
Deephub
更多文章请关注公众号:Deephub-IMBA
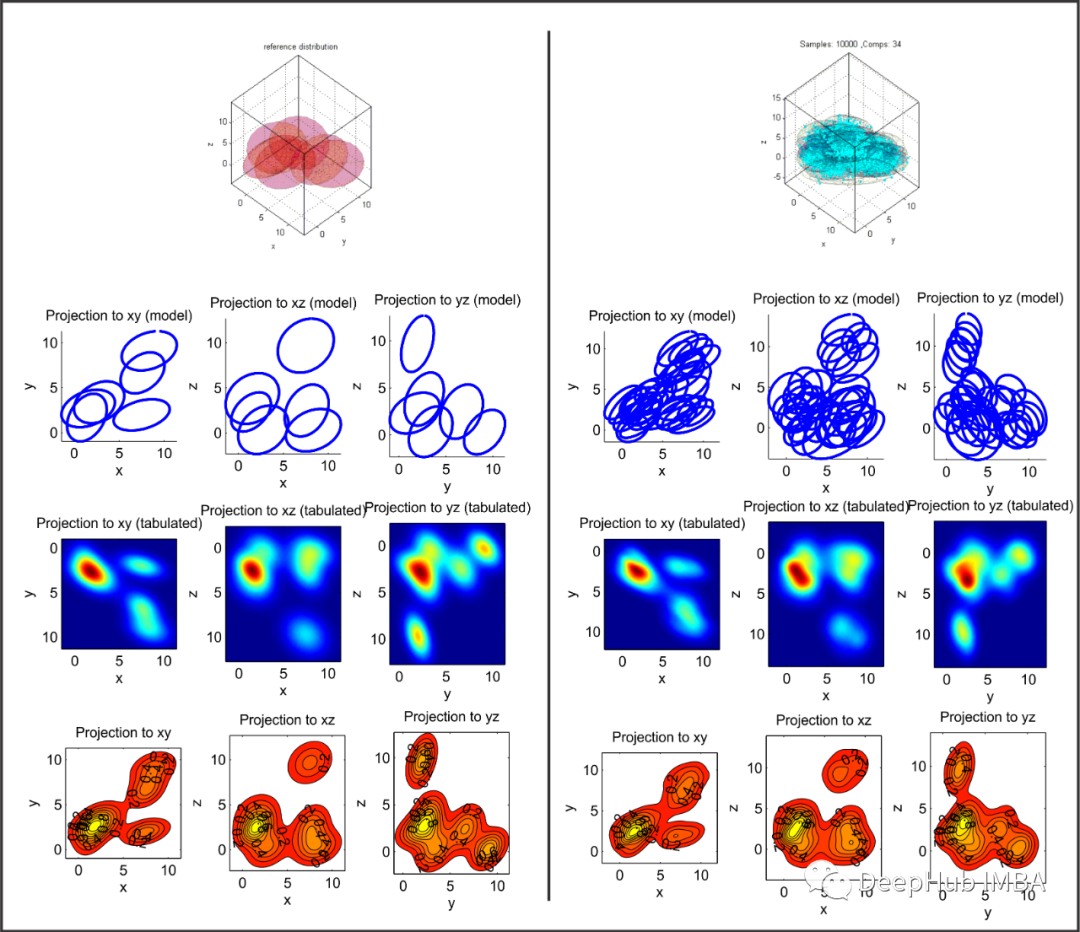
非参数检验方法,核密度估计简介
核密度估计(Kernel Density Estimation,简称KDE)是一种非参数统计方法,用于估计数据样本背后的概率密度函数
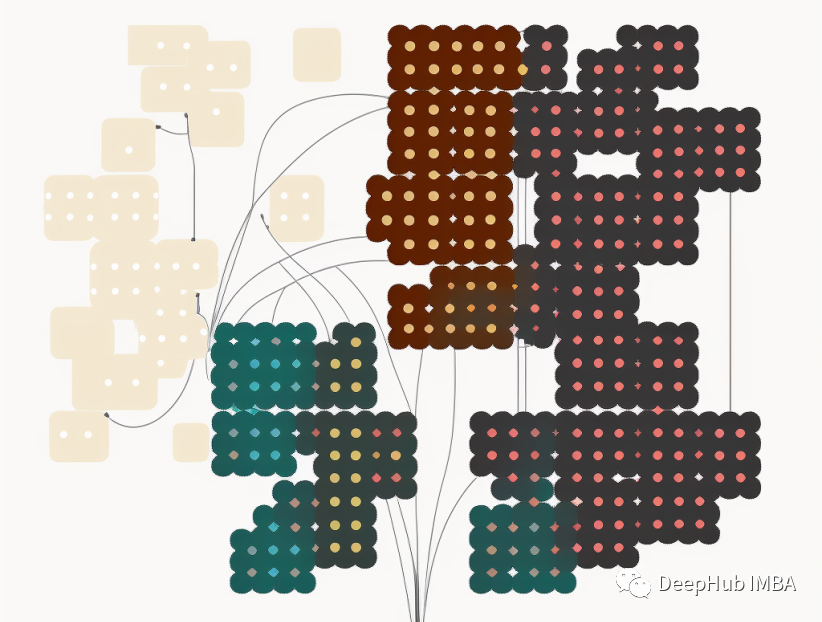
聚类算法(下):10个聚类算法的评价指标
上篇文章我们已经介绍了一些常见的聚类算法,下面我们将要介绍评估聚类算法的指标
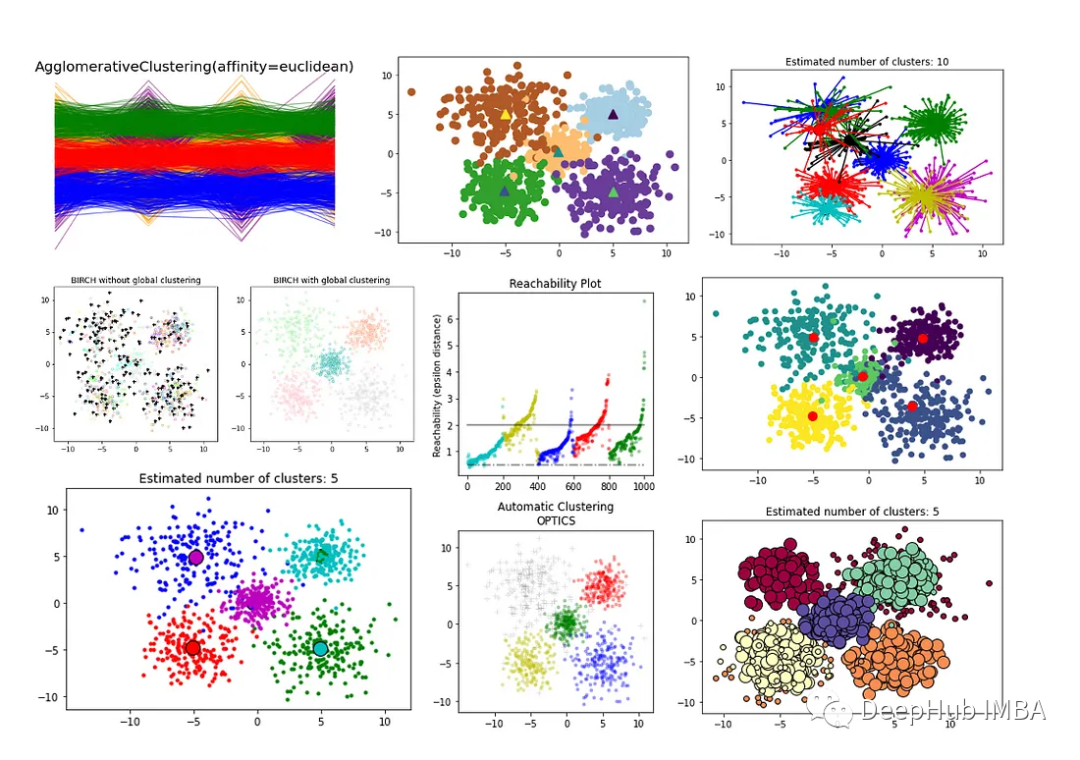
聚类算法(上):8个常见的无监督聚类方法介绍和比较
本文将全面概述Scikit-Learn库中用于的聚类技术以及各种评估方法。本文作为第一部分将介绍和比较各种聚类算法
