
联邦学习也称为协同学习,它可以在产生数据的设备上进行大规模的训练,并且这些敏感数据保留在数据的所有者那里,本地收集、本地训练。在本地训练后,中央的训练协调器通过获取分布模型的更新获得每个节点的训练贡献,但是不访问实际的敏感数据。
联邦学习本身并不能保证隐私(稍后我们将讨论联邦学习系统中的隐私破坏和修复),但它确实使隐私成为可能。
联邦学习的用例:
- 手机输入法的下一个词预测(e.g. McMahan et al. 2017, Hard et al. 2019)
- 健康研究(e.g. Kaissis et al. 2020, Sadilek et al. 2021)
- 汽车自动驾驶(e.g. Zeng et al. 2021, OpenMined 的文章)
- “智能家居”系统(e.g. Matchi et al. 2019, Wu et al. 2020)
因为隐私的问题所以对于个人来说,人们宁愿放弃他们的个人数据,也不会将数据提供给平台(平台有时候也想着白嫖😉),所以联邦学习几乎涵盖了所有以个人为单位进行预测的所有场景。
随着公众和政策制定者越来越意识到隐私的重要性,数据实践中对保护隐私的机器学习的需求也正在上升,对于数据的访问受到越来越多的审查,对联邦学习等尊重隐私的工具的研究也越来越活跃。在理想情况下,联邦学习可以在保护个人和机构的隐私的前提下,使数据利益相关者之间的合作成为可能,因为以前商业机密、私人健康信息或数据泄露风险的通常使这种合作变得困难甚至无法进行。
欧盟《通用数据保护条例》或《加利福尼亚消费者隐私法》等政府法规使联邦学习等隐私保护策略成为希望保持合法运营的企业的有用工具。与此同时,在保持模型性能和效率的同时获得所需的隐私和安全程度,这本身就带来了大量技术挑战。
从个人数据生产者(我们都是其中的一员)的日常角度来看,至少在理论上是可以在私人健康和财务数据之间放置一些东西来屏蔽那种跟踪你在网上行为设置暴露你的个人隐私的所谓的大杂烩生态系统。
如果这些问题中的任何一个引起你的共鸣,请继续阅读以了解更多关于联邦学习的复杂性以及它可以为使用敏感数据的机器学习做了哪些工作。
联邦学习简介
联邦学习的目的是训练来自多个数据源的单个模型,其约束条件是数据停留在数据源上,而不是由数据源(也称为节点、客户端)交换,也不是由中央服务器进行编排训练(如果存在的话)。
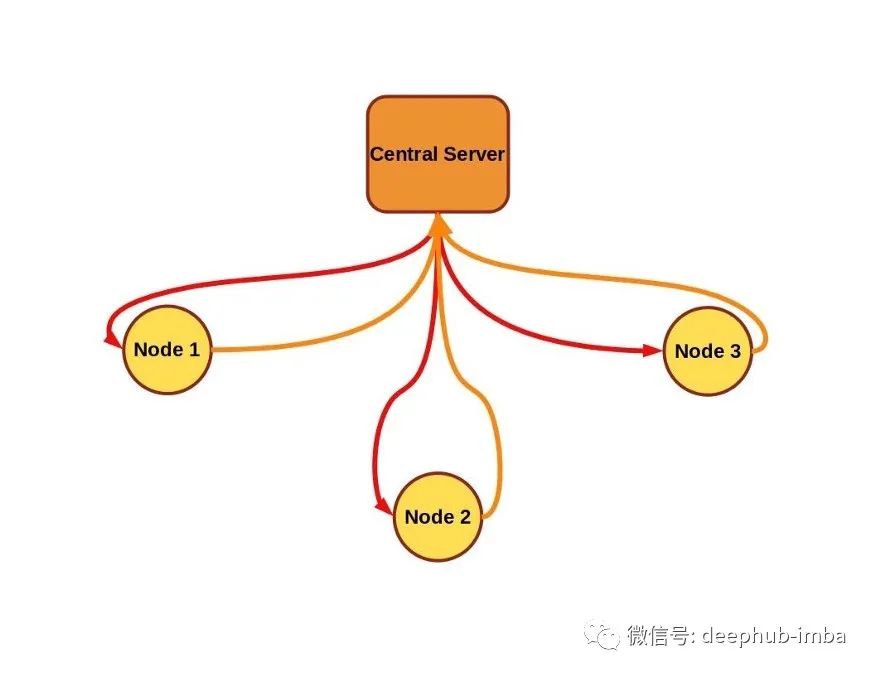
在典型的联邦学习方案中,中央服务器将模型参数发送到各节点(也称为客户端、终端或工作器)。节点针对本地数据的一些训练初始模型,并将新训练的权重发送回中央服务器,中央服务器对新模型参数求平均值(通常与在每个节点上执行的训练量有关)。在这种情况下,中央服务器或其他节点永远不会直接看到任何一个其他节点上的数据,并使用安全聚合等附加技术进一步增强隐私。
该框架内有许多变体。例如,在本文中主要关注由中央服务器管理的联邦学习方案,该方案在多个相同类型的设备上编排训练,节点上每次训练都使用自己的本地数据并将结果上传到中央服务器,这是在 2017 年由 McMahan 等人描述的基本方案。但是某些情况下可能需要取消训练的集中控制,当单个节点分配中央管理器的角色时,它就变成了去中心化的联邦学习,这是针对特殊的医疗数据训练模型的一种有效的解决方案。
典型的联邦学习场景可能涉及大量的设备(例如手机),所有手机的计算能力大致相似,训练相同的模型架构。但有一些方案,例如Diao等人2021年提出的HeteroFL允许在具有巨大差异的通信和计算能力的各种设备上训练一个单一的推理模型,甚至可以训练具有不同架构和参数数量的局部模型,然后将训练的参数聚集到一个全局推理模型中。
联邦学习还有一个优势是数据保存在产生数据的设备上,训练数据集通常比模型要大得多,因此发送后者而不是前者可以节省带宽。
但在这些优势中最重要的还是隐私保护,虽然有可能仅通过模型参数更新就推断出关于私有数据集内容的某些内容。McMahan等人在2017年使用了一个简单的例子来解释该漏洞,即使用一个“词袋”输入向量训练的语言模型,其中每个输入向量具体对应于一个大词汇表中的一个单词。对于相应单词的每个非零梯度更新将为窃听者提供一个关于该单词在私有数据集中存在(反之亦然)的线索,还有更复杂的攻击也被证实了。为了解决这个问题,可以将多种隐私增强技术整合到联邦学习中,从安全的更新聚合到使用完全同态加密进行训练。下面我们将简要介绍联邦学习中对隐私的最突出的威胁及其缓解措施。
