
Deephub
更多文章请关注公众号:Deephub-IMBA
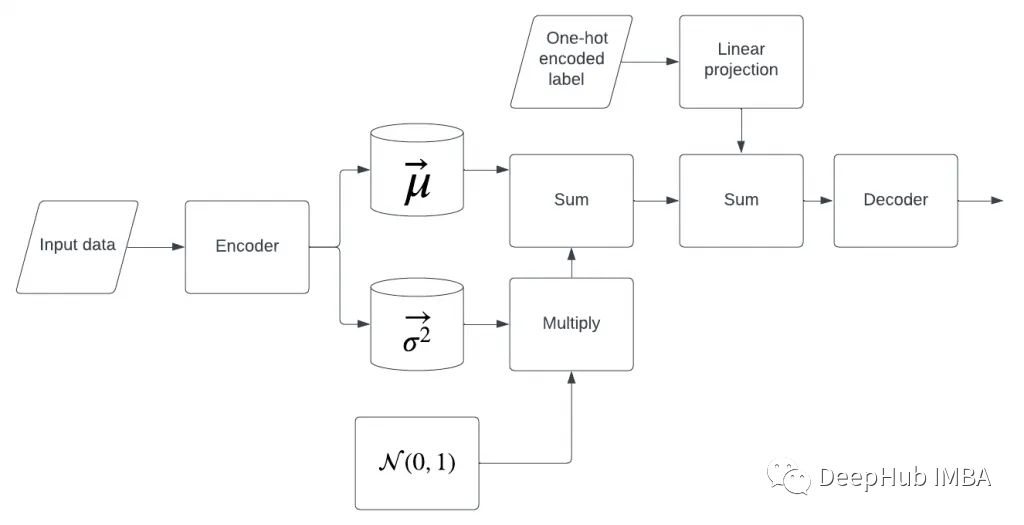
从零开始实现VAE和CVAE
扩散模型可以看作是一个层次很深的VAE(变分自编码器)本文将用python从头开始实现VAE和CVAE,来增加对于它们的理解。

ChatGPT的提示的一些高级知识
在这篇文章中,我们将介绍关于提示的一些高级知识。无论是将ChatGPT用于客户服务、内容创建,还是仅仅为了好玩,本文都将为你提供使用ChatGPT优化提示的知识和技巧。
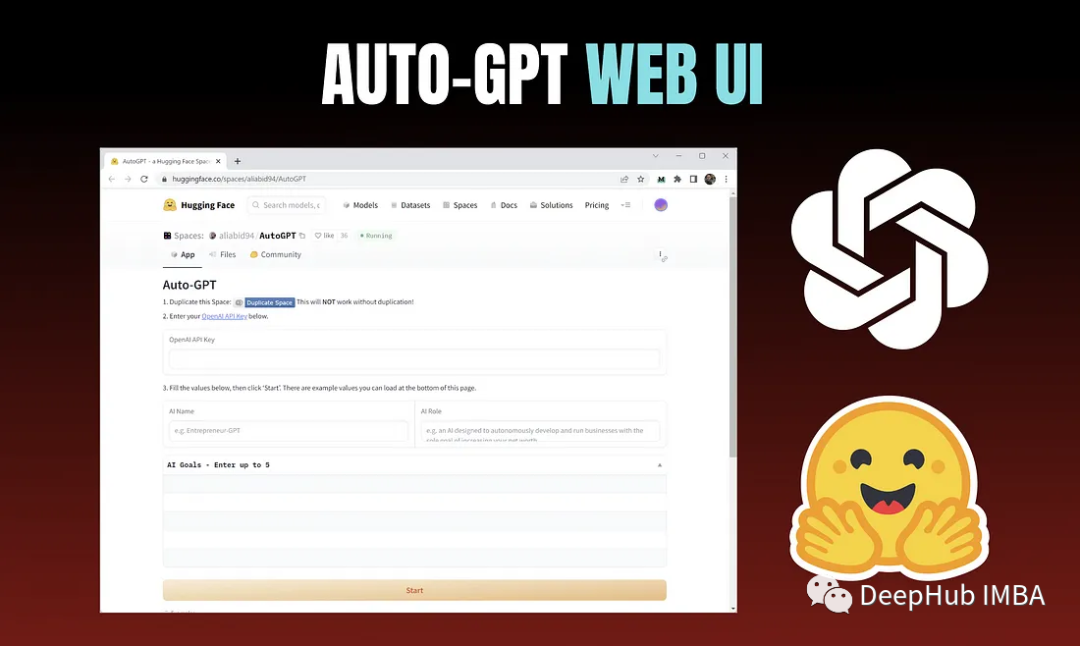
AutoGPT也有Web UI了
现在AutoGPT也有了Web UI,在本文中我们将介绍如何通过Web UI使用AutoGPT。
