
Deephub
更多文章请关注公众号:Deephub-IMBA
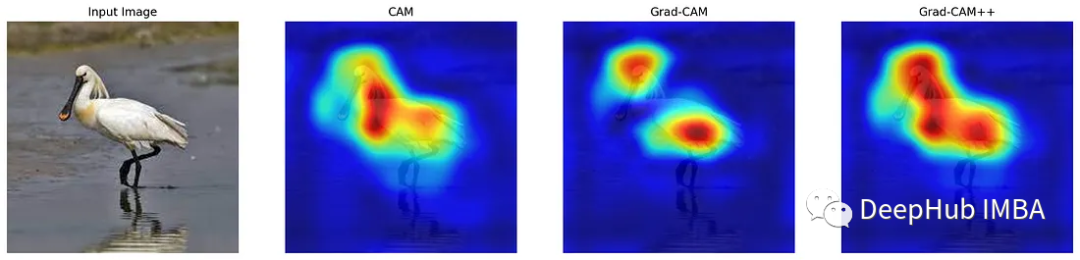
CAM, Grad-CAM, Grad-CAM++可视化CNN方式的代码实现和对比
理解CNN的方法主要有类激活图(Class Activation Maps, CAM)、梯度加权类激活图(Gradient Weighted Class Activation Mapping, Grad-CAM)和优化的 Grad-CAM( Grad-CAM++)。
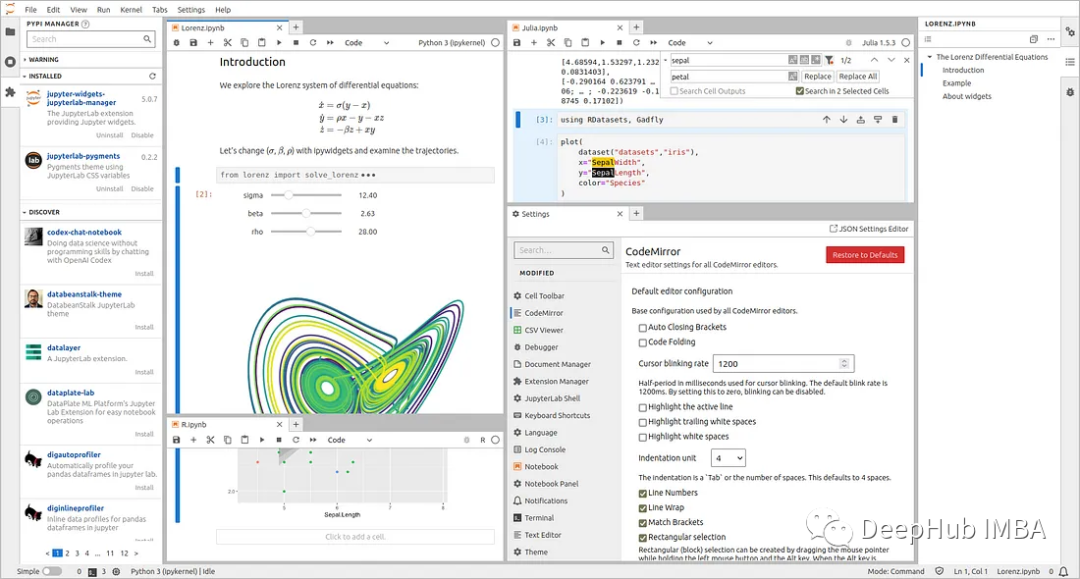
JupyterLab 4.0 发布了
JupyterLab 是 Jupyter Notebook 的下一代版本,它提供了更强大的功能和更灵活的用户界面,6月6日,官方发布了JupyterLab 4.0的说明,并且说该版本是下一个主要的版本。

使用Optuna进行PyTorch模型的超参数调优
Optuna是一个开源的超参数优化框架,Optuna与框架无关,可以在任何机器学习或深度学习框架中使用它。本文将以表格数据为例,使用Optuna对PyTorch模型进行超参数调优。

Python中的Time和DateTime
Python在处理与时间相关的操作时有两个重要模块:time和datetime。在本文中,我们介绍这两个模块并为每个场景提供带有代码和输出的说明性示例。

设置和使用DragGAN:搭建非官方的演示版
DragGAN的官方版还没有发布,但是已经有非官方版的实现了,我们看看如何使用。DragGAN不仅让GAN重新回到竞争轨道上,而且为GAN图像处理开辟了新的可能性。

