
如果你曾经训练过像 BERT 或 RoBERTa 这样的大型 NLP 模型,你就会知道这个过程是极其漫长的。由于其庞大的规模,训练此类模型可能会持续数天。当需要在小型设备上运行它们时,就会发现正在以巨大的内存和时间成本为日益增长的性能付出代价。
有一些方法可以减轻这些痛苦并且对模型的性能影响很小,这种技术称为蒸馏。在本文中,我们将探讨 DistilBERT [1] 方法背后的机制,该方法可用于提取任何类似 BERT 的模型。
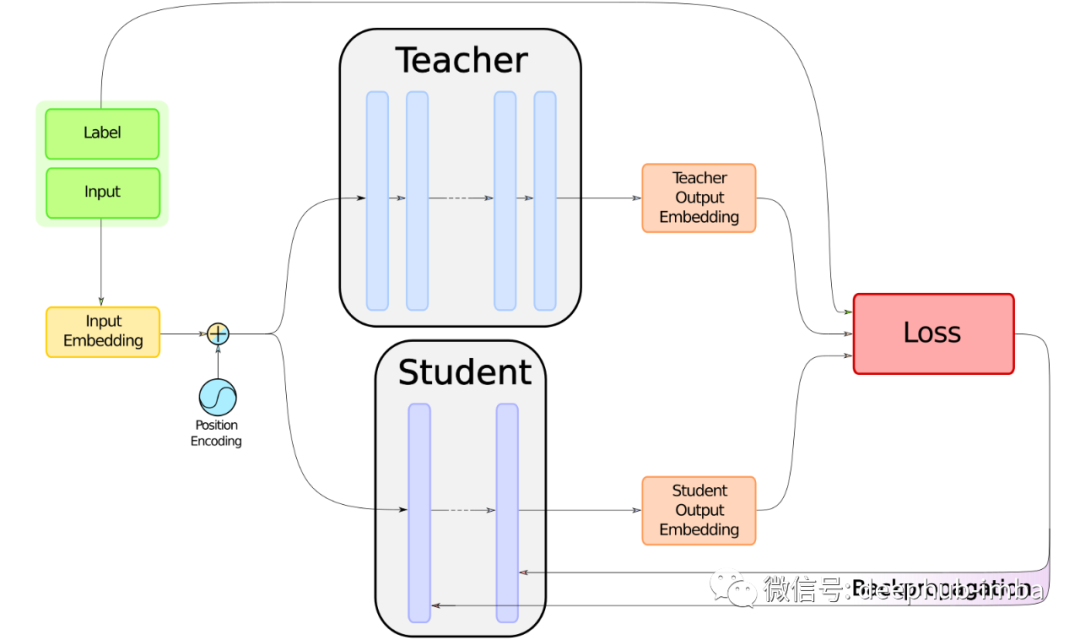
首先,我们将讨论一般的蒸馏以及我们为什么选择 DistilBERT 的方法,然后如何初始化这个过程,以及在蒸馏过程中使用的特殊损失,最后是一些需要注意的细节。
简单介绍DistilBERT
什么是知识蒸馏?
蒸馏的概念是相当直观的:它是训练一个小的学生模型,模仿一个更大的教师模型并尽可能接近的过程。如果我们只将他用在集群上进行机器学习模型的微调时,那么知识蒸馏的作用并不大。但是当我们想要将一个模型移植到更小的硬件上时,比如一台有限的笔记本电脑或手机,知识蒸馏的好处是显而易见的,因为蒸馏的模型在保证性能的情况下,参数更少、运行得更快、占用的空间更少。
BERT蒸馏的必要性
基于bert的模型在NLP中非常流行,因为它们最初是在[2]中引入的。随着性能的提高,出现了很多很多的参数。准确地说,BERT的参数超过了1.1亿,这里还没有讨论BERT-large。对知识蒸馏的需要是明显的,因为 BERT 非常通用且性能良好,还有就是后来的模型基本上以相同的方式构建,类似于 RoBERTa [3],所以能够正确的提取和使用BERT里面包含的内容可以让我们达到一举两得的目的。
DistilBERT 方法
第一篇关于 BERT 提炼的论文是给我们灵感的论文,即 [1]。但是其他方法也会陆续介绍,例如 [4] 或 [5],所以我们很自然地想知道为什么将自己限制在 DistilBERT 上。答案有三点:第一,它非常简单,是对蒸馏的一个很好的介绍;其次,它带来了良好的结果;第三,它还允许提炼其他基于 BERT 的模型。