国家对数据隐私的监管是一个新兴的政策领域,但是要比基于个人数据收集和分析的发展要晚10到20年。2016年颁布的《欧洲一般数据保护条例》(European General data Protection regulation,简称GDPR)是最重要的关于公众个人数据的法规,这可能会有些奇怪,因为类似的保护限制企业监测和数据收集的措施施尚处于起步阶段甚至是没有。
两年后的2018年,加州消费者隐私法案紧随欧盟的GDPR成为法律。作为一项州法律,与GDPR相比,CCPA在地理范围上明显受到限制,该法案对个人信息的定义更窄。
联邦学习的名字是由McMahan等人在2017年的一篇论文中引入的,用来描述分散数据模型的训练。作者根据2012年白宫关于消费者数据隐私的报告为他们的系统制定了设计策略。他们提出了联邦学习的两个主要用例:图像分类和用于语音识别或下一个单词/短语预测的语言模型。
不久以后与分布式训练相关的潜在攻击就相继的出现了。Phong et al. 2017和Bhowmick et al. 2018等人的工作表明,即使只访问从联邦学习客户端返回到服务器的梯度更新或部分训练的模型,也可以推断出一些描述私人数据的细节。在inphero的文章中,你可以看到关于隐私问题的总结和解决方法。
在联邦学习中,隐私、有效性和效率之间的平衡涉及广泛的领域。服务器和客户机之间的通信(或者仅仅是去中心化客户机之间的通信)可以在传输时进行加密,但还有一个更健壮的选项即在训练期间数据和模型也保持加密。同态加密可用于对加密的数据执行计算,因此(在理想情况下)输出只能由持有密钥的涉众解密。OpenMined的PySyft、Microsoft的SEAL或TensorFlow Encrypted等库为加密的深度学习提供了工具,这些工具可以应用到联邦学习系统中。
关于联邦学习的介绍到此为止,接下来我们将在教程部分中设置一个简单的联邦学习演示。
联邦学习代码实现
既然我们已经知道在何处以及为什么要使用联邦学习,那么让我们动手看看我们如何这样做,在这里我们使用鸢尾花数据集进行联邦学习。
有许多联邦学习库可供选择,从在 GitHub 上拥有超过 1700 颗星的更主流的 Tensorflow Federated 到流行且注重隐私的 PySyft,再到面向研究的 FedJAX。下面表中包含流行的联邦学习存储库的参考列表。
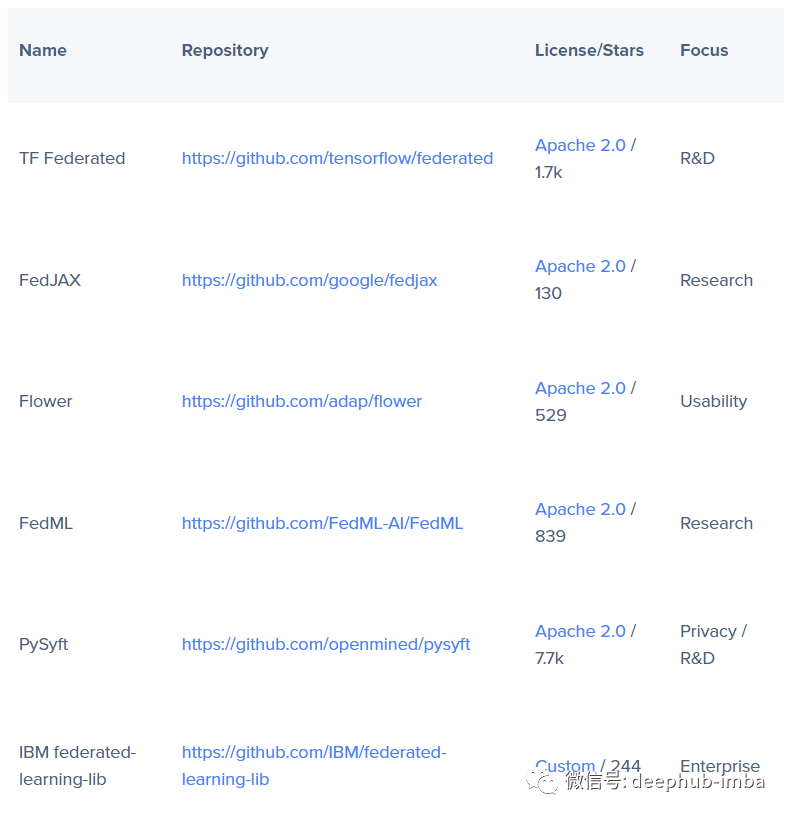
在我们的演示中将使用 Flower 库。我们选择这个库的部分原因是它以一种可访问的方式举例说明了基本的联邦学习概念并且它与框架无关,Flower 可以整合任何构建模型的深度学习工具包(他们在文档中有 TensorFlow、PyTorch、MXNet 和 SciKit-Learn 的示例)所以我们将使用 SciKit-Learn 中包含的“iris”数据集和Pytorch来验证它所说的与框架无关的这个特性。从高层的角度来看我们需要设置一个服务器和一个客户端,对于客户端我们使用不同的训练数据集。首先就是设置中央协调器。
设置协调器的第一步就是定义一个评估策略并将其传递给 Flower 中的默认配置服务器。但首先让我们确保设置了一个虚拟环境,其中包含需要的所有依赖项。在 Unix 命令行上:
virtualenv flower_env python==python3
source flower_env/bin/activate
pip install flwr==0.17.0# I'm running this example on a laptop (no gpu)
# so I am installing the cpu only version of PyTorch
# follow the instructions at https://pytorch.org/get-started/locally/
# if you want the gpu optionpip install torch==1.9.1+cpu torchvision==0.10.1+cpu \
-f https://download.pytorch.org/whl/torch_stable.htmlpip install scikit-learn==0.24.0