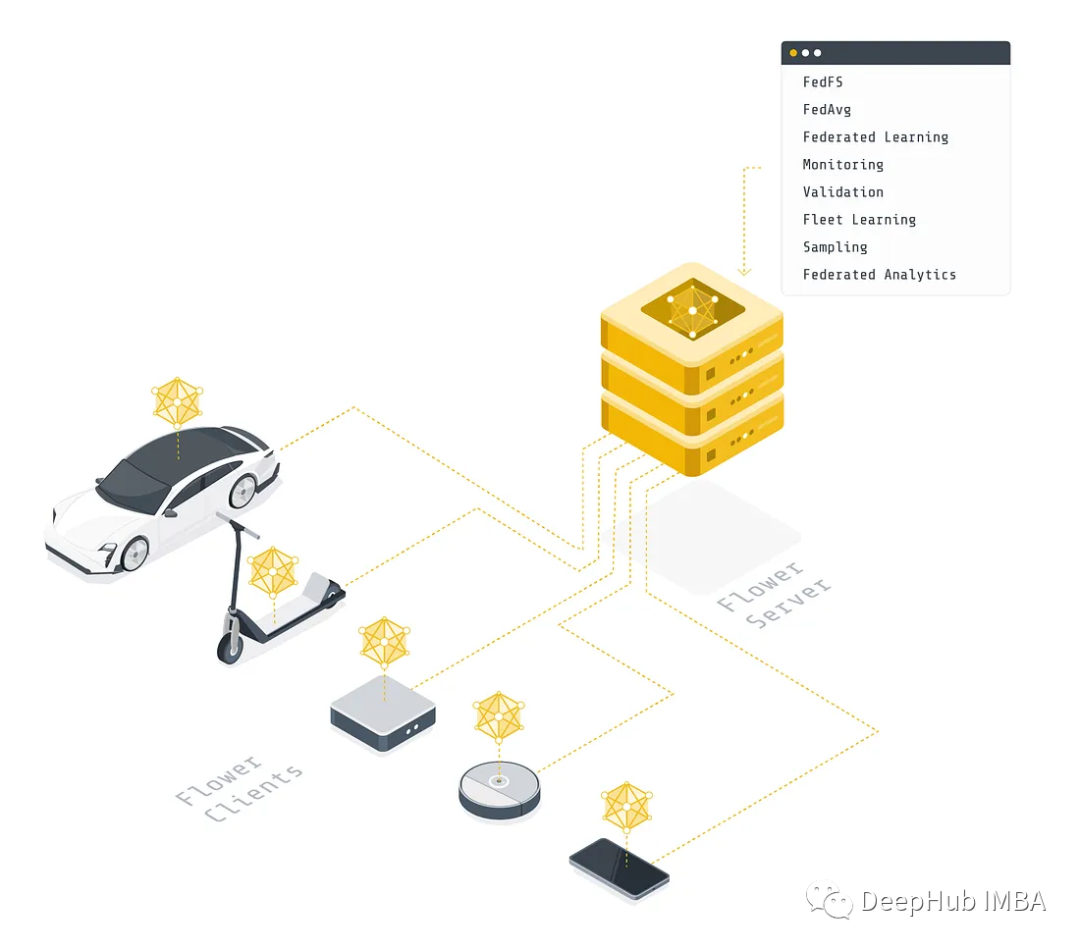
使用PyTorch和Flower 进行联邦学习
本文将介绍如何使用 Flower 构建现有机器学习工作的联邦学习版本。我们将使用 PyTorch 在 CIFAR-10 数据集上训练卷积神经网络,然后将展示如何修改训练代码以联邦的方式运行训练。

参数与非参数检验:理解差异并正确使用
数据科学是一个快速发展的领域,它在很大程度上依赖于统计技术来分析和理解复杂的数据集。这个过程的一个关键部分是假设检验,它有助于确定从样本中获得的结果是否可以推广到总体。
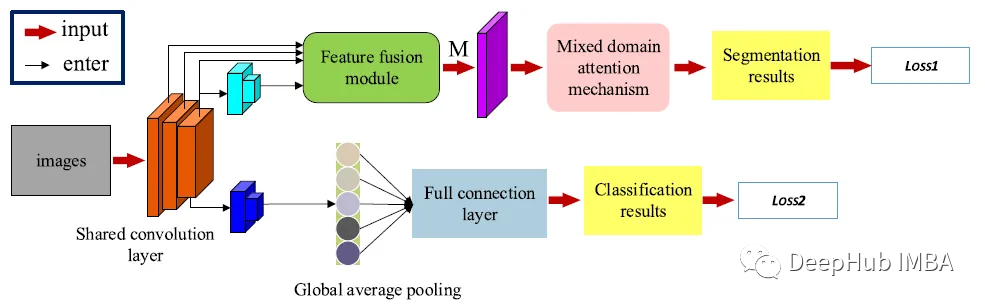
论文推荐:基于联合损失函数的多任务肿瘤分割
以FFANet为主干,加入分类的分支,将模型扩展为多任务图像分割框架,设计了用于分类和分割的联合损失函数。