DistilBERT 的蒸馏有两个步骤,我们将在下面详细介绍。
复制主模型(教师)的架构
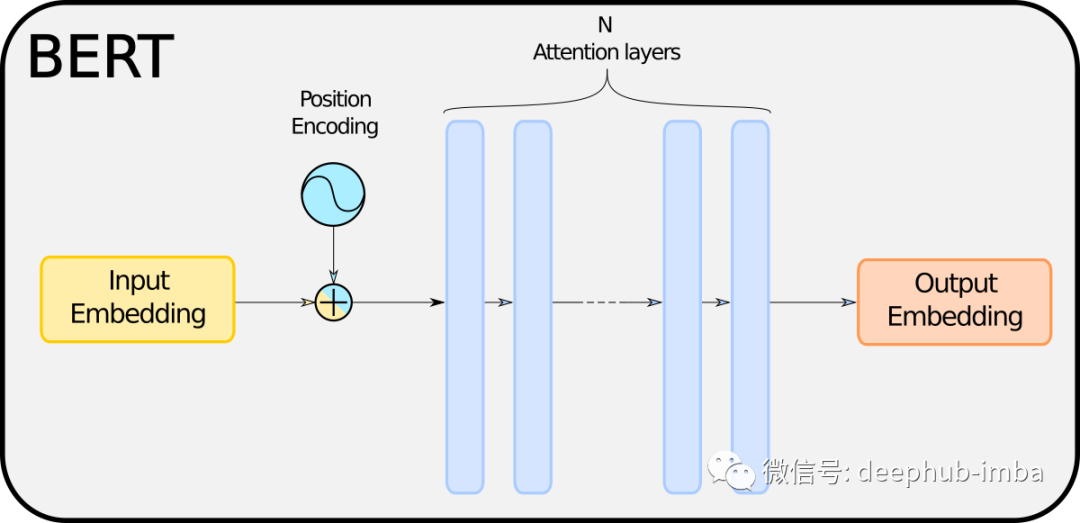
BERT 主要基于一系列相互堆叠的注意力层。因此这意味着 BERT 学习的“隐藏知识”包含在这些层中。我们不会关心这些层是如何工作的,但是对于那些想要了解更多细节的人,除了原始论文 [1],我可以推荐这篇做得非常出色的 TDS 文章 [6]。在这里我们可以将注意力层视为一个黑匣子,这对我们来说并不重要。
各个BERT模型之间的最大区别是层数 N 不同,模型的大小自然与 N 成正比。由此可知,训练模型所花费的时间和前向传播的时间也取决于 N,当然还有用于存储模型的内存。因此提取 BERT 的合乎逻辑的结论是减少 N。
DistilBERT 的方法是将层数减半并从教师的层初始化学生的层。这个方法听起来就是简单而高效的:
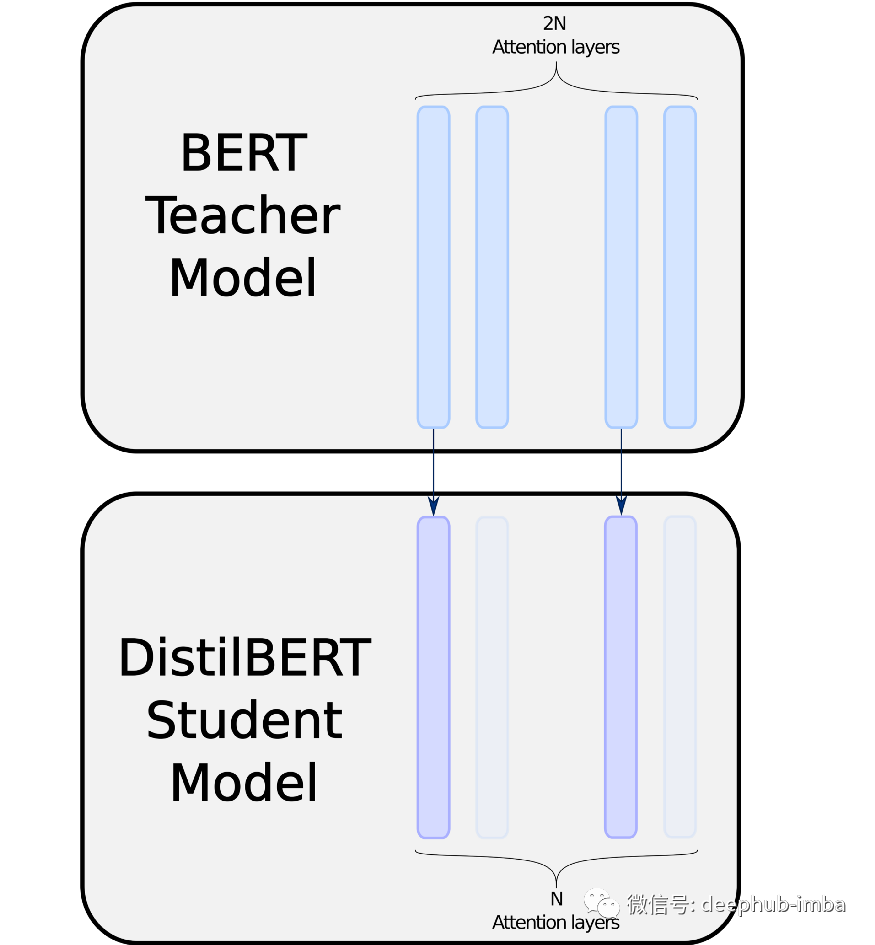
DistilBERT 在一个完全复制层和一个忽略层之间交替,根据 [4]的方法,它尝试优先复制顶层或底层。
这里还要感谢huggingface的transformers 模块,再加上和对BERT其内部工作原理的一些了解,这个复制的步骤可以很容易地实现。我们将在另一篇文章中展示如何具体做到,因为我们在本文中只研究理论和机制。
当然,如果使用基于 BERT 的模型进行特定任务,比如说时间序列分类,那么还需要为学生模型复制教师模型的头部,但一般来说BERT 的头部大小与其注意力层的大小相比就显得非常的小了,可以忽略不计。
我们现在有一个可以用来学习的学生模型。但是蒸馏过程并不是一个经典的拟合过程:我们不是像往常一样教学生模型学习一种模式,我们的目标是模仿教师。因此我们将不得不调整训练过程,尤其是我们的损失函数。
蒸馏的损失
