi=1000)
ax[0][0].scatter(X[:,0], X[:,1], c='gray', alpha = .8)
ax[0][1].scatter(X_ss[:,0], X_ss[:,1], c='gray', alpha = .8)
ax[1][0].scatter(X_rs[:,0], X_rs[:,1], c='gray', alpha = .8)
ax[1][1].scatter(X_mms[:,0], X_mms[:,1], c='gray', alpha = .8)
ax[0][0].set_title('Original dataset')
ax[0][1].set_title('Standard Scaling')
ax[1][0].set_title('Robust Scaling')
ax[1][1].set_title('Min-Max Scaling')
plt.tight_layout()
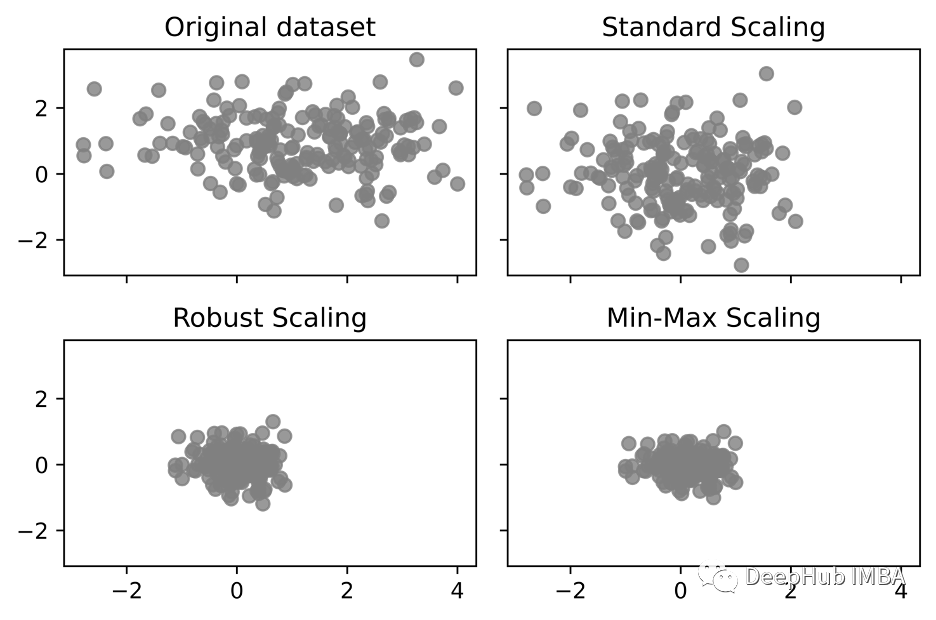
为什么这个方法不会受异常值的影响?
如果数据中存在很大的异常值,可能会影响特征的平均值和方差进而影响标准化结果。而RobustScaler使用中位数和四分位数间距进行缩放,这样可以缩小异常值的影响.
最后我们再看一下这个方法的参数
quantile_range : tuple (q_min, q_max), 0.0 < q_min < q_max < 100.0, default=(25.0, 75.0)
quantile_range用于计算scale_的分位数范围。默认情况下,它等于IQR,即q_min是第一个分位数,q_max是第三个分位数,也就是我们上面公式中的Q1和Q3.
作者:Simsangcheol