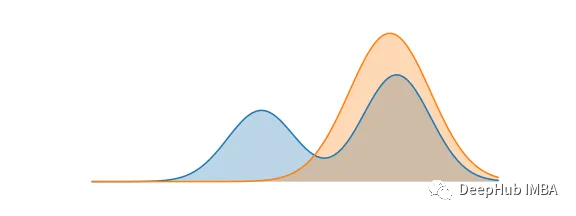
KL散度和交叉熵的对比介绍
KL散度(Kullback-Leibler Divergence)和交叉熵(Cross Entropy)是在机器学习中广泛使用的概念。这两者都用于比较两个概率分布之间的相似性,但在一些方面,它们也有所不同。本文将对KL散度和交叉熵的详细解释和比较。

AutoGPT、AgentGPT、BabyAGI、HuggingGPT、CAMEL:各种基于GPT-4自治系统总结
本文将整理一些开源的类似AutoGPT的工具系统

从Pandas快速切换到Polars :数据的ETL和查询
polar与pandas非常相似,所以如果在处理大数据集的时候,我们可以尝试使用polar,因为它在处理大型数据集时的效率要比pandas高
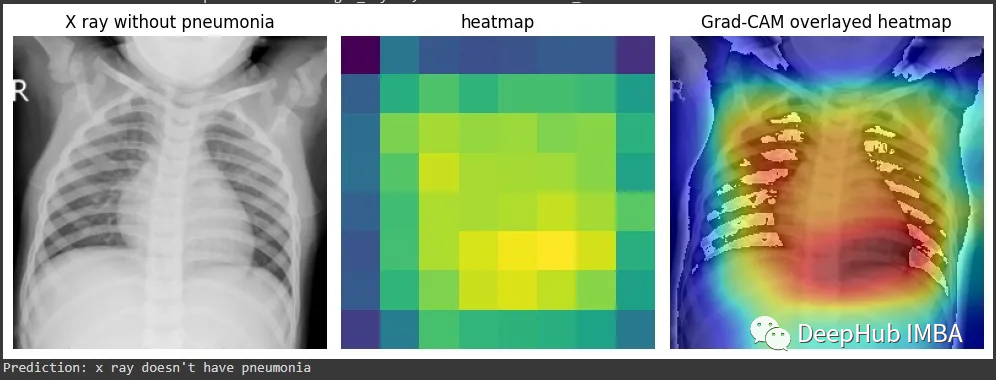
Grad-CAM的详细介绍和Pytorch代码实现
Grad-CAM (Gradient-weighted Class Activation Mapping) 是一种可视化深度神经网络中哪些部分对于预测结果贡献最大的技术。它能够定位到特定的图像区域,从而使得神经网络的决策过程更加可解释和可视化。
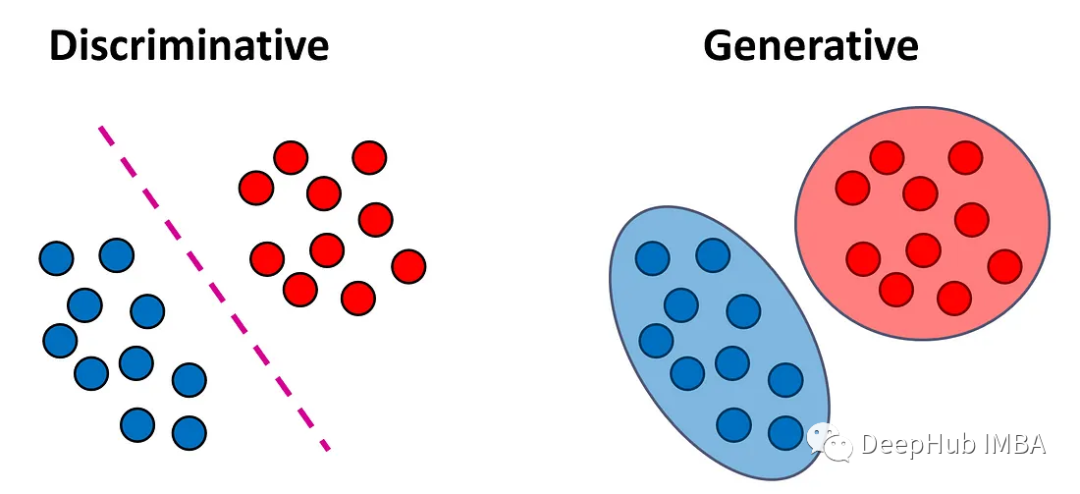
生成式模型与辨别式模型
分类模型可以分为两大类:生成式模型与辨别式模型。本文解释了这两种模型类型之间的区别,并讨论了每种方法的优缺点。

TensorFlow 决策森林详细介绍和使用说明
使用TensorFlow训练、调优、评估、解释和部署基于树的模型的完整教程