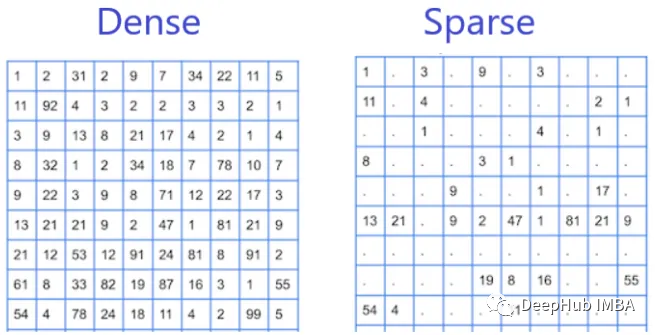
稀疏特征和密集特征
在机器学习中,特征是指对象、人或现象的可测量和可量化的属性或特征。特征可以大致分为两类:稀疏特征和密集特征。
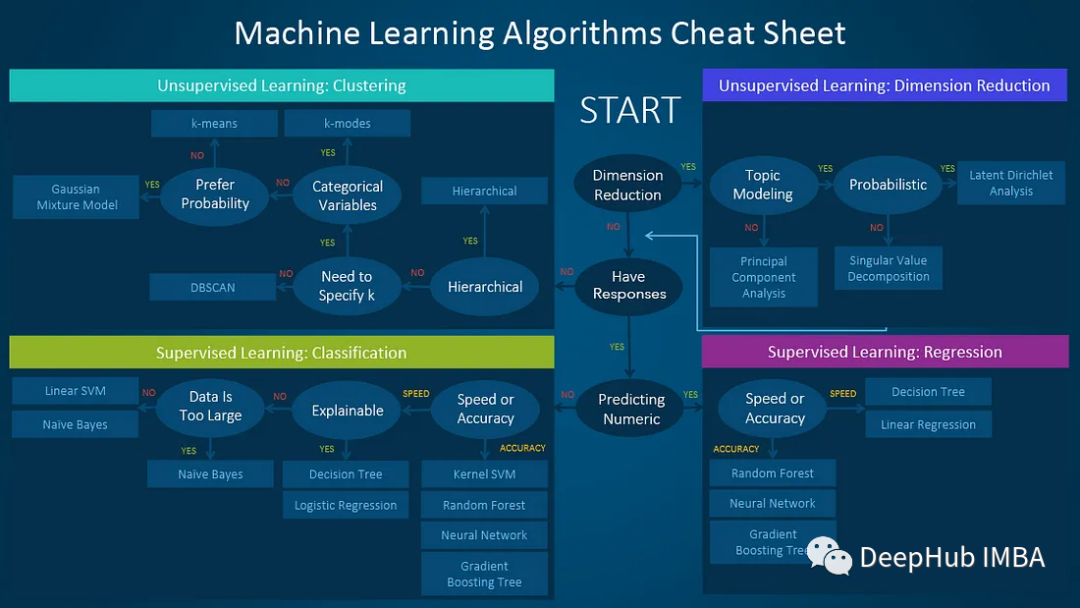
选择最佳机器学习模型的10步指南
机器学习可以用来解决广泛的问题。但是有很多多不同的模型可以选择,要知道哪一个适合是一个非常麻烦的事情。本文的总结将帮助你选择最适合需求的机器学习模型。
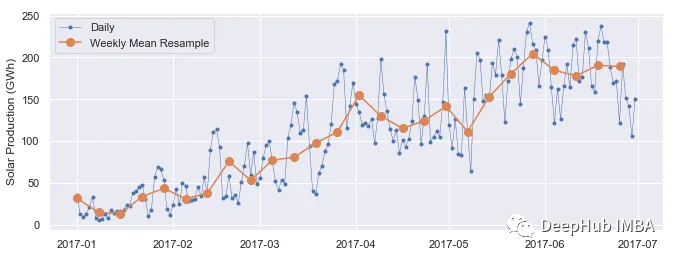
在Pandas中通过时间频率来汇总数据的三种常用方法
当我们的数据涉及日期和时间时,分析随时间变化变得非常重要。Pandas提供了一种方便的方法,可以按不同的基于时间的间隔(如分钟、小时、天、周、月、季度或年)对时间序列数据进行分组。
