
我们都讨厌对文章进行冗长而毫无意义的介绍所以我就直奔主题了。2021年还有10天就过去了, 以下是我认为 2021 年最有趣、最有前途的深度学习论文。
本篇文章的目的是简单地解释它们,并结合非常简单/复杂的冗长文字,这样可以让本文对初学者和有知识的人同时都有一定的帮助。
说明:本文的主题的选择是个人的并且非常有偏见,它们将涵盖更多的计算机视觉主题,而NLP,GANs会比较少,后面我们还会梳理更多论文的推荐文章。
CLIP
https://arxiv.org/pdf/2103.00020.pdf
视觉+语言的多模态学习变得流行的原因就是这篇 OpenAI 论文,它可以更轻松地扩展图像识别任务,因为它不需要耗时的手动标记。它可以从原始文本中学习而不需要手动确定标签,并且在几个著名的数据集中获得了最先进的结果。
这是一个新的学习概念吗?不是,但它是迄今为止最有“野心的”的。OpenAI收集了一个包含 4 亿个图像+文本对的数据集来训练这个模型:对于文本编码使用修改后的 Transformer 架构,对于图像编码使用 ResNet-50、ResNet-101、EfficientNet 和 Vision Transformers(均已修改)。通过对比测试表现最好的是 Vision Transformer ViT-L/14。
它是如何工作的?理论非常的简单:对比学习(Contrastive Learning),一种众所周知的zeroshot和自监督学习技术。给定一对带有文本描述的图像,将它们的特征靠的近一些。如果给定一对文本描述错误的图像,将它们的特征拉远。这样在用句子查询图像时,越接近的就是“更正确”的。
带有 N 个文本描述的 N 个图像分别使用图像和文本编码器进行编码,以便将它们映射到较低维的特征空间。接下来使用另一个映射,从这些特征空间到混合特征空间的简单线性投影映射称为多模态嵌入空间,通过余弦相似度(越接近越相似)使用正+负的对比学习对它们进行比较。
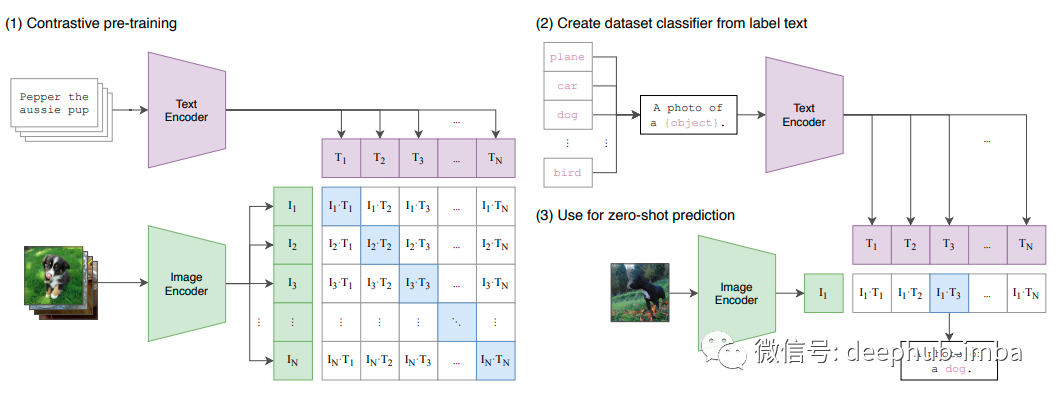
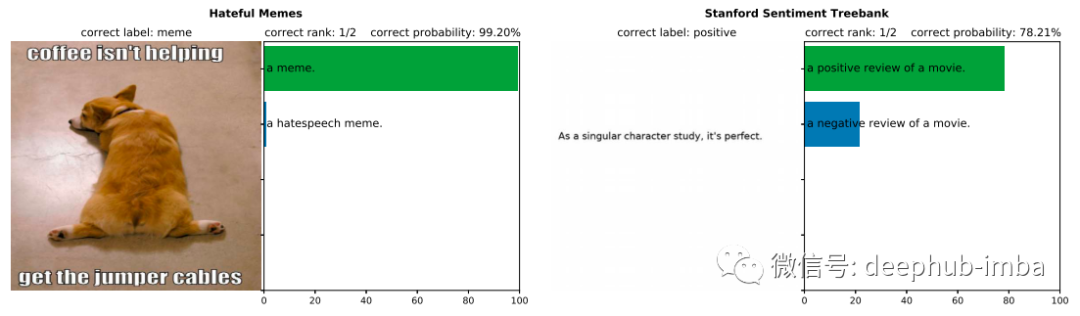
CLIP 能够解决多个文本表示同一图像的问题(即多义性),并且在一些最著名的数据集(如 ImageNet、CIFAR 和 Pascal VOC)上的表现优于最先进的模型。此外由于它使用对比学习所以它是一个zeroshot的学习器,可以比以前的模型更好地泛化到未出现的类别。