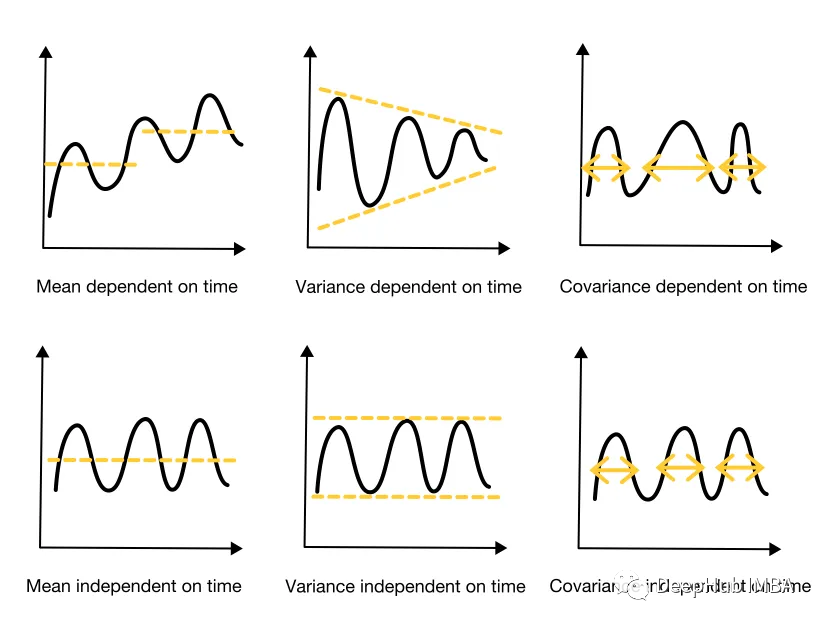
时间序列的平稳性
如何检查时间序列是否平稳,如果它是非平稳的,我们可以怎么处理
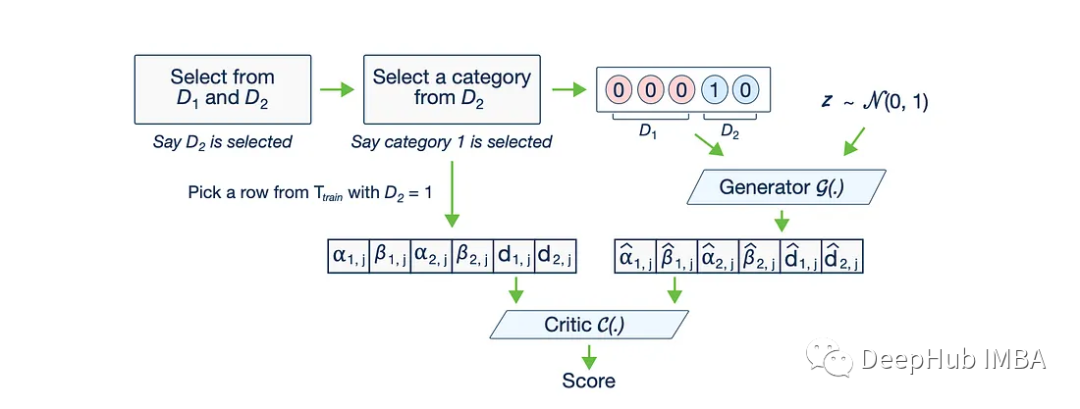
用CTGAN生成真实世界的表格数据
随着CLIP和稳定模型的快速发展,图像生成领域中GAN已经不常见了,但是在表格数据中GAN还是可以看到它的身影。
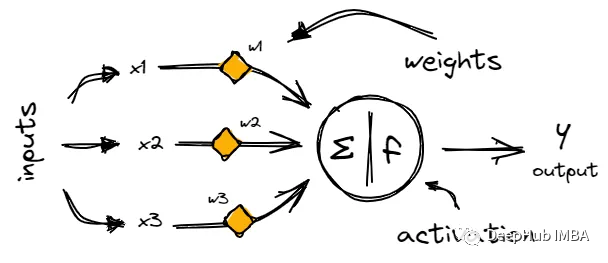
神经网络初学者的激活函数指南
如果你刚刚开始学习神经网络,激活函数的原理一开始可能很难理解。但是如果你想开发强大的神经网络,理解它们是很重要的。
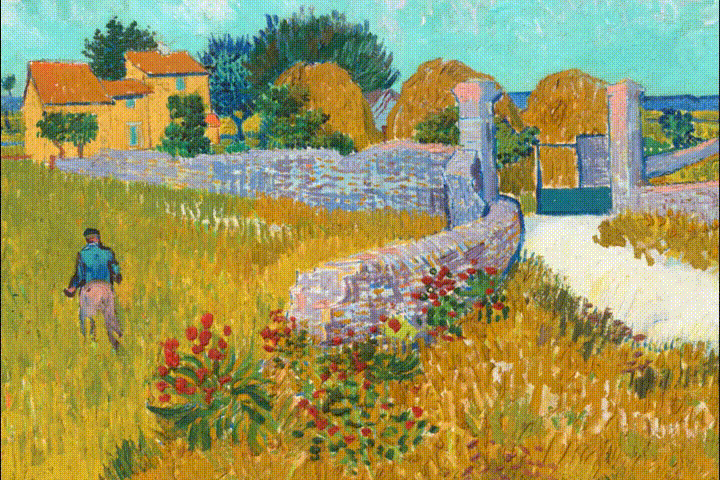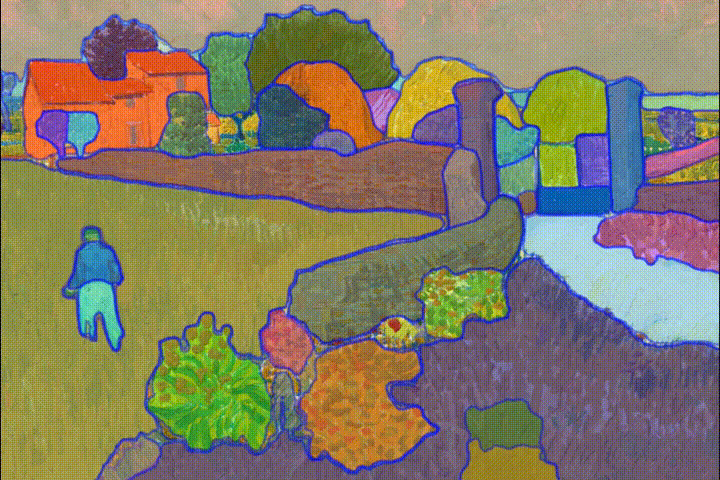