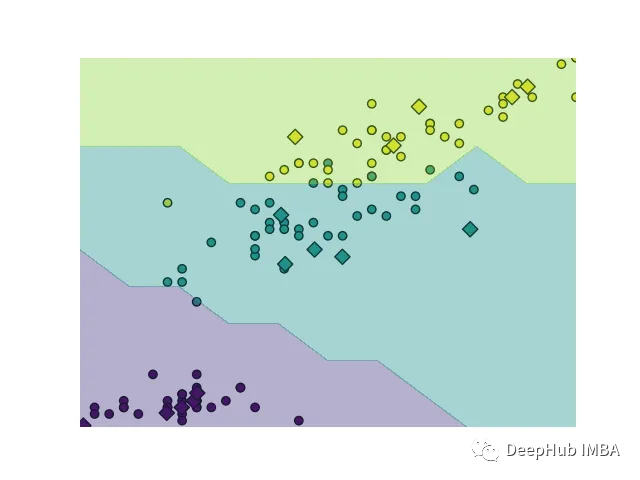
广义学习矢量量化(GLVQ)分类算法介绍和代码实现
广义学习矢量量化(Generalized Learning Vector Quantization,GLVQ)是一种基于原型的分类算法,用于将输入数据分配到先前定义的类别中。
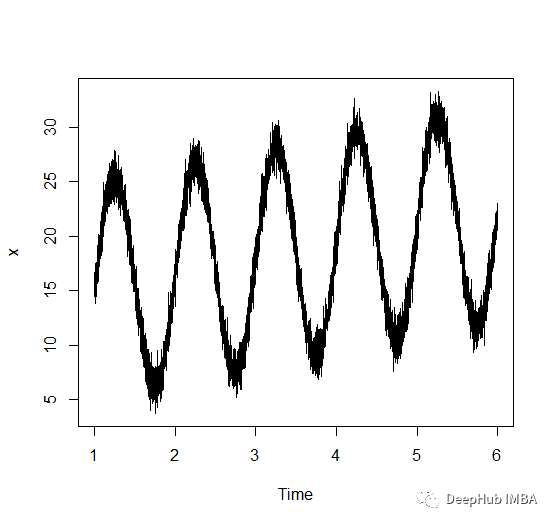
计算时间序列周期的三种方法
周期是数据中出现重复模式所需的时间长度。更具体地说,它是模式的一个完整周期的持续时间。在这篇文章中,将介绍计算时间序列周期的三种不同方法。

使用PyTorch-LSTM进行单变量时间序列预测的示例教程
在本教程中,我们将使用PyTorch-LSTM进行深度学习时间序列预测。
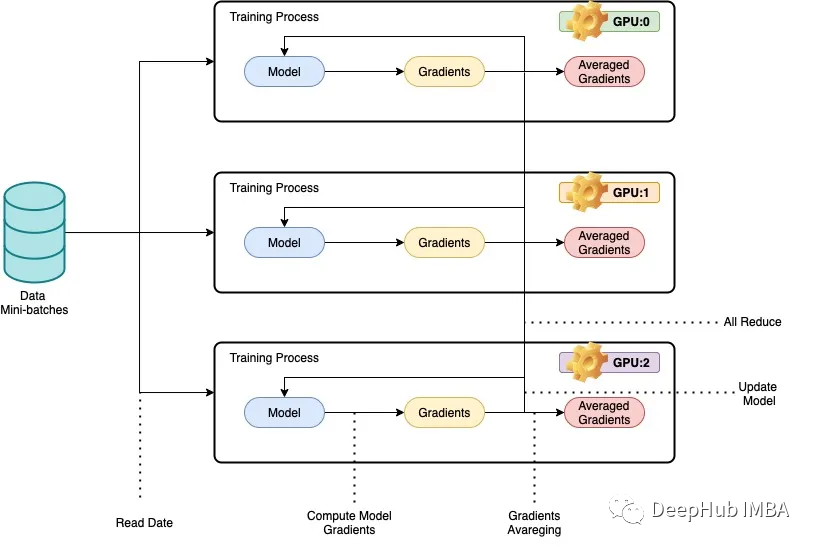