扩散模型(Diffusion Models)
我讨厌 GAN的主要原因是它学习非常不稳定,需要花费大量时间进行微调,尤其是英伟达在 GitHub 中实现的 StyleGAN 。如果你也跟我的想法一样,那么GANs不再是图像生成和翻译的最先进的技术,这个你会相信吗?替换掉GANs的是 VQ-VAE 吗?基于流的生成模型Generative flows?都不是。

OpenAI 的去噪扩散模型示例 https://arxiv.org/pdf/2105.05233.pdf
我们可以拍摄一只可爱的狗的图像并为其添加一些噪音,我们仍然可以完美地看到这只狗,所以让我们添加更多,更多,更多的噪声,直到初始狗图像无法识别并且我们看到的也只是随机的噪声。如果一个艺术家看到了一步一步添加噪音的所有过程,那么这个艺术家将能够在每个时间步还原该过程再次恢复最初的狗吗?
在给定数据分布后我们可以定义一个前向马尔可夫扩散过程,该过程在时间 t 添加高斯噪声,直到 t 足够大以至于图像几乎是各向同性的高斯分布,因此我们可以在神经网络的帮助下逐步反转该过程并使得初始数据的分布近似(https://arxiv.org/pdf/2102.09672.pdf)。在每个时间步预测的图像噪声都会减少,在 OpenAI 的 DDM 的情况下,使用具有全局注意力的 UNet 架构和嵌入到每个残差块中的时间步长的投影。
高质量的图像生成很酷,但是他的输出可以调节吗?谷歌的SR3模型通过学习将标准的正态分布转换为经验数据分布,将分辨率非常低的图像转换为清晰的高清图像。该过程的思想与上面解释的类似,但在去噪过程中也考虑到初始的低分辨率图像作为一个通道与当前的时间步长噪声图像合并。该过程进行了 2000 次并且还使用了进行一些奇特修改的UNet 架构。

谷歌在这方面的最新工作:Palette。它不仅在多个图像到图像的任务上获得了最先进的结果,而且不需要特定于任务的超参数调整、架构定制或辅助损失(想想GAN,你不觉得亏心吗)。与之前的工作相比,主要的变化是对 UNet 架构进行了更多的修改,并且没有对分类进行调节(只有图像调节)。

各种Mixers
CV人员和NLP 人员相爱相杀,就像他们常说的一句话:该死的 NLP!他们毁了 NeurIPS!