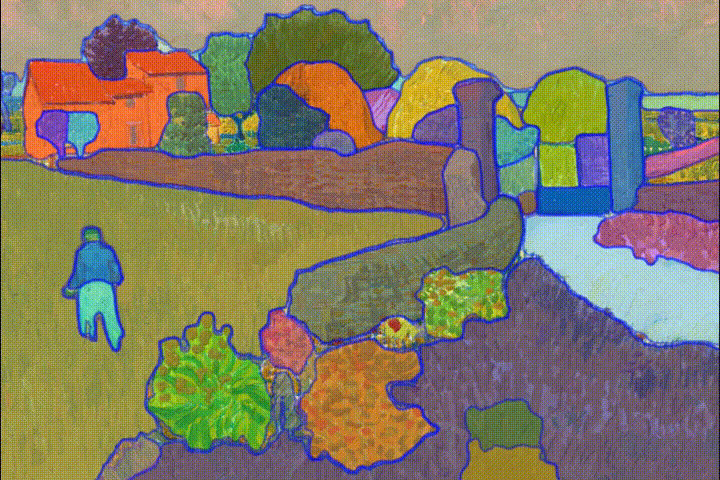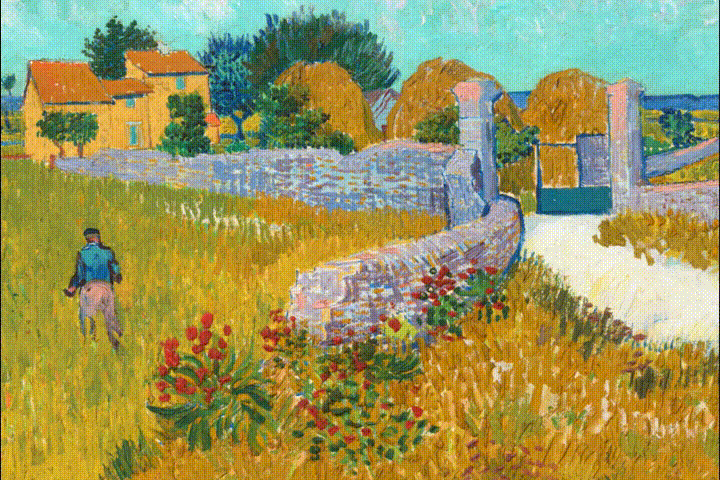
2023年4月的12篇AI论文推荐
GPT-4发布仅仅三周后,就已经随处可见了。本月的论文推荐除了GPT-4以外还包括、语言模型的应用、扩散模型、计算机视觉、视频生成、推荐系统和神经辐射场。

Pandas 2.0 vs Polars:速度的全面对比
本文将比较Pandas 2.0(使用Numpy和Pyarrow作为后端)和Polars 0.17.0的速度。并且介绍使用Polars库复现一些简单到复杂的Pandas代码,这样也算是对Polars的一个简单介绍。另外测试将在4 cpu和32 GB RAM上进行。