七篇深入理解机器学习和深度学习的读物推荐
在这篇文章中将介绍7篇机器学习和深度学习的论文或者图书出版物,这些内容都论文极大地影响了我对该领域的理解,如果你想深入了解机器学习的内容,哪么推荐阅读。
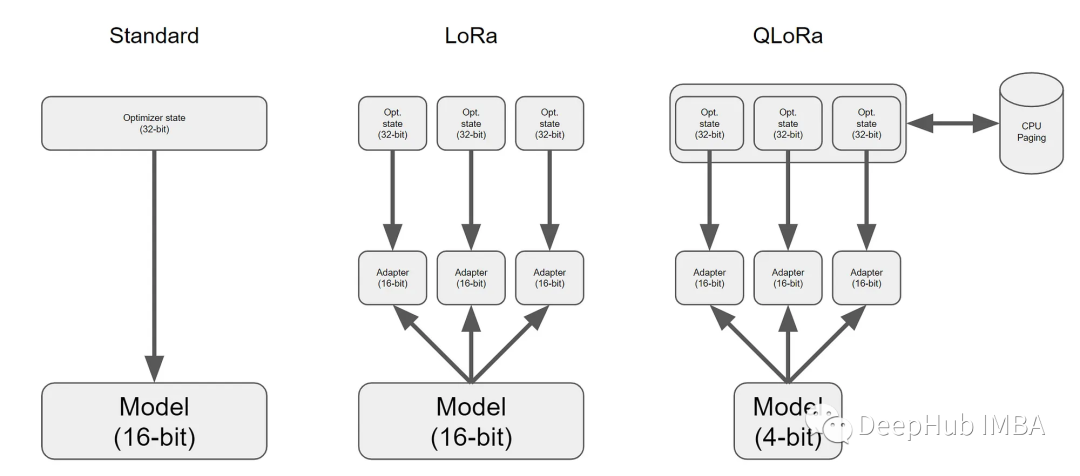
QLoRa:在消费级GPU上微调大型语言模型
LoRa让我们的微调变得简单,而QLoRa可以让我们使用消费级的GPU对具有10亿个参数的模型进行微调,

这8个NumPy函数可以解决90%的常见问题
NumPy是一个用于科学计算和数据分析的Python库,也是机器学习的支柱。
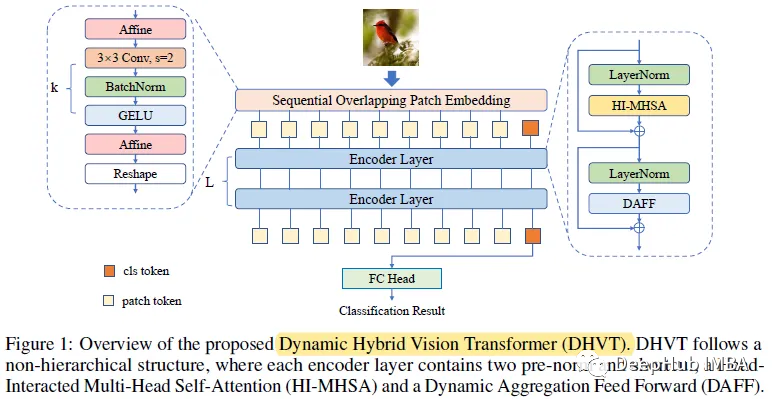
DHVT:在小数据集上降低VIT与卷积神经网络之间差距,解决从零开始训练的问题
VIT在归纳偏置方面存在空间相关性和信道表示的多样性两大缺陷。所以论文提出了动态混合视觉变压器(DHVT)来增强这两种感应偏差。
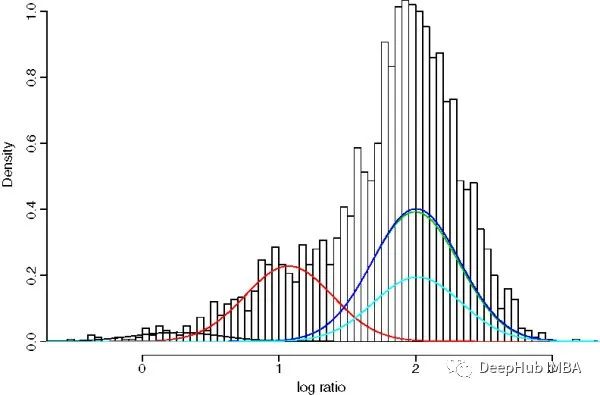
基于GMM的一维时序数据平滑算法
在本文中探讨GMM作为时间数据平滑算法的使用。GMM(Gaussian Mixture Model)是一种统计模型,常用于数据聚类和密度估计,但也可以在一定程度上用作时间数据平滑算法。
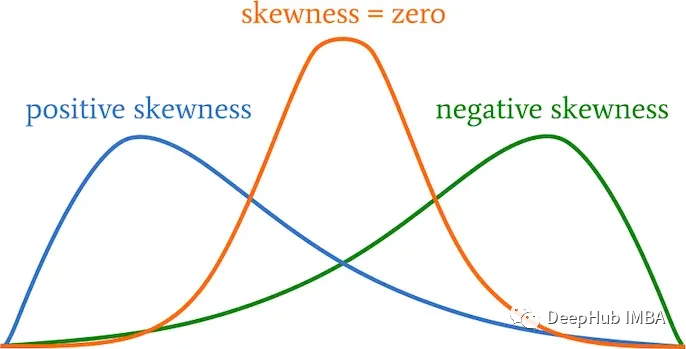
数据偏度介绍和处理方法
偏度(skewness)是用来衡量概率分布或数据集中不对称程度的统计量。
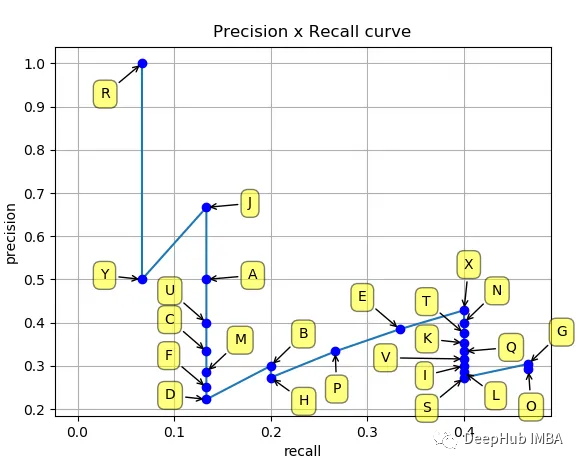
深入了解平均精度(mAP):通过精确率-召回率曲线评估目标检测性能
平均精度(Average Precision,mAP)是一种常用的用于评估目标检测模型性能的指标。

