
Deephub
更多文章请关注公众号:Deephub-IMBA

Numpy中数组和矩阵操作的数学函数
Numpy 是一个强大的 Python 计算库。它提供了广泛的数学函数,可以对数组和矩阵执行各种操作。本文中将整理一些基本和常用的数学操作。
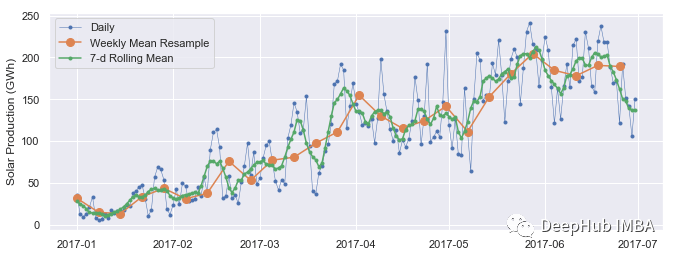
3个用于时间序列数据整理的Pandas函数
本文将演示 3 个处理时间序列数据最常用的 pandas 操作
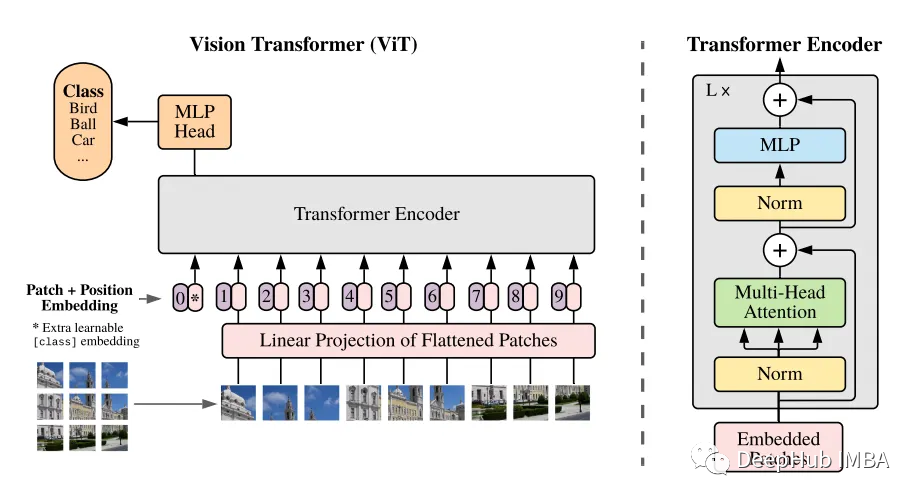
使用JAX实现完整的Vision Transformer
本文将展示如何使用JAX/Flax实现Vision Transformer (ViT),以及如何使用JAX/Flax训练ViT。
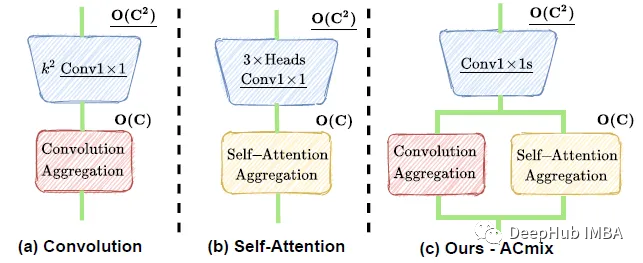
论文推荐:ACMix整合self-Attention和Convolution (ACMix)的优点的混合模型
