
监督学习是训练机器学习模型的传统方法,它在训练时每一个观察到的数据都需要有标注好的标签。如果我们有一种训练机器学习模型的方法不需要收集标签,会怎么样?如果我们从收集的相同数据中提取标签呢?这种类型的学习算法被称为自监督学习。这种方法在自然语言处理中工作得很好。一个例子是BERT¹,谷歌自2019年以来一直在其搜索引擎中使用BERT¹。不幸的是,对于计算机视觉来说,情况并非如此。
Facebook AI的kaiming大神等人提出了一种带掩码自编码器(MAE)²,它基于(ViT)³架构。他们的方法在ImageNet上的表现要好于从零开始训练的VIT。在本文中,我们将深入研究他们的方法,并了解如何在代码中实现它。
带掩码自编码器(MAE)
对输入图像的patches进行随机掩码,然后重建缺失的像素。MAE基于两个核心设计。首先,开发了一个非对称的编码器-解码器架构,其中编码器仅对可见的patches子集(没有掩码的tokens)进行操作,同时还有一个轻量级的解码器,可以从潜在表示和掩码tokens重建原始图像。其次,发现对输入图像进行高比例的掩码,例如75%,会产生有意义的自监督任务。将这两种设计结合起来,能够高效地训练大型模型:加快模型训练速度(3倍甚至更多)并提高精度。
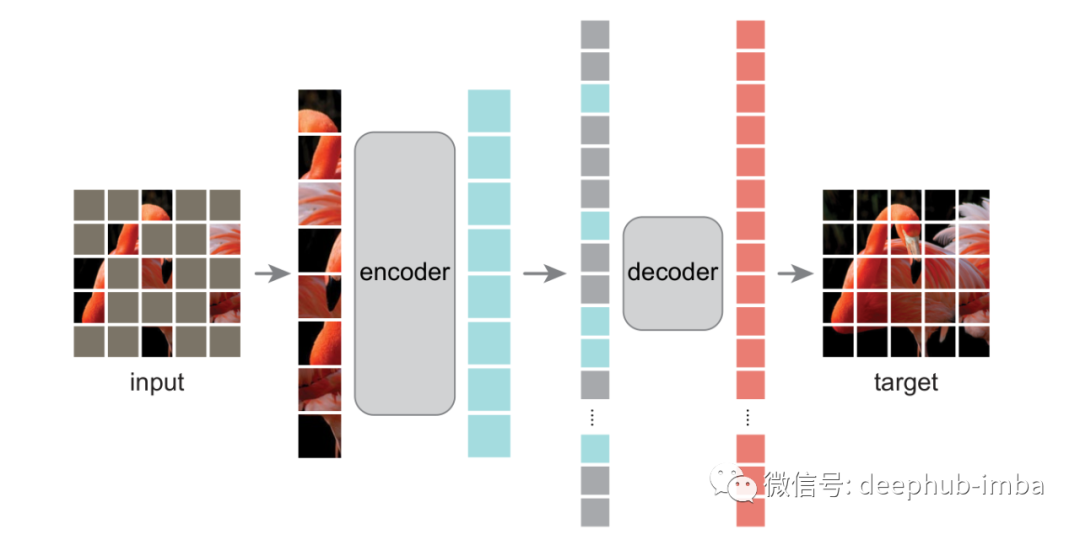
此阶段称为预训练,因为 MAE 模型稍后将用于下游任务,例如图像分类。模型在pretext上的表现在自监督中并不重要, 这些任务的重点是让模型学习一个预期包含良好语义的中间表示。在预训练阶段之后,解码器将被多层感知器 (MLP) 头或线性层取代,作为分类器输出对下游任务的预测。
模型架构
编码器
编码器是 ViT。它接受张量形状为 (batch_size, RGB_channels, height, width) 的图像。通过执行线性投影为每个Patch获得嵌入, 这是通过 2D 卷积层来完成。然后张量在最后一个维度被展平(压扁),变成 (batch_size, encoder_embed_dim, num_visible_patches),并 转置为形状(batch_size、num_visible_patches、encoder_embed_dim)的张量。
class PatchEmbed(nn.Module):
""" Image to Patch Embedding """
def __init__(self, img_size=(224, 224), patch_size=(16, 16), in_chans=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.patch_shape = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x, **kwargs):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
正如原始 Transformer 论文中提到的,位置编码添加了有关每个Patch位置的信息。作者使用“sine-cosine”版本而不是可学习的位置嵌入。下面的这个实现是一维版本。
def get_sinusoid_encoding_table(n_position, d_hid):
def get_position_angle_vec(position):
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
与 Transformer 类似,每个块由norm层、多头注意力模块和前馈层组成。中间输出形状是(batch_size、num_visible_patches、encoder_embed_dim)。多头注意力模块的代码如下:
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., attn_head_dim=None):
super().__init__()
self.num_heads = num_heads
head_dim = attn_head_dim if attn_head_dim is not None else dim // num_heads
all_head_dim = head_dim * self.num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, all_head_dim * 3, bias=False)
self.q_bias = nn.Parameter(torch.zeros(all_head_dim)) if qkv_bias else None