PyTorch 并行训练 DistributedDataParallel完整代码示例
使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。在本文中我们将演示使用 PyTorch 的数据并行性和模型并行性。
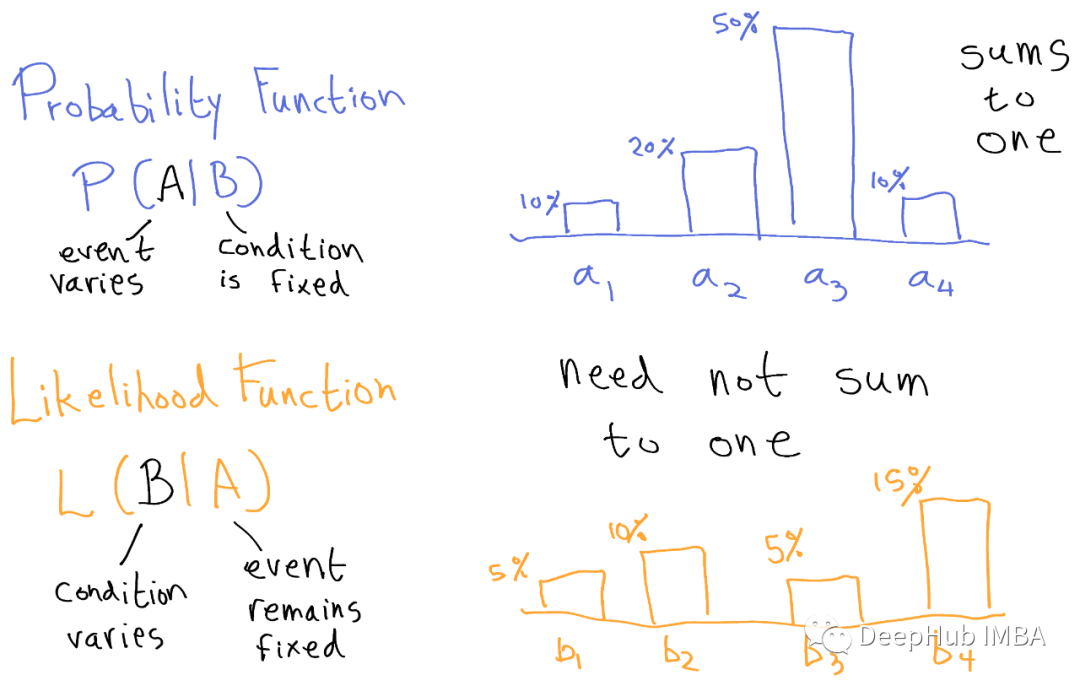
概率和似然
在日常生活中,我们经常使用这些术语。但是在统计学和机器学习上下文中使用时,有一个本质的区别。本文将用理论和例子来解释概率和似然之间的关键区别。
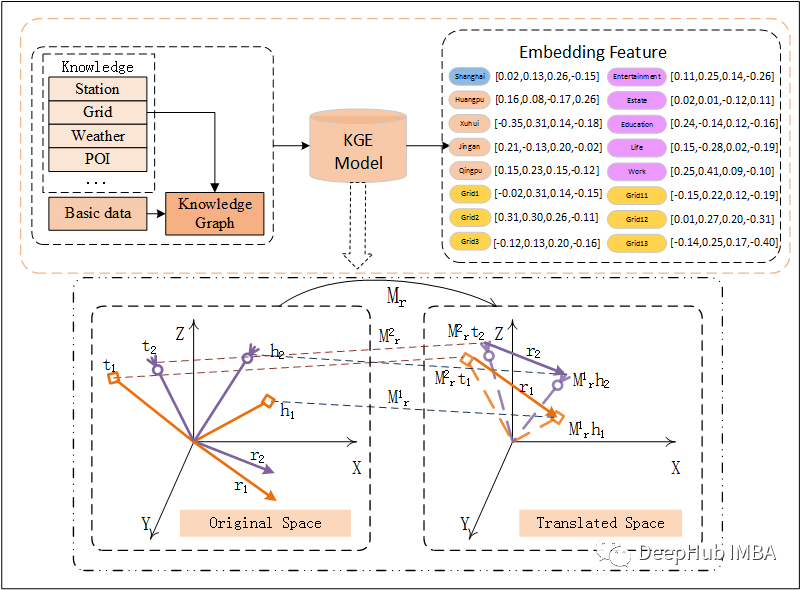
知识图谱嵌入模型 (KGE) 的总结和比较
知识图谱嵌入(KGE)是一种利用监督学习来学习嵌入以及节点和边的向量表示的模型。本文将常见的KGE 模型在捕获关系类型方面的比较