混合模型ACmix将自注意与卷积的整合,同时具有自注意和卷积的优点。这是清华大学、华为和北京人工智能研究院共同发布在2022年CVPR中的论文
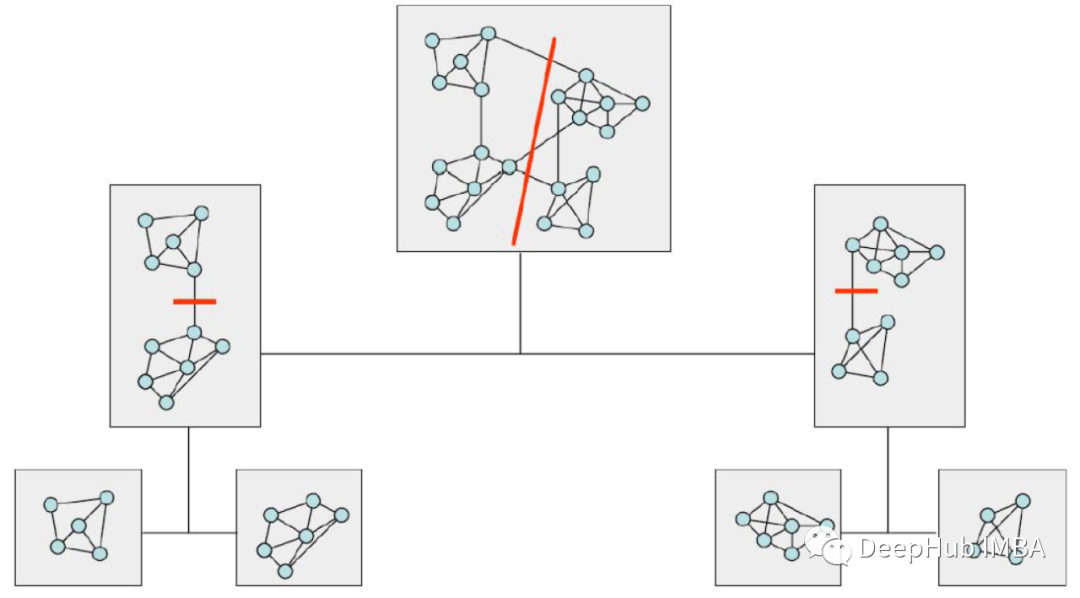
使用谱聚类(spectral clustering)进行特征选择
在本文中,我们将介绍一种从相关特征的高维数据中选择或提取特征的有用方法。
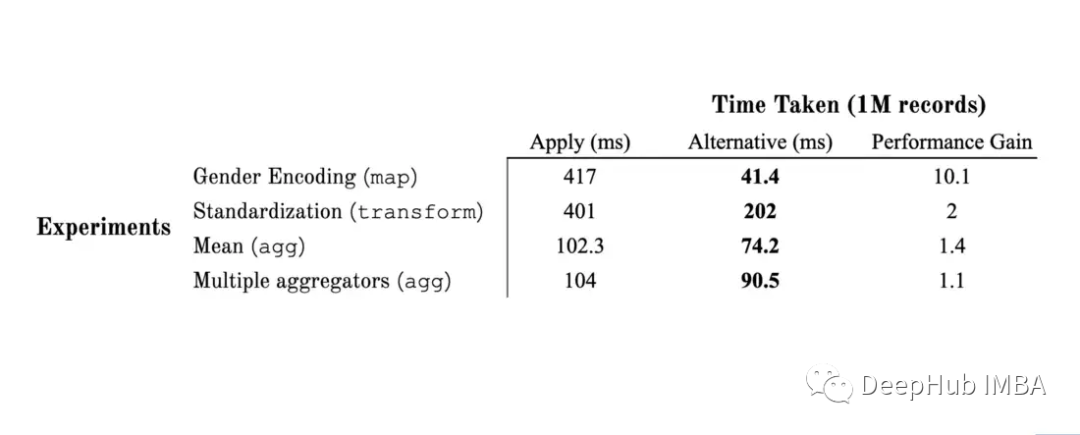
Pandas的apply, map, transform介绍和性能测试
在这篇文章中,我们将通过一些示例讨论apply、agg、map和transform的预期用途。
2023 年 1 月的5篇深度学习论文推荐
本文整理了 2023 年 1 月5 篇著名的 AI 论文,涵盖了计算机视觉、自然语言处理等方面的新研究。

在 PyTorch 中使用梯度检查点在GPU 上训练更大的模型
本文将介绍解梯度检查点(Gradient Checkpointing),这是一种可以让你以增加训练时间为代价在 GPU 中训练大模型的技术。 我们将在 PyTorch 中实现它并训练分类器模型。