self.v_bias = nn.Parameter(torch.zeros(all_head_dim)) if qkv_bias else None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(all_head_dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias)) if self.q_bias is not None else None
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1)).softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj_drop(self.proj(x))
return x
Transformer 模块的代码如下:
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, attn_head_dim=None):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, attn_head_dim=attn_head_dim)
self.norm2 = norm_layer(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, int(dim * mlp_ratio)), act_layer(), nn.Linear(int(dim * mlp_ratio), dim), nn.Dropout(attn_drop)
)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
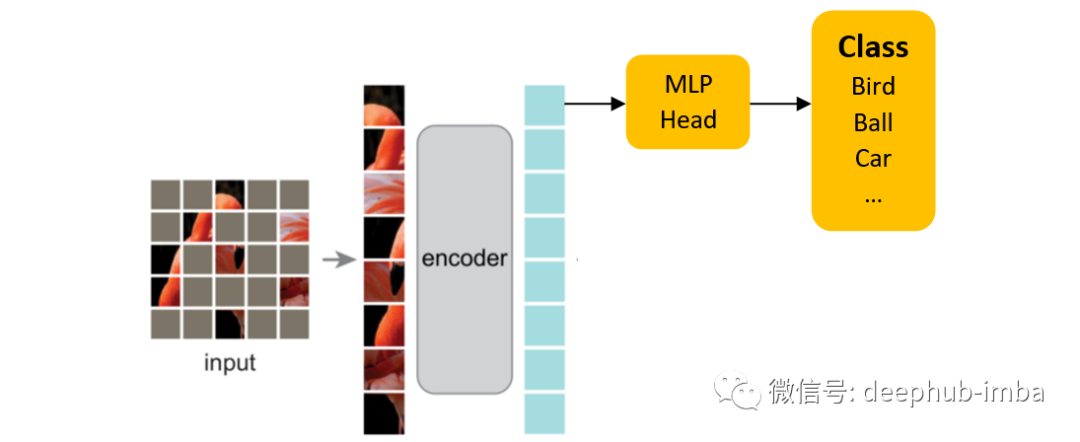
这部分仅用于下游任务的微调。论文的模型遵循 ViT 架构,该架构具有用于分类的类令牌(patch)。因此,他们添加了一个虚拟令牌,但是论文中也说到他们的方法在没有它的情况下也可以运行良好,因为对其他令牌执行了平均池化操作。在这里也包含了实现的平均池化版本。之后,添加一个线性层作为分类器。最终的张量形状是 (batch_size, num_classes)。
综上所述,编码器实现如下:
class Encoder(nn.Module)
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=nn.LayerNorm, num_classes=0, **block_kwargs):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
# Patch embedding
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
# Positional encoding
self.pos_embed = get_sinusoid_encoding_table(num_patches, embed_dim)
# Transformer blocks
self.blocks = nn.ModuleList([Block(**block_kwargs) for i in range(depth)]) # various arguments are not shown here for brevity purposes
self.norm = norm_layer(embed_dim)
# Classifier (for fine-tuning only)
self.fc_norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x, mask):
x = self.patch_embed(x)
x = x + self.pos_embed.type_as(x).to(x.device).clone().detach()
B, _, C = x.shape
if mask is not None: # for pretraining only
x = x[~mask].reshape(B, -1, C) # ~mask means visible
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
if self.num_classes > 0: # for fine-tuning only