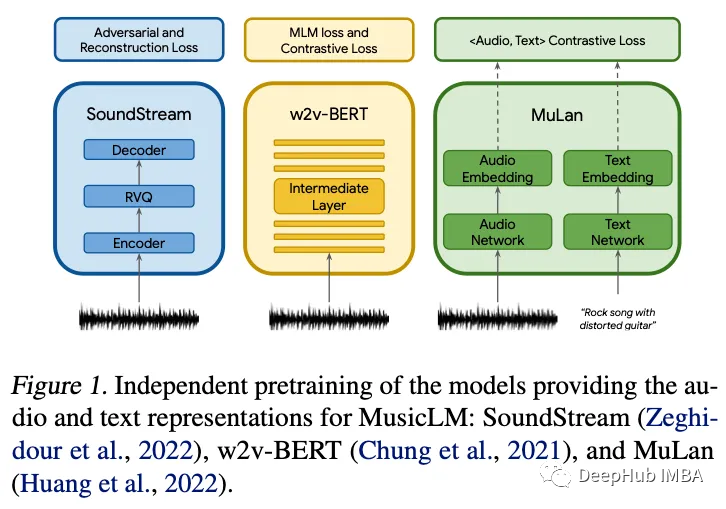
2023年2月的十篇深度学习论文推荐
本月的论文包括语言模型、扩散模型、音乐生成、多模态等主题。

100行Pytorch代码实现三维重建技术神经辐射场 (NeRF)
提起三维重建技术,NeRF是一个绝对绕不过去的名字。本文通过100行的Pytorch代码实现最初的 NeRF 论文。
使用Pandas也可以进行数据可视化
在本文中,我们介绍使用 Pandas 进行数据可视化的基础知识,包括创建简单图、自定义图以及使用多个DF进行绘图。
10个用于可解释AI的Python库
XAI的目标是为模型的行为和决定提供有意义的解释,本文整理了目前能够看到的10个用于可解释AI的Python库

GPT-3 vs Bert vs GloVe vs Word2vec 文本嵌入技术的性能对比测试
