
Deephub
更多文章请关注公众号:Deephub-IMBA
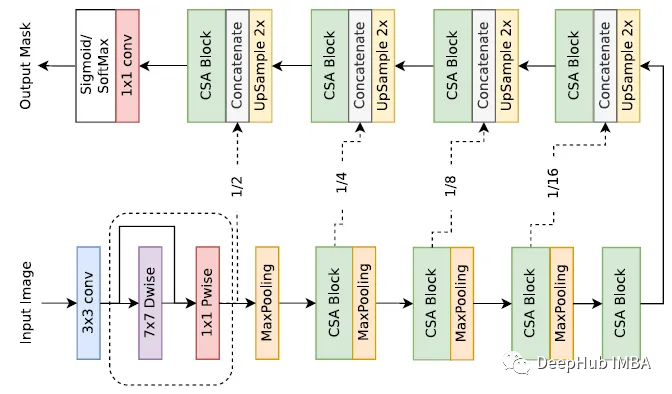
论文推荐:DCSAU-Net,更深更紧凑注意力U-Net
这是一篇23年发布的新论文,论文提出了一种更深、更紧凑的分裂注意力的U-Net,该网络基于主特征守恒和紧凑分裂注意力模块,有效地利用了底层和高层语义信息。
7个最新的时间序列分析库介绍和代码示例
所以本文将分享8个目前比较常用的,用于处理时间序列问题的Python库。他们是tsfresh, autots, darts, atspy, kats, sktime, greykite。

常用的ControlNet以及如何在Stable Diffusion WebUI中使用
ControlNet是斯坦福大学研究人员开发的Stable Diffusion的扩展,使创作者能够轻松地控制AI图像和视频中的对象

Pandas 2.0正式版发布: Pandas 1.5,Polars,Pandas 2.0 速度对比测试
这里我们将对比下 Pandas 1.5,Polars,Pandas 2.0 。看看在速度上 Pandas 2.0有没有优势。
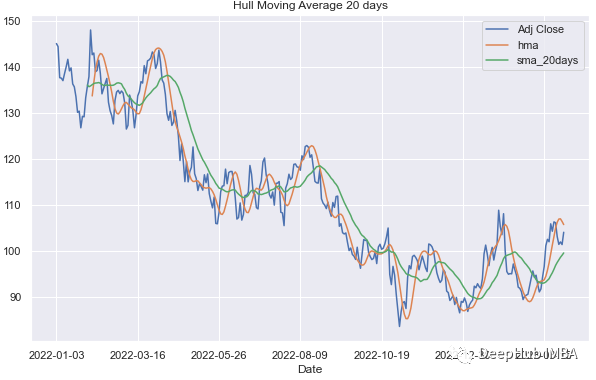
使用Python实现Hull Moving Average (HMA)
在下面的文章中,我们将介绍如何使用Python实现HMA。本文将对计算WMA的两种方法进行详细比较。然后介绍它在时间序列建模中的作用。

用遗传算法寻找迷宫出路
遗传算法是一种基于达尔文进化论的搜索启发式算法。该算法模拟了基于种群中最适合个体的自然选择。
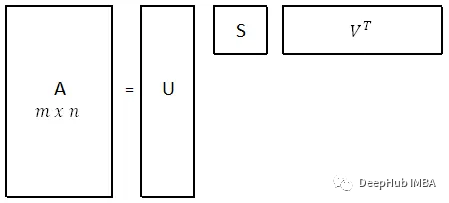
奇异值分解(SVD)和图像压缩
在本文中,我将尝试解释 SVD 背后的数学及其几何意义,还有它在数据科学中的最常见的用法,图像压缩。
这个ChatGPT插件可以远程运行代码,还生成图表
插件系统的确让ChatGPT变得有趣:“Code Interpreter”不仅可以让远程运行代码,而且还使数据科学简单,高效。