x = self.fc_norm(x.mean(1)) # average pooling
x = self.head(x)
return x
解码器
与编码器类似,解码器由一系列transformer 块组成。在解码器的末端,有一个由norm层和前馈层组成的分类器。输入张量的形状为 batch_size, num_patches,decoder_embed_dim) 而最终输出张量的形状为 (batch_size, num_patches, 3 * patch_size ** 2)。
class Decoder(nn.Module):
def __init__(self, patch_size=16, embed_dim=768, norm_layer=nn.LayerNorm, num_classes=768, **block_kwargs):
super().__init__()
self.num_classes = num_classes
assert num_classes == 3 * patch_size ** 2
self.num_features = self.embed_dim = embed_dim
self.patch_size = patch_size
self.blocks = nn.ModuleList([Block(**block_kwargs) for i in range(depth)]) # various arguments are not shown here for brevity purposes
self.norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x, return_token_num):
for blk in self.blocks:
x = blk(x)
if return_token_num > 0:
x = self.head(self.norm(x[:, -return_token_num:])) # only return the mask tokens predict pixels
else:
x = self.head(self.norm(x))
return x
把所有东西放在一起——MAE架构
MAE 用于对掩码图像进行预训练。首先,屏蔽的输入被发送到编码器。然后,它们被传递到前馈层以更改嵌入维度以匹配解码器。在传递给解码器之前,被掩码的Patch被输入进去。位置编码再次应用于完整的图像块集,包括可见的和被掩码遮盖的。
在论文中,作者对包含所有Patch的列表进行了打乱,以便正确插入Patch的掩码。这部分在本篇文章中没有完成,因为在 PyTorch 上实现并不简单。所以这里使用的是位置编码在被添加到Patch之前被相应地打乱的做法。
class MAE(nn.Module):
def __init__(self, ...): # various arguments are not shown here for brevity purposes
super().__init__()
self.encoder = Encoder(img_size, patch_size, in_chans, embed_dim, norm_layer, num_classes=0, **block_kwargs)
self.decoder = Decoder(patch_size, embed_dim, norm_layer, num_classes, **block_kwargs)
self.encoder_to_decoder = nn.Linear(encoder_embed_dim, decoder_embed_dim, bias=False)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.pos_embed = get_sinusoid_encoding_table(self.encoder.patch_embed.num_patches, decoder_embed_dim)
def forward(self, x, mask):
x_vis = self.encoder(x, mask)
x_vis = self.encoder_to_decoder(x_vis)
B, N, C = x_vis.shape
expand_pos_embed = self.pos_embed.expand(B, -1, -1).type_as(x).to(x.device).clone().detach()
pos_emd_vis = expand_pos_embed[~mask].reshape(B, -1, C)