本文顶部的图像说明了蒸馏过程。我们的训练程序将基于实现以下两个目标的特定损失:将与教师模型训练时相同的损失函数最小化、模仿教师模型的输出。所以知识蒸馏的最大问题就是,模仿教师模型需要将两个损失函数混合。下面我们将从简单的目标开始,尽量减少与教师模型相同的损失。
教师模型相同的损失
关于这部分没有什么可说的:类似 BERT 的模型都以相同的方式工作,核心将嵌入输出到解决特定问题的头部。教师微调的任务带有自己的损失函数。为了计算这个损失,由于学生模型是与教师具有相同问题特定头部的注意力层组成,所以我们只需要输入学生的嵌入和标签。
学生-教师交叉熵损失
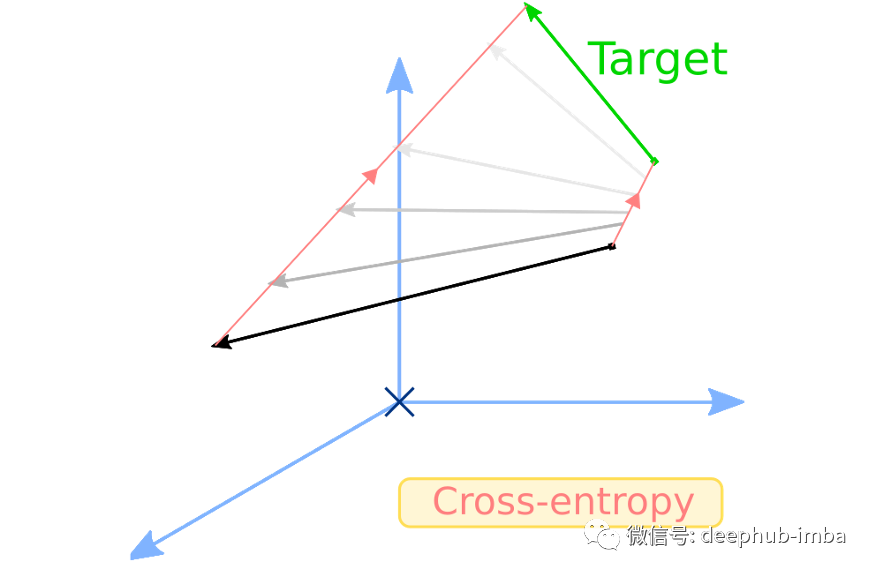
这是第一个能够缩小学生和教师模型概率分布之间差距的损失。当类 BERT 模型对输入进行前向传播时,无论是用于掩码语言建模、标记分类、序列分类等……它都会输出 logits,然后通过 softmax 层将其转换为概率分布。
对于输入 x,教师模型输出:
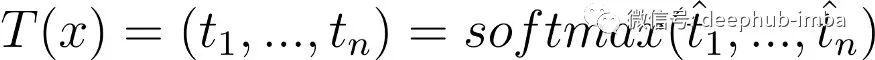
学生模型输出:
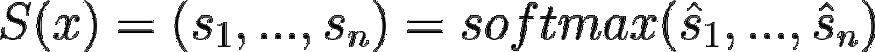
请记住softmax 及其附带的符号,我们后面还会继续讨论。如果我们希望 T 和 S 接近,可以以 T 为目标对 S 应用交叉熵损失。这就是我们所说的学生-教师交叉熵损失:
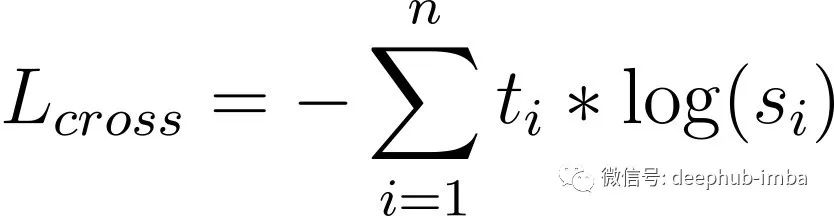
学生-教师余弦损失
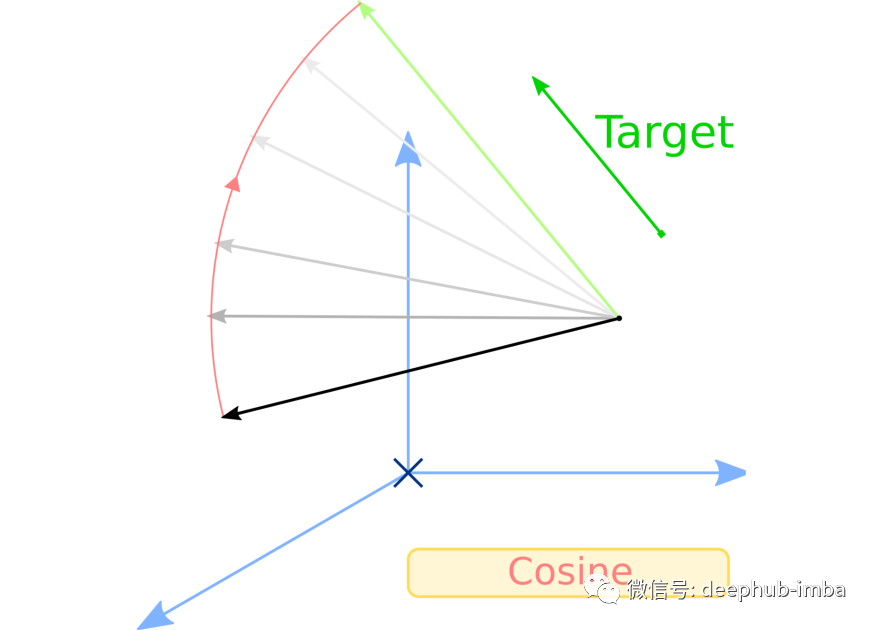
帮助学生模仿教师的第二个损失是余弦损失。余弦损失很有趣因为它不尝试使向量 x 等于目标 y,而是尝试将 x 与 y 对齐,并且不考虑它们各自的范数或空间原点。我们使用这种损失可以使教师和学生模型中的隐藏向量对齐。公式表示如下:
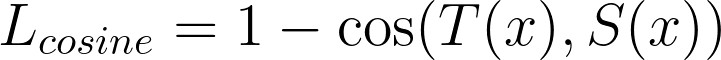