具有自注意力的 Transformer 在 NLP 领域中发展和壮大并在每项语言任务上都表现得非常出色可以轻松地扩展到大型数据集,但是当有人提出将这个概念引入计算机视觉的想法时平静被打破了。我们都说“不可能进行逐像素注意力!”、“它行不通!”、“它太占用内存了!”直到一个在 16x16 的patch上执行注意力并超过几个图像分类 SOTA的模型”。“Noam Chomsky是对的……智能来自语言……”,自那以后每篇 CV 论文都使用了一些自注意力机制,从自我监督到图像生成(甚至去噪!我从没想过去噪竟然也沦陷了……)。
但后来“MLP-Mixers……”来了。对于NLP的“憎恨者”来说,他们的“救星”竟然是另外一个更不被期待的个体:感知机。因为在CV中没有人会觉得感知机权重的重要性有这么大,但是这个结果对于CV的从业人员来说这一切都说得通了,Vision Transformers 的性能完全来自Patch!仅使用多层感知机和一些 per-patch 线性嵌入、混合层、全局平均池化……等等就可以与 Vision Transformers 竞争(虽然尚未超越),这的确是出色结果。
MLP-Mixers 不依赖于输入数据,更容易训练并且不需要位置编码(因为技术上使它们对排列敏感)。
CV的人很满意(至少面子上保住了), MLP-Mixers 几乎很好但它缺少一些东西……唯一可以证明计算机视觉的东西:卷积!因此,ConvMixers 诞生了。虽然它仍在双盲审查中,但是仅使用标准卷积就已经胜过 ResNets、Vision Transformers 和 MLP-Mixers,还是非常值得我们期待的。
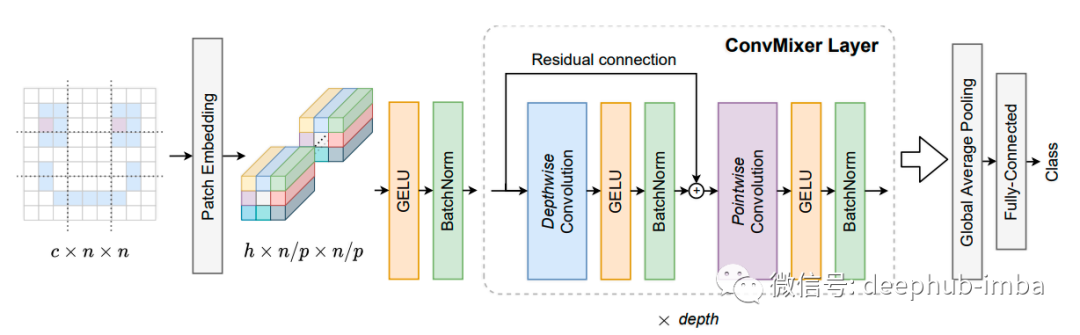
该体系结构模拟了MLP-Mixers的思想,即Vision Transformer的实际性能来自基于Patches的表示,而不是Transformer体系结构本身。ConvMixers在Patches上运行,在所有层中保持分辨率和大小所以也不会出现瓶颈层,采用通道方式进行混合并且整个架构非常简单。这使得拥有普通深度学习pc的人们可以再次使用SOTA技术,这才是科技的力量!
不使用对比对的自监督学习
https://arxiv.org/pdf/2102.06810.pdf
在上面的 CLIP 部分,我们讨论了对比学习以及它如何通过最小化/最大化对之间的距离来学习嵌入。CLIP 使用正/负对来学习嵌入,但像 BYOL 或 SimSiam 这样的方法不需要正+负数据对,只需要将同一图像的两个增广的结果输入带有 BYOL 的孪生神经网络(用于比较实体的模型) 并且在其中一个分支中使用梯度停止的操作。其中一个分支(预测分支)的学习方式与另一个分支(在线分支)相同,因此存在一种平衡可以确保在线和目标表示之间的任何匹配不会仅仅归因于预测权重。使用权重衰减和停止梯度有助于这种平衡,并且它们更高效、更简单,在维护SOTA的同时需要更小的批处理大小。
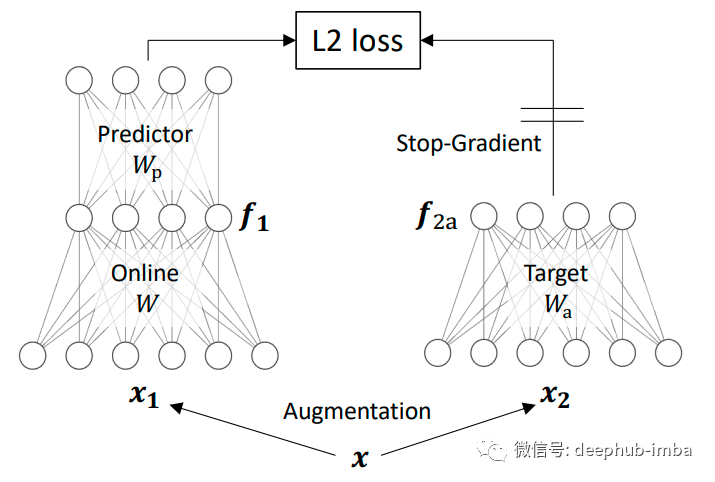