随着我们的虚拟环境启动并运行,我们可以编写一个模块来启动 Flower 服务器来处理联邦学习。在下面的代码中,我们包含了 argparse,以便在从命令行调用服务器模块时更容易地试验不同数量的训练轮次。我们还定义了一个生成评估函数的函数,这是我们添加到 Flower 服务器默认配置使用的策略中的唯一其他内容。
以下我们的服务器模块文件的内容:
import argparse
import flwr as fl
import torch
from pt_client import get_data, PTMLPClient
def get_eval_fn(model):
# This `evaluate` function will be called after every round
def evaluate(parameters: fl.common.Weights):
loss, _, accuracy_dict = model.evaluate(parameters)
return loss, accuracy_dict
return evaluate
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-r", "--rounds", type=int, default=3,\
help="number of rounds to train")
args = parser.parse_args()
torch.random.manual_seed(42)
model = PTMLPClient(split="val")
strategy = fl.server.strategy.FedAvg( \
eval_fn=get_eval_fn(model),\
)
fl.server.start_server("[::]:8080", strategy=strategy, \
config={"num_rounds": args.rounds})
注意上面代码中调用的 PTMLPClient。这个是server模块用来定义评估函数的,这个类也是用于训练的模型类并兼作联邦学习客户端。接下来我们将定义 PTMLPClient,并继承Flower 的 NumPyClient 类和 torch.nn.Module 类,如果您使用 PyTorch,你肯定就熟悉它们。
NumPyClient 类处理与服务器的通信,我们需要实现4个抽象函数 set_parameters、get_parameters、fit 和evaluate。torch.nn.Module 类为我们提供了 PyTorch 模型,还有就是使用 PyTorch Adam 优化器进行训练的能力。我们的 PTMLPClient 类只有 100 多行代码,所以我们将从 init 开始依次介绍每个类的函数。
请注意,我们从两个类继承。从 nn.Module 继承意味着我们必须确保使用 super 命令从 nn.Module 调用 init,但是如果您忘记这样做,Python 会立即通知你。除此之外,我们将三个线性层初始化为矩阵(torch.tensor 数据类型),并将一些关于训练分割和模型维度的信息存储为类变量。
class PTMLPClient(fl.client.NumPyClient, nn.Module):
def __init__(self, dim_in=4, dim_h=32, \
num_classes=3, lr=3e-4, split="alice"):
super(PTMLPClient, self).__init__()
self.dim_in = dim_in
self.dim_h = dim_h
self.num_classes = num_classes
self.split = split
self.w_xh = nn.Parameter(torch.tensor(\
torch.randn(self.dim_in, self.dim_h) \
/ np.sqrt(self.dim_in * self.dim_h))\
)
self.w_hh = nn.Parameter(torch.tensor(\