实际上,余弦损失有两种版本,一种用于对齐向量,另一种是将一个向量拉向另一个相反的方向。在本文中,我们只对第一种方法感兴趣。
蒸馏使用完整损失
全部蒸馏的损失是上述三种损失的整合:

额外细节
蒸馏过程
在解释了损失之后,蒸馏程序的其余部分非常简单。该模型的训练与其他模型非常相似,唯一的问题是必须并行运行两个BERT 的模型(学生、教师)。但是幸运的是教师模型不需要梯度,因为反向传播仅在学生身上完成。但是作为蒸馏过程,仍然需要实现损失的计算,我们将在以后的文章中介绍它。
Temperature
在学生-教师交叉熵损失时我们提到的这个符号:
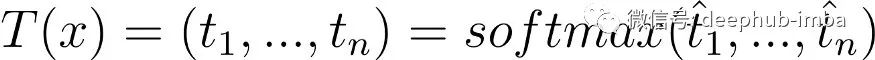
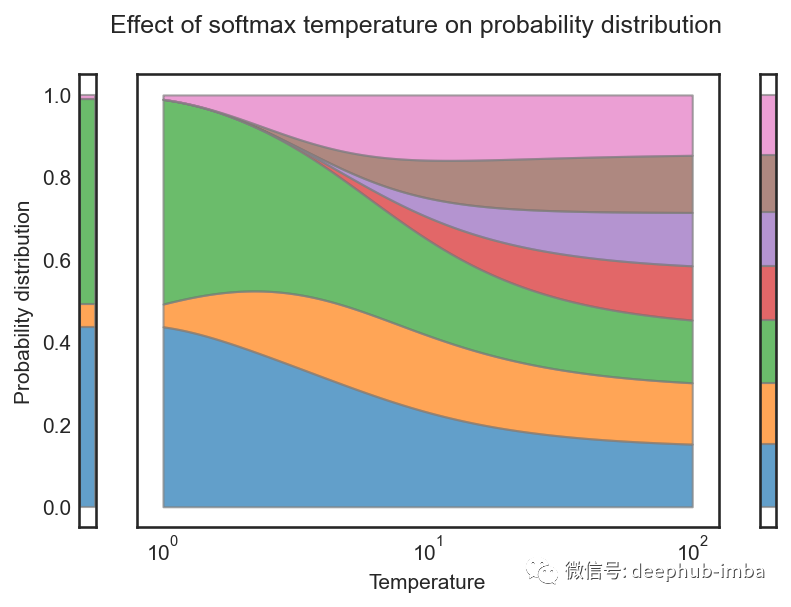
DistilBERT 使用 [7] 中的Temperature概念,这有助于软化 softmax。Temperature是一个 θ ≥ 1变量,它会随着 softmax 的上升而降低“置信度”。正常的 softmax 描述如下:
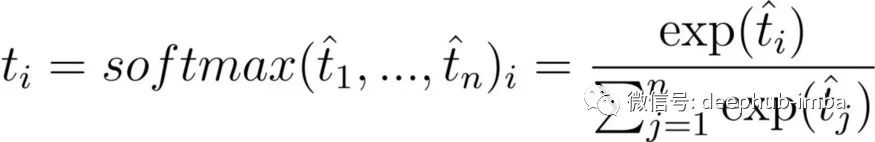
现在,让我们将其重写为:
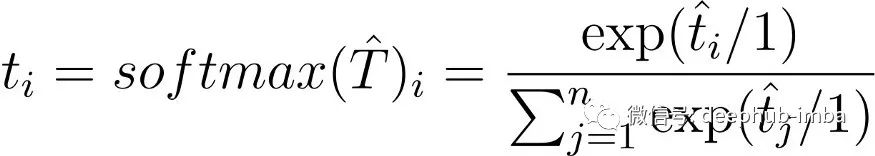
公式中的 1实际上对应于θ。一个普通的 softmax 是一个Temperature设置为 1 的 softmax,一个包含Temperature的 softmax 的公式是:
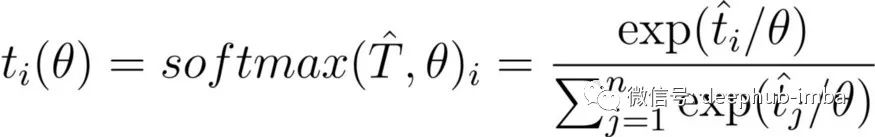
随着 θ 上升,θ 上的商变为零,因此整个商变为 1/n,softmax 概率分布变为均匀分布。这可以在上图中观察到。
在 DistilBERT 中,学生和教师模型的 softmax 在训练时都以相同的θ 为条件,并在推理时将Temperature设置为 1。
总结
以上就是 DistilBERT 对类 BERT 模型的蒸馏过程,唯一要做的就是选择一个模型并提炼它!我们在后面的文章中将详细介绍蒸馏的过程和代码实现。
引用
[1] Victor SANH, Lysandre DEBUT, Julien CHAUMOND, Thomas WOLF, DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (2019), Hugging Face
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018), Google AI Language
[3] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, RoBERTa: A Robustly Optimized BERT Pretraining Approach (2019), arXiv
[4] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu, TinyBERT: Distilling BERT for Natural Language Understanding (2019), arXiv
[5] Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou, MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (2020), arXiv
[6] Raimi Karim, Illustrated: Self-Attention (2019), Towards Data Science
[7] Geoffrey Hinton, Oriol Vinyals, Jeff Dean, Distilling the Knowledge in a Neural Network (2015), arXiv
作者:Remi Ouazan Reboul