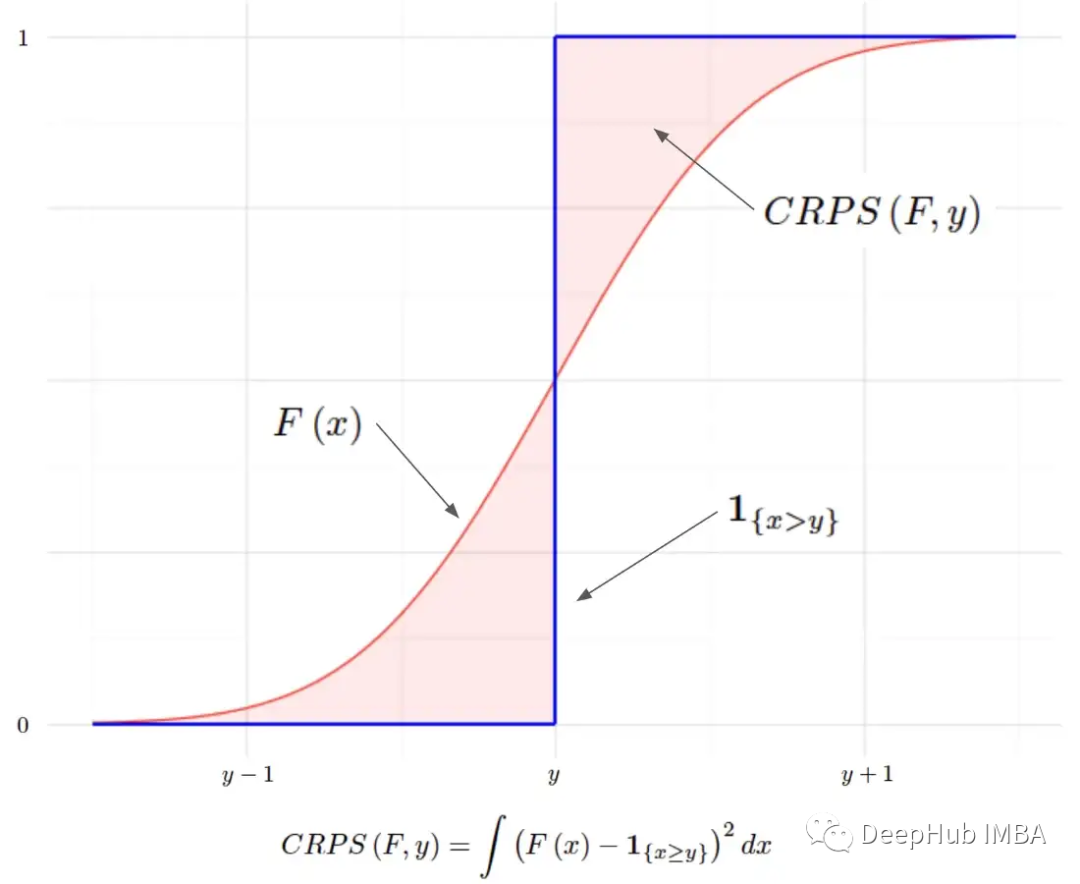
CRPS:贝叶斯机器学习模型的评分函数
连续分级概率评分(Continuous Ranked Probability Score, CRPS)或“连续概率排位分数”是一个函数或统计量,可以将分布预测与真实值进行比较。
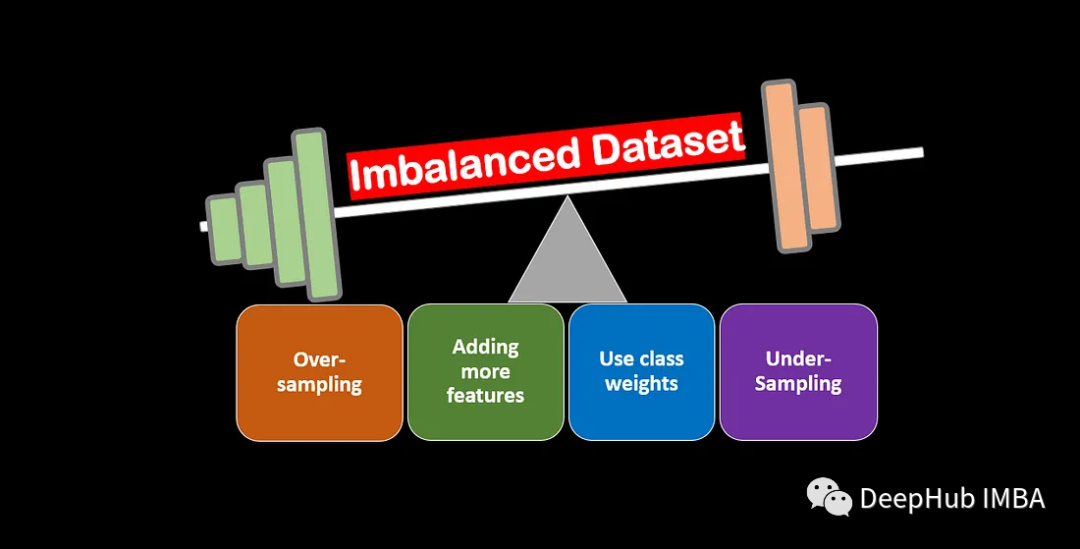
不平衡数据集的建模的技巧和策略
在本文中,我们将讨论处理不平衡数据集和提高机器学习模型性能的各种技巧和策略
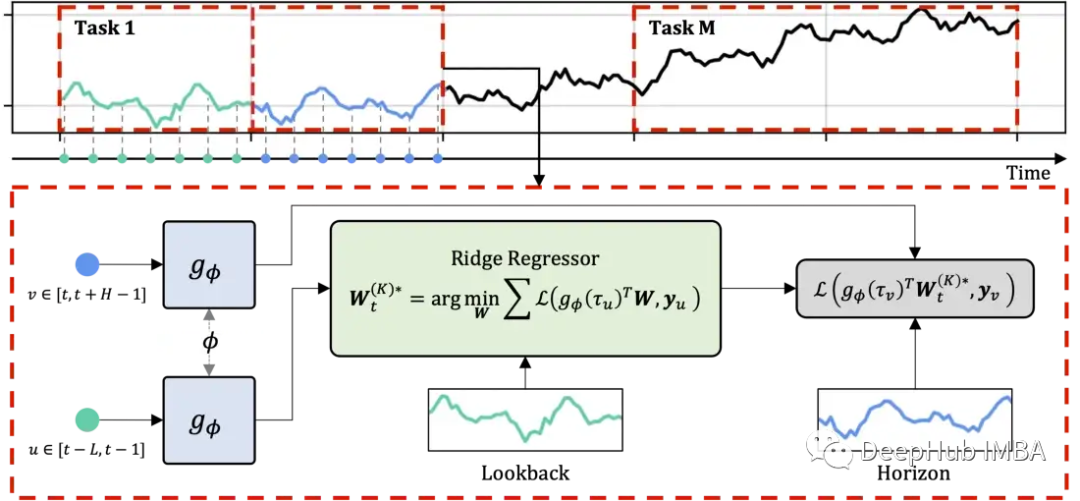
DeepTime:时间序列预测中的元学习模型
DeepTime,是一个结合使用元学习的深度时间指数模型。通过使用元学习公式来预测未来
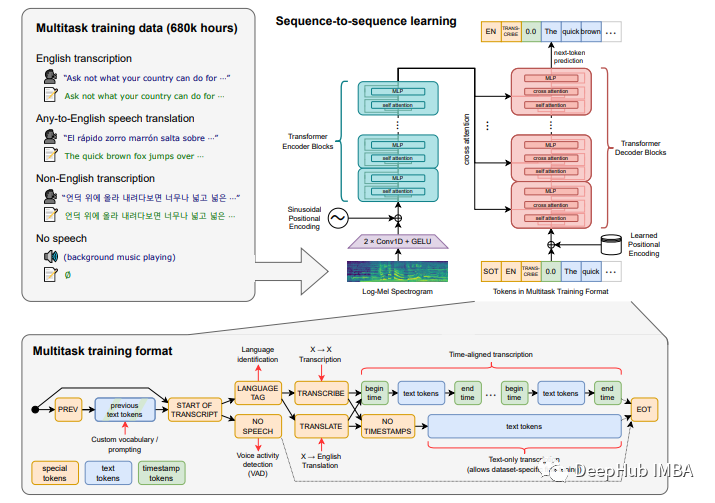
使用OpenAI的Whisper 模型进行语音识别
