
强化学习是机器学习领域的热门子项。由于 OpenAI 和 AlphaGo 等公司的最新突破,强化学习引起了游戏行业许多人的注意。我们今天以Hill Climb Racing这款经典的游戏来介绍DQN的整个概念,Hill Climb Racing需要玩家在不同的地形上驾驶不同的车辆,驾驶距离越长得分越高。
在本篇文章中将通过这个游戏的示例来介绍 Deep Q-Networks 的整个概念,但是因为没有环境所以我们会将其分解成2个独立目标分别实现。如果曾经接触过此类游戏,你可能已经观察到游戏的两个主要目标:1、不要碰撞,2、保持前进。
我们将这两个目标分解成我们的需要的做动作:1、保持平衡,2、爬坡,当然还有一些附加项,例如吃分获取奖励,但是这个并不是我们的主要目标。
在我们深入解决这些问题之前,首先介绍一下解强化学习和DQN的基础知识。
我们先快速介绍一下什么是强化学习,在这种学习中行为主体对环境所做的行动会根据其结果得到奖励。奖励会影响主体(代理、智能体)未来的行为。
- 有利的行动,更多的奖励(积极的)。
- 不利的行动,较少的奖励或者惩罚(在某些情况下是负面的)。
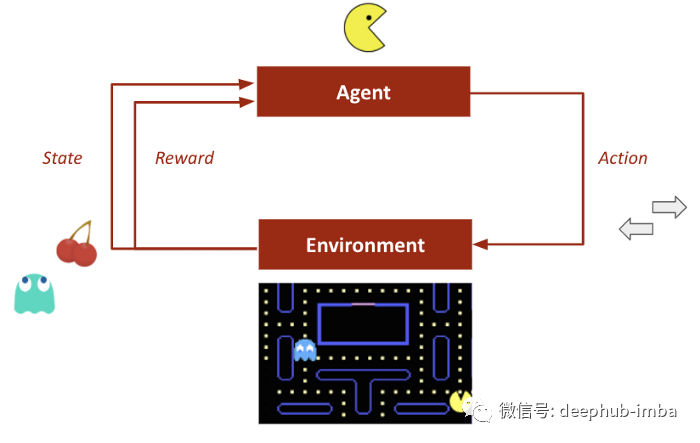
Deep Q-Learning 算法是深度强化学习的核心概念之一。神经网络将输入状态映射到(动作,Q 值)对。
- 动作Action:代理执行的对环境进行后续更改的活动。
- 环境Environment:模型工作的整个状态空间。
- 奖励Rewards:为模型提供的每个动作的反馈。
- Q 值Q-value:估计的最优未来值。
Q-Learning 和 Deep Q-Networks 是无模型算法,因为它们不创建环境转换函数的模型。
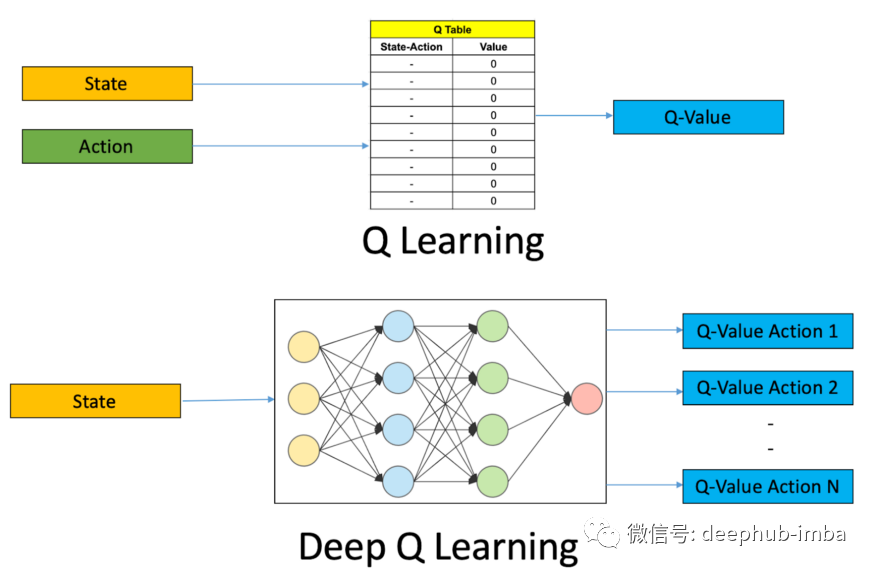
由于 DQN 是一种无模型算法,我们将构建一个与问题中提到的环境兼容的代理。
class Agent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_decay = 0.995
self.epsilon_min = 0.01
self.learning_rate = 0.001
self.model = self._create_model()
def _create_model(self):
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def train(self, batch_size= 32):
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
if not done:
target = reward + self.gamma*np.amax(self.model.predict(next_state)[0])
else:
target = reward
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def load(self, name):
self.model.load_weights(name)
def save(self, name):
self.model.save_weights(name)
在这里我们使用了一个小型网络(带有两个隐藏层)。输入大小是指状态的数量,输出大小对应于动作空间的数量。
Cartpole 平衡
CartPole 或通常称为反摆/倒立摆,它是一种简单的训练环境,目标是向左或向右移动推车以平衡直立杆。在这篇文章中,我们将使用 OpenAI 的gym库提供的模拟环境。

在这个环境中,我们有离散的动作空间和连续的状态空间,如下所示:
动作空间(离散)
- 1 单位力向左。
- 1 单位力向右。
状态空间(连续)
- 小车位置。
- 小车速度。
- 车杆角度
- 极点速度 (pole velocity)。
我们的代理必须尽可能长时间地平衡极点以获取最大化奖励。对于每个成功的时间步,模型都会获得 +1 奖励。我们设定停止的规则:如果车杆远离中心 2.4 个单位或垂直偏离超过 15 度,则本次迭代结束。通过模拟 1000 次更新并在每 50 次迭代后保存最佳权重进行代理的训练。
agent = Agent(state_size, action_size) # initialise agent
done = False
for e in range(n_episodes):
state = env.reset()
state = np.reshape(state,[1,state_size])
for time in range(5000):
env.render()
action = agent.act(state) #action is 0 or 1