pos_emd_mask = expand_pos_embed[mask].reshape(B, -1, C)
x_full = torch.cat([x_vis + pos_emd_vis, self.mask_token + pos_emd_mask], dim=1)
x = self.decoder(x_full, pos_emd_mask.shape[1]) # [B, N_mask, 3 * 16 * 16]
return x
训练过程
对于自监督预训练,论文发现简单的逐像素平均绝对损失作为目标函数效果很好。并且他们使用的数据集是 ImageNet-1K 训练集。
在下游的微调阶段,解码器被移除,编码器在相同的数据集上进行训练。数据与预训练略有不同,因为编码器现在使用完整的图像块集(没有屏蔽)。因此,现在的Patch数量与预训练阶段不同。
如果您你知道用于预训练的模型是否仍然可以用于微调,答案是肯定的。 编码器主要由注意力模块、norm层和前馈层组成。要检查Patch数量(索引 1)的变化是否影响前向传递,我们需要查看每一层的参数张量的形状。
- norm层中的参数的形状为(batch, 1, encoder_embed_dim)。它可以在前向传播期间沿着补丁维度(索引 1)进行广播,因此它不依赖于补丁维度的大小。
- 前馈层有一个形状为(in_channels, out_channels)的权重矩阵和一个形状为(out_channels,)的偏置矩阵,两者都不依赖于patch的数量。
- 注意力模块本质上执行一系列线性投影。因此,出于同样的原因,patch的数量也不会影响参数张量的形状。
由于并行处理允许将数据分批输入,所以批处理中的Patch数量是需要保持一致的。
结果
让我们看看原始论文中报道的预训练阶段的重建图像。看起来MAE在重建图像方面做得很好,即使80%的像素被遮蔽了。

ImageNet验证图像的示例结果。从左到右:遮蔽图像、重建图像、真实图像。掩蔽率为80%。
MAE 在微调的下游任务上也表现良好,例如 ImageNet-1K 数据集上的图像分类。与监督方式相比,在使用 MAE 预训练进行训练时比使用的基线 ViT-Large 实际上表现更好。
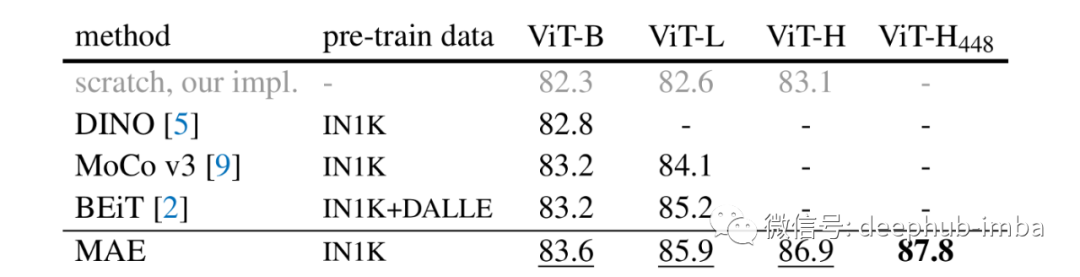
论文中还包括对下游任务和各种消融研究的迁移学习实验的基准结果。有兴趣的可以再看看原论文。
讨论
如果您熟悉 BERT,您可能会注意到 BERT 和 MAE 的方法之间的相似之处。在 BERT 的预训练中,我们遮蔽了一部分文本,模型的任务是预测它们。此外,由于我们现在使用的是基于 Transformer 的架构,因此说这种方法在视觉上与 BERT 等效也不是不合适的。
但是论文中说这种方法早于 BERT。例如,过去对图像自监督的尝试使用堆叠去噪自编码器和图像修复作为pretext task。MAE 本身也使用自动编码器作为模型和类似于图像修复的pretext task。
如果是这样的话,是什么让 MAE 工作比以前模型好呢?我认为关键在于 ViT 架构。在他们的论文中,作者提到卷积神经网络在将掩码标记和位置嵌入等“指标”集成到其中时存在问题,而 ViT 解决了这种架构差距。如果是这样,那么我们将看到在自然语言处理中开发的另一个想法在计算机视觉中成功实现。之前是attention机制,然后Transformer的概念以Vision Transformers的形式借用到计算机视觉中,现在是整个BERT预训练过程。
结论
我对未来自监督的视觉必须提供的东西感到兴奋。鉴于 BERT 在自然语言处理方面的成功,像 MAE 这样的掩码建模方法将有益于计算机视觉。图像数据很容易获得,但标记它们可能很耗时。通过这种方法,人们可以通过管理比 ImageNet 大得多的数据集来扩展预训练过程,而无需担心标记。潜力是无限的。我们是否会见证计算机视觉的另一次复兴,只有时间才能证明。
引用
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pretraining of deep bidirectional transformers for language understanding. In NAACL, 2019.
- Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. arXiv:2111.06377, 2021.
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
作者:Stephen Lau