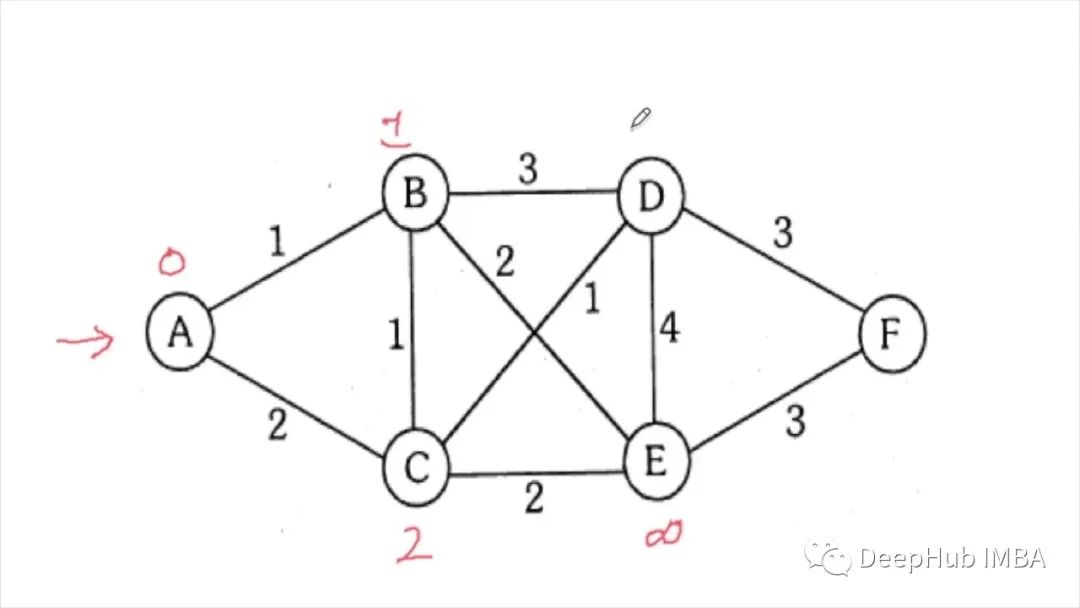
利用强化学习Q-Learning实现最短路径算法
本文中我们将尝试找出一种方法,在从目的地a移动到目的地B时尽可能减少遍历路径。我们使用自己的创建虚拟数据来提供演示,下面代码将创建虚拟的交通网格:

可视化CNN和特征图
卷积神经网络(cnn)是一种神经网络,通常用于图像分类、目标检测和其他计算机视觉任务。CNN的关键组件之一是特征图,它是通过对图像应用卷积滤波器生成的输入图像的表示。
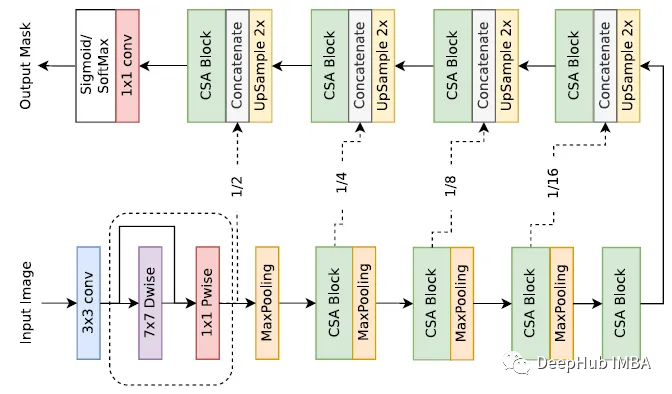
论文推荐:DCSAU-Net,更深更紧凑注意力U-Net
这是一篇23年发布的新论文,论文提出了一种更深、更紧凑的分裂注意力的U-Net,该网络基于主特征守恒和紧凑分裂注意力模块,有效地利用了底层和高层语义信息。