next_state,reward,done,other_info = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state,[1,state_size])
agent.remember(state,action,reward,next_state,done)
state = next_state
if done:
print("Game Episode :{}/{}, High Score:{},Exploration Rate:{:.2}".format(e,n_episodes,time,agent.epsilon))
break
if len(agent.memory)>batch_size:
agent.train(batch_size)
if e%50==0:
agent.save(output_dir+"weights_"+'{:04d}'.format(e)+".hdf5")
env.close()
代理在前 250 次迭代内解决了问题,在第199次迭代中取得了稳定高分。我们已经解决了平衡问题。现在需要学习学习如何前进并爬上山坡的时候了。
爬坡
一辆动力不足的车如果想要登上陡峭的山顶,应该使用对面的另一座山,来回行驶以建立所需的动力。

与CartPole相似,该环境也包括离散的动作空间和连续的状态空间。
动作空间(离散)
- 在汽车的左方向施加 1 个单位的力。
- 什么都不做。
- 在汽车的右方向施加 1 个单位的力。
状态空间(连续)
- 汽车位置
- 汽车速度
一般情况下汽车在达到目标(由旗帜标记)时会获得 +100 的奖励。如果在汽车达到成功状态之前,不给予奖励积分,汽车随机到达目标的可能性很小。
所以我们将用另一个奖励条件来激励汽车。山谷最底部的坐标为 -0.4(OpenAI 提供的标准),而目标的坐标为 +0.5,我们将使用汽车垂直高度按比例进行奖励。高度越高,奖励越多。(注:在山谷的两侧高度都进行奖励)
让我们看一下我们将在环境中使用的奖励机制和训练函数。
def get_reward(state):
if state[0] >= 0.5:
print("Car has reached the goal")
return 10
if state[0] > -0.4:
return (1+state[0])**2
return 0
#--------------------------------------------------------------------------#
def train_dqn(episode):
loss = []
agent = DQN(env.action_space.n, env.observation_space.shape[0])
for e in range(episode):
state = env.reset()
state = np.reshape(state, (1, 2))
score = 0
max_steps = 3000
for i in range(max_steps):
action = agent.act(state)
env.render()
next_state, reward, done, _ = env.step(action)
reward = get_reward(next_state)
score += reward
next_state = np.reshape(next_state, (1, 2))
agent.remember(state, action, reward, next_state, done)
state = next_state
agent.replay()
if done:
print("episode: {}/{}, score: {}".format(e, episode, score))
break
loss.append(score)
return loss
在我们的环境中,汽车能够多次达到目标!汽车在训练的过程中第 60、71、74 和 79 次迭代达到了成功状态。
我们还可以使用得分图上的峰值来验证它。
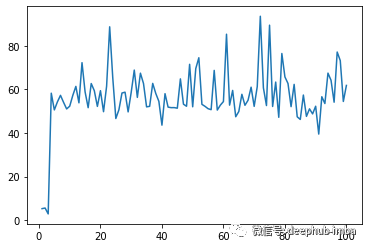
我们已经解决了上面提到的两个问题。虽然将其集成到实际游戏中目前看还是不可能的(因为Hill Climb Racing并没有为我们提供环境),但是如果你有什么好的方案可以尝试一下。
总结
经典的控制问题奠定了当今大多数顶级游戏的强化学习的基础。而OpenAI 的GYM库也为我们提供了更多环境。如果你对其他的环境感兴趣,可以参考GYM的文档,或者看看本文提供的两个例子的源代码。
https://github.com/DSCVITBHOPAL/ML-Reserve/tree/main/CartPole%20Balancing
https://github.com/DSCVITBHOPAL/ML-Reserve/tree/main/Mountain%20Climbing
作者:Sidhved Warik