本文将GPT3与三种传统文本嵌入技术GloVe、Word2vec(Mikolov ,2013 年)和 BERT生成的嵌入进行性能的简单对比。

使用scikit-learn为PyTorch 模型进行超参数网格搜索
scikit-learn是Python中最好的机器学习库,而PyTorch又为我们构建模型提供了方便的操作,要让PyTorch 模型可以在 scikit-learn 中使用的一个最简单的方法是使用skorch包

机器学习评估指标的十个常见面试问题
评估指标是用于评估机器学习模型性能的定量指标。本文整理了10个常见的问题。
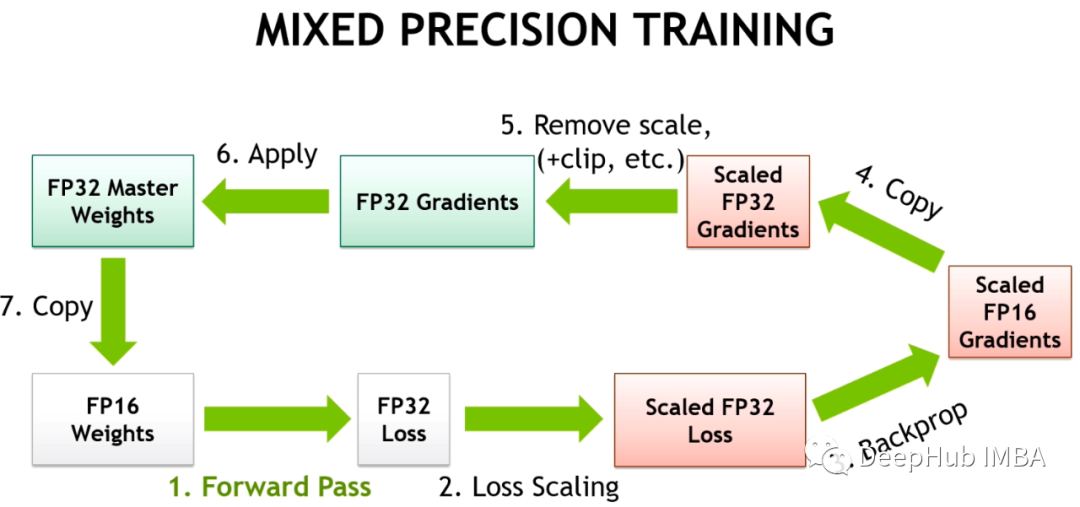
如何解决混合精度训练大模型的局限性问题
混合精度已经成为训练大型深度学习模型的必要条件,但也带来了许多挑战。在这篇文章中,我们将讨论混合精确训练的数值稳定性问题。