本文将解释用于训练的数据集的种类以及模型的训练方法,以及如何使用Whisper
监控Python 内存使用情况和代码执行时间
我的代码的哪些部分运行时间最长、内存最多?我怎样才能找到需要改进的地方?”在本文中总结了一些方法来监控 Python 代码的时间和内存使用情况。

使用CNN进行2D路径规划
本文将CNN应用于解决简单的二维路径规划问题。主要使用Python, PyTorch, NumPy和OpenCV。

这20个Pandas函数可以完成80%的数据科学工作
Pandas 是数据科学社区中使用最广泛的库之一,本文将提供最常用的 Pandas 函数以及如何实际使用它们的样例。

使用Stable-Diffusion生成视频的完整教程
本文是关于如何使用cuda和Stable-Diffusion生成视频的完整指南,将使用cuda来加速视频生成,并且可以使用Kaggle的TESLA GPU来免费执行我们的模型。
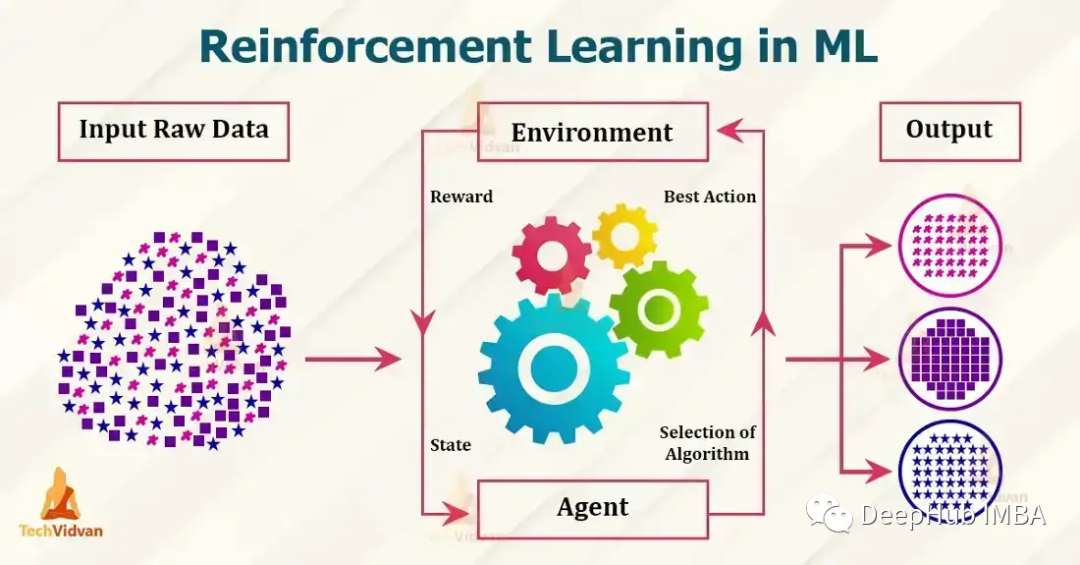
7个流行的强化学习算法及代码实现