torch.randn(self.dim_h, self.dim_h) \
/ np.sqrt(self.dim_h * self.dim_h))\
)
self.w_hy = nn.Parameter(torch.tensor(\
torch.randn(self.dim_h, self.num_classes) \
/ np.sqrt(self.dim_h * self.num_classes))\
)
self.lr = lr
接下来我们将定义 PTMLPClient 类的 get_parameters 和 set_parameters 函数。这些函数将所有模型参数连接为一个扁平的 numpy 数组,这是 Flower 的 NumPyClient 类预期返回和接收的数据类型。这符合联邦学习方案,因为服务器将向每个客户端发送初始参数(使用 set_parameters)并期望返回一组部分训练的权重(来自 get_parameters)。这种模式在训练的每轮出现一次。我们还在 set_parameters 中初始化优化器和损失函数。
def get_parameters(self):
my_parameters = np.append(\
self.w_xh.reshape(-1).detach().numpy(), \
self.w_hh.reshape(-1).detach().numpy() \
)
my_parameters = np.append(\
my_parameters, \
self.w_hy.reshape(-1).detach().numpy() \
)
return my_parameters
def set_parameters(self, parameters):
parameters = np.array(parameters)
total_params = reduce(lambda a,b: a*b,\
np.array(parameters).shape)
expected_params = self.dim_in * self.dim_h \
+ self.dim_h**2 \
+ self.dim_h * self.num_classes
start = 0
stop = self.dim_in * self.dim_h
self.w_xh = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_in, self.dim_h).float() \
)
start = stop
stop += self.dim_h**2
self.w_hh = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_h, self.dim_h).float() \
)
start = stop
stop += self.dim_h * self.num_classes
self.w_hy = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_h, self.num_classes).float()\
)
self.act = torch.relu
self.optimizer = torch.optim.Adam(self.parameters())
self.loss_fn = nn.CrossEntropyLoss()
接下来,我们将定义我们的前向传递和一个用于获取损失标量的函数。
def forward(self, x):
x = self.act(torch.matmul(x, self.w_xh))
x = self.act(torch.matmul(x, self.w_hh))
x = torch.matmul(x, self.w_hy)
return x
def get_loss(self, x, y):
prediction = self.forward(x)
loss = self.loss_fn(prediction, y)
return loss
我们客户端还需要的最后几个函数是fit和evaluate。对于每一轮,每个客户端在进行几个阶段的训练之前使用提供给fit方法的参数初始化它的参数(在本例中默认为10)。evaluate方法在计算训练数据验证的损失和准确性之前设置参数。