基于凸集上投影(POCS)的聚类算法
本文综述了一种基于凸集投影法的聚类算法,即基于POCS的聚类算法。原始论文发布在IWIS2022上。
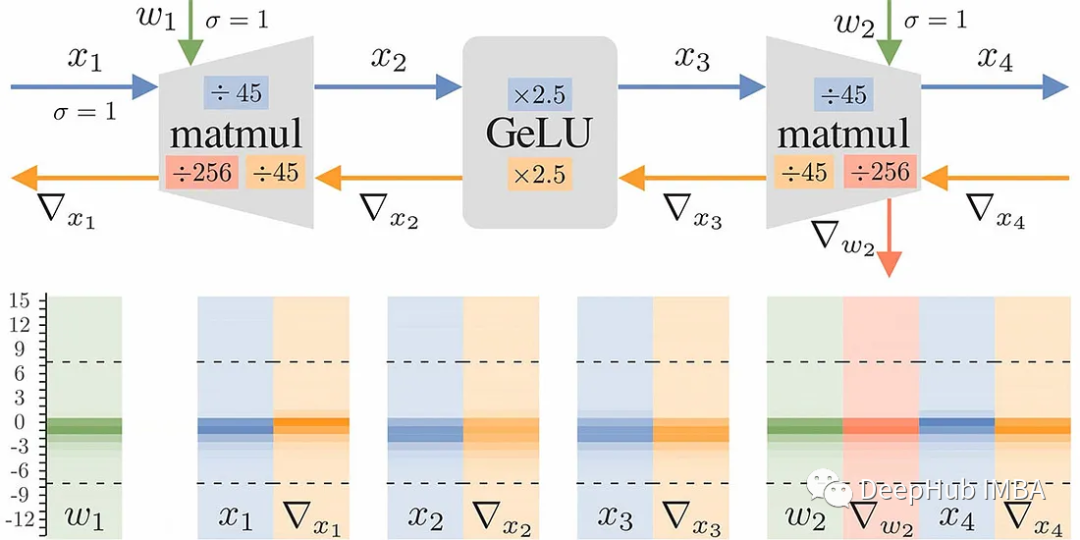
使用Unit Scaling进行FP16 和 FP8 训练
Unit Scaling 是一种新的低精度机器学习方法,能够在没有损失缩放的情况下训练 FP16 和 FP8 中的语言模型。
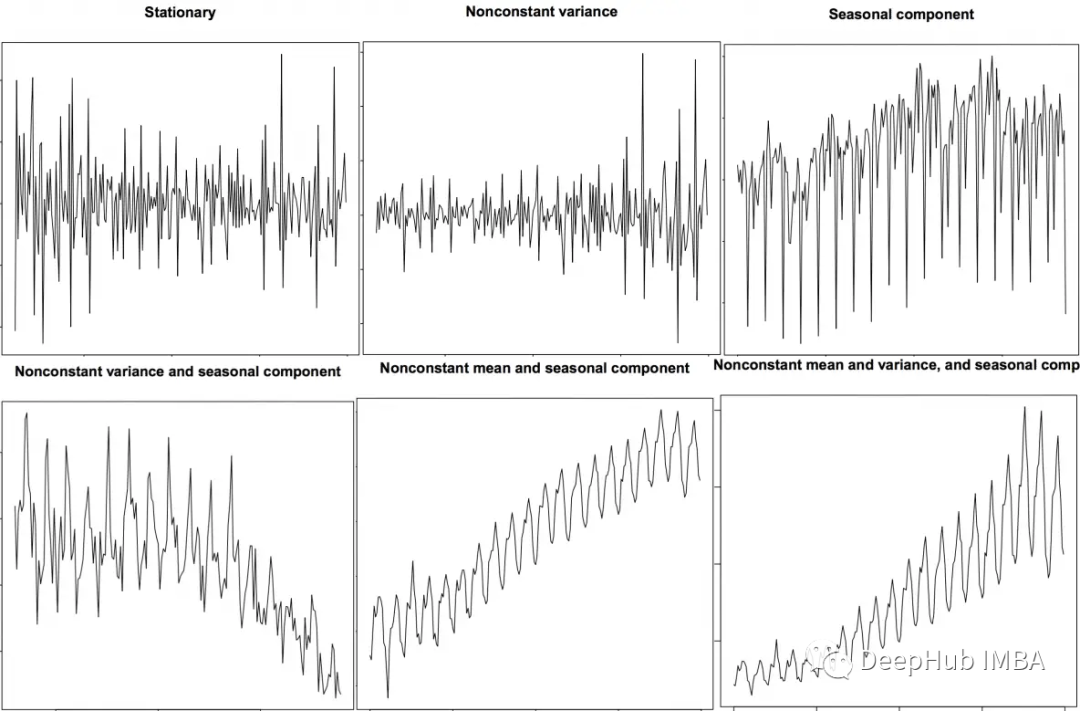
时间序列特征提取的Python和Pandas代码示例
使用Pandas和Python从时间序列数据中提取有意义的特征,包括移动平均,自相关和傅里叶变换。