Scikit-LLM:将大语言模型整合进Sklearn的工作流
我们以前介绍过Pandas和ChaGPT整合,这样可以不了解Pandas的情况下对DataFrame进行操作。现在又有人开源了Scikit-LLM,它结合了强大的语言模型,如ChatGPT和scikit-learn。

PyTorch-Forecasting一个新的时间序列预测库
PyTorch- forecasting是一个建立在PyTorch之上的开源Python包
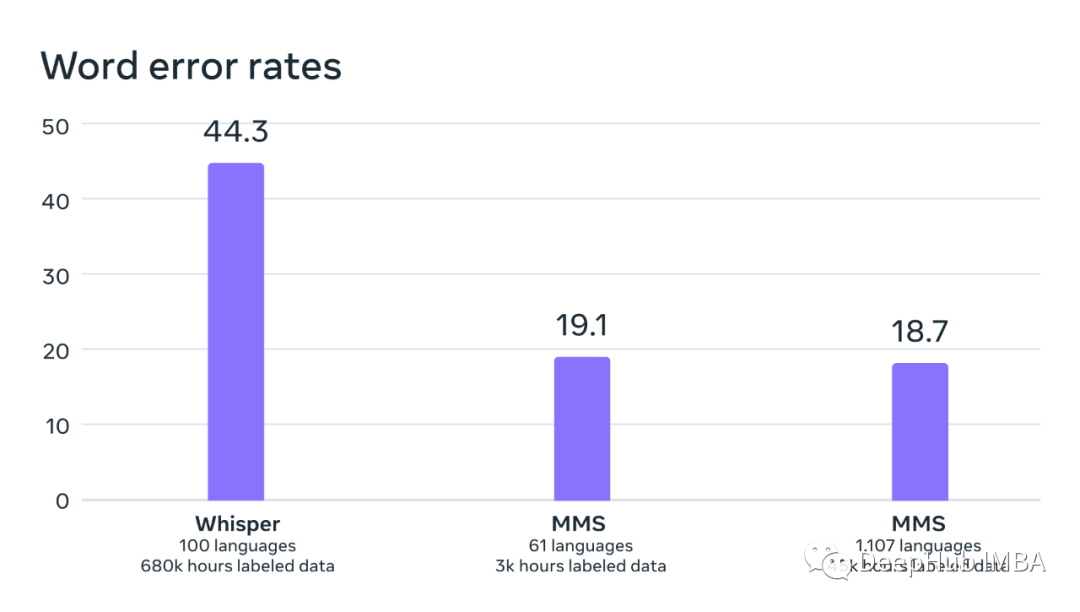
Meta 开源语音 AI 模型支持 1,100 多种语言
本周一Meta 又开源了新的语音模型MMS,并且发布了支持1100种语言的预训练模型权重

Jupyter Notebook 10个提升体验的高级技巧
Jupyter 笔记本是数据科学家和分析师用于交互式计算、数据可视化和协作的工具。在这篇文章中,我将介绍10个可以提升体验的高级技巧。

升级到PyTorch 2.0的技巧总结
PyTorch 2.0 通过引入 torch.compile,可以显着提高训练和推理速度。我们将演示这个新功能的使用,以及介绍在使用它时可能遇到的一些问题。

计算GMAC和GFLOPS
GMAC 代表“Giga Multiply-Add Operations per Second”(每秒千兆乘法累加运算),是用于衡量深度学习模型计算效率的指标。它表示每秒在模型中执行的乘法累加运算的数量,以每秒十亿 (giga) 表示。

NSFW 图片分类
NSFW指的是不适宜工作场所("Not Safe (or Suitable) For Work;")。在本文中,将介绍如何创建一个检测NSFW图像的图像分类模型。

常用的视频帧提取工具和方法总结
视频理解任务最基础也是最主要的预处理任务是图像帧的提取。因为在视频理解任务中,视频可以看作是由一系列连续的图像帧组成的。