def fit(self, parameters, config=None, epochs=10):
self.set_parameters(parameters)
x, y = get_data(split=self.split)
x, y = torch.tensor(x).float(), torch.tensor(y).long()
self.train()
for ii in range(epochs):
self.optimizer.zero_grad()
loss = self.get_loss(x, y)
loss.backward()
self.optimizer.step()
loss, _, accuracy_dict = self.evaluate(self.get_parameters())
return self.get_parameters(), len(y), \
{"loss": loss, "accuracy": \
accuracy_dict["accuracy"]}
def evaluate(self, parameters, config=None):
self.set_parameters(parameters)
val_x, val_y = get_data(split="val")
val_x = torch.tensor(val_x).float()
val_y = torch.tensor(val_y).long()
self.eval()
prediction = self.forward(val_x)
loss = self.loss_fn(prediction, val_y).detach().numpy()
prediction_class = np.argmax(\
prediction.detach().numpy(), axis=-1)
accuracy = sklearn.metrics.accuracy_score(\
val_y.numpy(), prediction_class)
return float(loss), len(val_y), \
{"accuracy":float(accuracy)}
我们的客户端类中的 fit 和evaluate都调用了一个函数 get_data,它只是 SciKit-Learn iris 数据集的包装器。它还将数据拆分为训练集和验证集,并进一步拆分训练数据集(我们称为“alice”和“bob”)以模拟联邦学习,因为联邦学习的客户端都有自己的数据。
def get_data(split="all"):
x, y = sklearn.datasets.load_iris(return_X_y=True)
np.random.seed(42); np.random.shuffle(x)
np.random.seed(42); np.random.shuffle(y)
val_split = int(0.2 * x.shape[0])
train_split = (x.shape[0] - val_split) // 2
eval_x, eval_y = x[:val_split], y[:val_split]
alice_x, alice_y = x[val_split:val_split + train_split], y[val_split:val_split + train_split]
bob_x, bob_y = x[val_split + train_split:], y[val_split + train_split:]
train_x, train_y = x[val_split:], y[val_split:]
if split == "all":
return train_x, train_y
elif split == "alice":
return alice_x, alice_y
elif split == "bob":
return bob_x, bob_y
elif split == "val":
return eval_x, eval_y
else:
print("error: split not recognized.")