扩散模型的Prompt指南:如何编写一个明确提示
Prompt(提示)是扩散模型生成图像的内容来源,构建好的提示是每一个Stable Diffusion用户需要解决的第一步。本文总结所有关于提示的内容,这样可以让你生成更准确,更好的图像
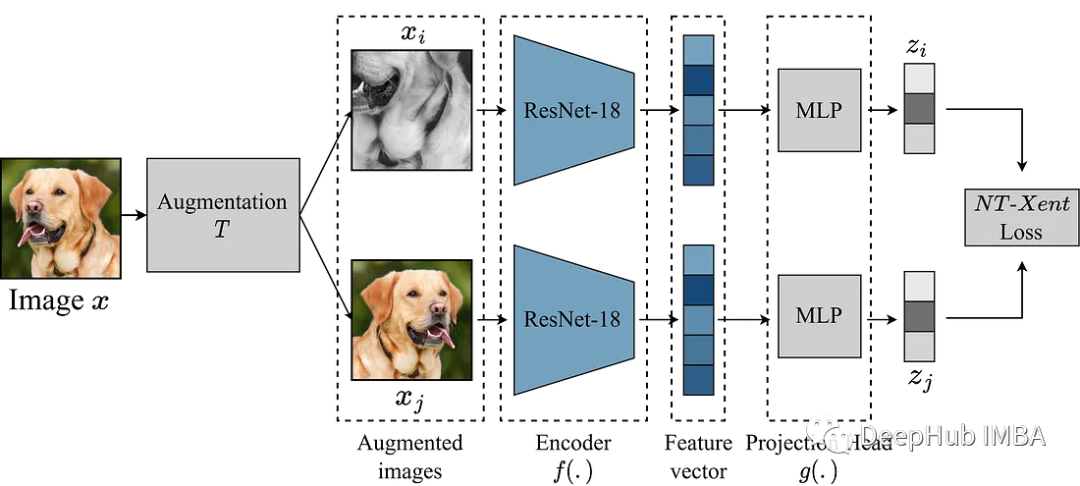
使用Pytorch实现对比学习SimCLR 进行自监督预训练
SimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。
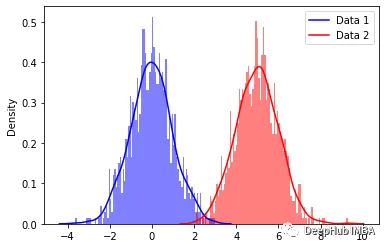
高斯混合模型 GMM 的详细解释
高斯混合模型(后面本文中将使用他的缩写 GMM)听起来很复杂,其实他的工作原理和 KMeans 非常相似,你甚至可以认为它是 KMeans 的概率版本。 这种概率特征使 GMM 可以应用于 KMeans 无法解决的许多复杂问题。