该论文中链接解释了这些方法背后的数学理论,数学是无聊的部分😅,这里也不详细的解释了。
另外一个亮点是引入DirectPred作为预测器,它通过估计预测器输入的相关矩阵并将其权重设置为此的函数来避免使用梯度下降。该相关矩阵是通过预测变量和相关矩阵的权重之间的特征空间对齐以及使用权重衰减收敛到不变抛物线来计算的。
其他
以下这些论文也非常的重要(我认为),但是他可能不是在今年发布的,但是对今年这些论文的发展有着重要启发,所以这里还是要提一下。
如何在神经网络中表示部分-整体层次结构(https://arxiv.org/pdf/2102.12627.pdf):我将引用 Yannic Kilcher 的一个非常好的描述,我认为它更好地描述了这篇论文:“Geoffrey Hinton 描述了 GLOM,一种结合了transformers、神经场、对比学习、胶囊网络、去噪的计算机视觉模型自编码器和 RNN。GLOM 将图像分解为对象及其部分的解析树。与以前的系统不同,解析树是针对每个输入动态且不同地构建的,而不会改变底层神经网络。这是通过多步一致性算法完成的,该算法同时在图像的每个位置运行不同的抽象级别。GLOM 目前只是一个想法,但提出了一种全新的 AI 视觉场景理解方法。”
知识蒸馏: 神经网络变得越来越大,每年都需要更多的计算资源。将知识转移到较小网络同时保持其准确性的一种方法是使用所谓的知识蒸馏。最初由 Hinton 定义(他无处不在)是由一种学生-教师学习的方法,该方法将最重要的信息从一个巨大的网络中提取到一个较小的网络中。我认为这篇论文(https://arxiv.org/pdf/2004.05937.pdf)非常广泛地解释了 KD 的 SOTA 和新前景。
自/零/无监督学习:深度学习社区开发了令人惊叹的架构,可以真正受益于在大量数据上进行训练。现在的瓶颈在于数据收集和标记,一个数据标注可能需要数小时的人工工作并且非常低效。这篇论文专注于自监督学习(https://arxiv.org/pdf/2110.09327.pdf)非常巧妙地解释了让网络生成自己的标签的优缺点以及它如何改变网络的数据内部表示。
胶囊网络:Hinton 我们已经在 GLOM 中提到了它,但是胶囊网络这个概念在 2021 年还差得很远,但未来几年它的规模将会增长。主要思想是以观察概率和姿态的形式向标准 CNN 添加更多结构。这样使图像识别获得了额外的空间鲁棒性即图像上的排列,说到排列不就是一个一个的16*16的块吗😏
基于流的生成模型:无监督学习、强化学习、图像生成……你能想到的!今年基于流的标准化分布建模将进入你的视野,并且会持续一段时间。亚马逊 Alexa 的声音就是使用这些生成的。这是一个容易理解的概念吗?不完全是?这是一种直接对数据似然进行建模的惊人方法,与 SOTA 图像和音频生成相比,它产生了惊人的结果,但是这个方法的需要强大数学基础,也就是说需要更多的时间才能得到其他概念的总体思路,你懂的!
作者:Diego Bonilla