目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。 这些算法已被用于在游戏、机器人和决策制定等各种应用中,并且这些流行的算法还在不断发展和改进,本文我们将对其做一个简单的介绍。
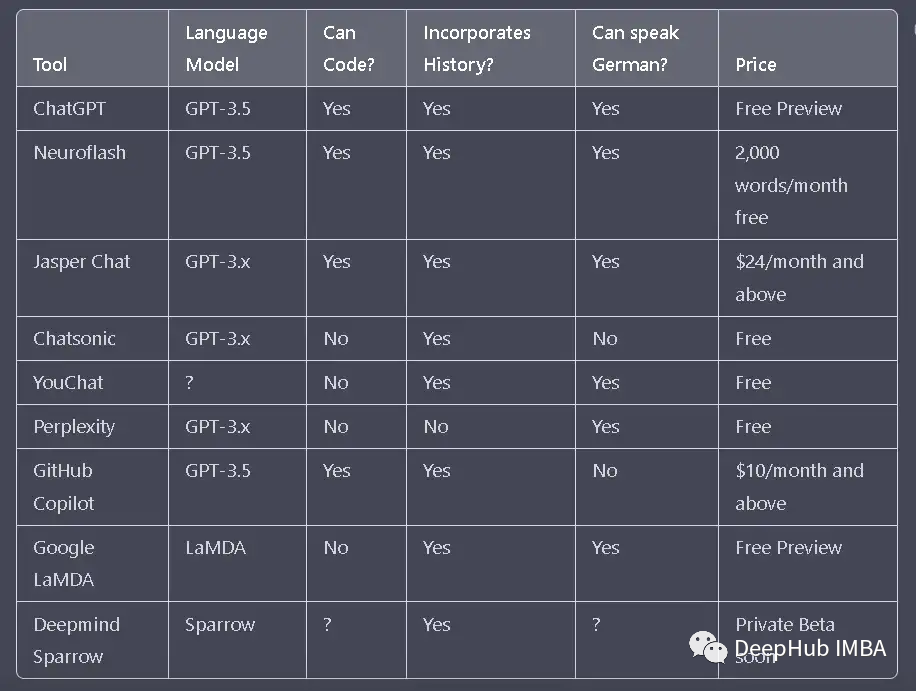
2023 年8个ChatGPT 的替代品
OpenAI 于 2022 年 11 月下旬推出的 ChatGPT 在网络世界引起了不小的轰动。其实还有许多其他的机器人在本文中,我将整理8 个 ChatGPT 替代方案。
8种时间序列分类方法总结
对时间序列进行分类是应用机器和深度学习模型的常见任务之一。本篇文章将涵盖 8 种类型的时间序列分类方法。这包括从简单的基于距离或间隔的方法到使用深度神经网络的方法。这篇文章旨在作为所有时间序列分类算法的参考文章。

深度学习中高斯噪声:为什么以及如何使用
在数学上,高斯噪声是一种通过向输入数据添加均值为零和标准差(σ)的正态分布随机值而产生的噪声。