30行python代码就可以调用ChatGPT API总结论文的主要内容
使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。
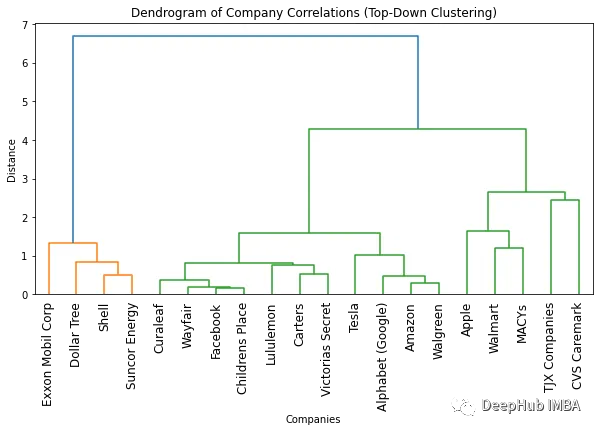
使用树状图可视化聚类
这篇文章中,我们介绍如何使用树状图(Dendrograms)对我们的聚类结果进行可视化。
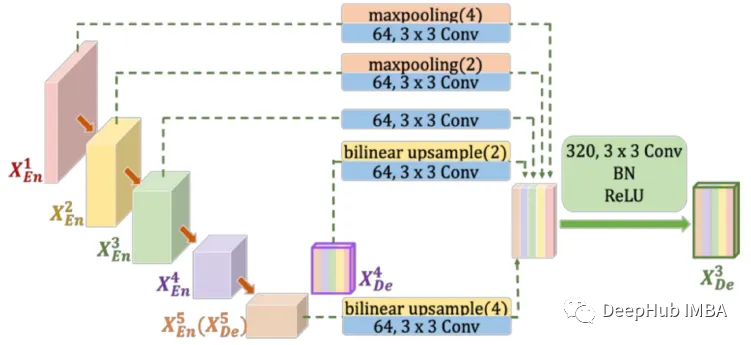
Half-UNet:用于医学图像分割的简化U-Net架构
Half-UNet简化了编码器和解码器,还使用了Ghost模块(GhostNet)。并重新设计的体系结构,把通道数进行统一。

10个Pandas的另类数据处理技巧
本文所整理的技巧与以前整理过10个Pandas的常用技巧不同,你可能并不会经常的使用它,但是有时候当你遇到一些非常棘手的问题时,这些技巧可以帮你快速解决一些不常见的问题。

Huggingface微调BART的代码示例:WMT16数据集训练新的标记进行翻译
BART模型是用来预训练seq-to-seq模型的降噪自动编码器(autoencoder)。它是一个序列到序列的模型,具有对损坏文本的双向编码器和一个从左到右的自回归解码器,所以它可以完美的执行翻译任务。
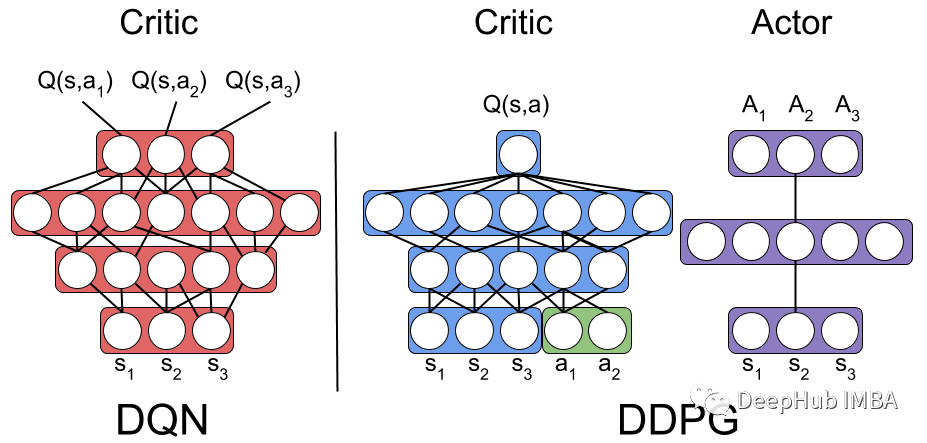
DDPG强化学习的PyTorch代码实现和逐步讲解
深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)是受Deep Q-Network启发的无模型、非策略深度强化算法,是基于使用策略梯度的Actor-Critic,本文将使用pytorch对其进行完整的实现和讲解