return None
现在我们只需要在文件底部填充一个 if name == "main": 方法,以便我们可以从命令行将我们的客户端代码作为模块运行。
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-s", "--split", type=str, default="alice",\
help="The training split to use, options are 'alice', 'bob', or 'all'")
args = parser.parse_args()
torch.random.manual_seed(42)
fl.client.start_numpy_client("localhost:8080", client=PTMLPClient(split=args.split))
最后,确保在客户端模块的顶部导入所需的所有内容。
import argparse
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.metrics
import torch
import torch.nn as nn
from functools import reduce
import flwr as fl
这就是我们使用 Flower 运行联邦训练演示所需实现的全部代码!
要开始运行联邦训练,首先在其命令行终端中启动服务器。我们将我们的服务器保存为 pt_server.py,我们的客户端模块保存为 pt_client.py,两者都在我们正在工作的目录的根目录中,所以为了启动一个服务器并告诉它进行40 轮联邦学习,我们使用以下命令。
python -m pt_server -r 40
接下来打开一个新的终端,用“alice”训练分组启动你的第一个客户端:
python -m pt_client -s alice
启动“bob”训练分组的第二个客户端。
python -m pt_client -s bob
如果一切正常,在运行服务器进程的终端中看到训练启动和信息滚动。
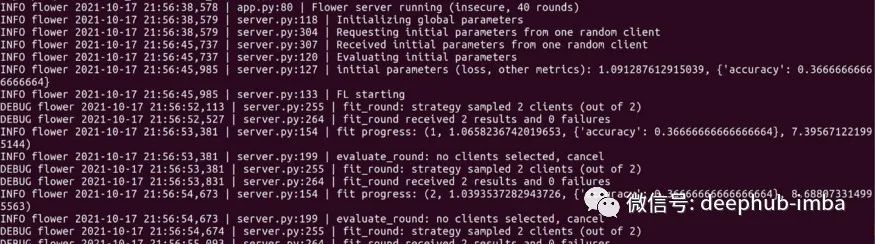
这个演示在 20 轮训练中达到了 96% 以上的准确率。训练运行的损失和准确度曲线如下所示:

联邦学习的未来
人们可能会相信“再也没有隐私这种东西了”。这些声明主要是针对互联网的(这样的声明至少从1999年就开始了),但随着智能家居设备和爱管闲事的家用机器人的迅速普及,你可能觉得这些言论是正确的。
但是请注意是谁在做这些声明,你会发现他们中的许多人在你的数据被窃取的过程中是能够获得既得利益的。这种“没有隐私”的失败主义态度不仅是错误的,而且是危险的:失去隐私会使个人和团体以他们可能不会注意到或承认的方式被巧妙地操纵。
联邦学习是伴随着不断扩大的数据量而生的,数据无处不在,联邦学习的优势因此获得了政府、企业等各界的关注。联邦学习能够有效解决数据孤岛和数据隐私保护的两难问题。这将会为未来人工智能协作,从而实现跨越式发展奠定良好基础,在多行业、多领域都有广泛的应用前景。
作者:James Montantes