
多年来,深度学习一直在不断发展。深度学习实践高度强调使用大量参数来提取有关我们正在处理的数据集的有用信息。通过拥有大量参数,我们可以更容易地分类/检测某些东西,因为我们有更多的可以清楚地识别的数据。
目前为止深度学习中,特别是在自然语言处理领域的一个显着里程碑是语言模型的引入,它极大地提高了执行各种 NLP 任务的准确性和效率。
seq2seq模型是一种基于编码器-解码器机制的模型,它接收输入序列并返回输出序列作为结果。例如图像描述任务,输入给定的图像,输出则是为图像创建一个合理的描述。在这种情况下seq2seq 模型将图像像素向量(序列)作为输入,并逐字返回描述(序列)作为输出。
一些促进此类模型训练的重要 DL 算法包括RNN,LSTM,GRU。但随着时间的推移这些算法的使用逐渐消失,因为复杂性和一些缺点会随着数据集大小的增加而严重影响性能。这其中的重要的缺点包括较长的训练时间、梯度消失问题(当我们为大型数据集进一步训练模型时会丢失有关旧数据的信息)、算法的复杂性等。
Attention is all you need
在语言模型训练方面取代上述所有算法的爆发性概念之一是基于多头注意力的Transformer 架构。Transformer 架构最早是由谷歌在 2017 年的论文《Attention is all you need》中引入的。它受欢迎的主要原因是其架构引入了并行化。Transformer 利用了强大的 TPU 和并行训练,从而减少了训练时间。
以下是被传播最广泛的Transformer架构的可视化。
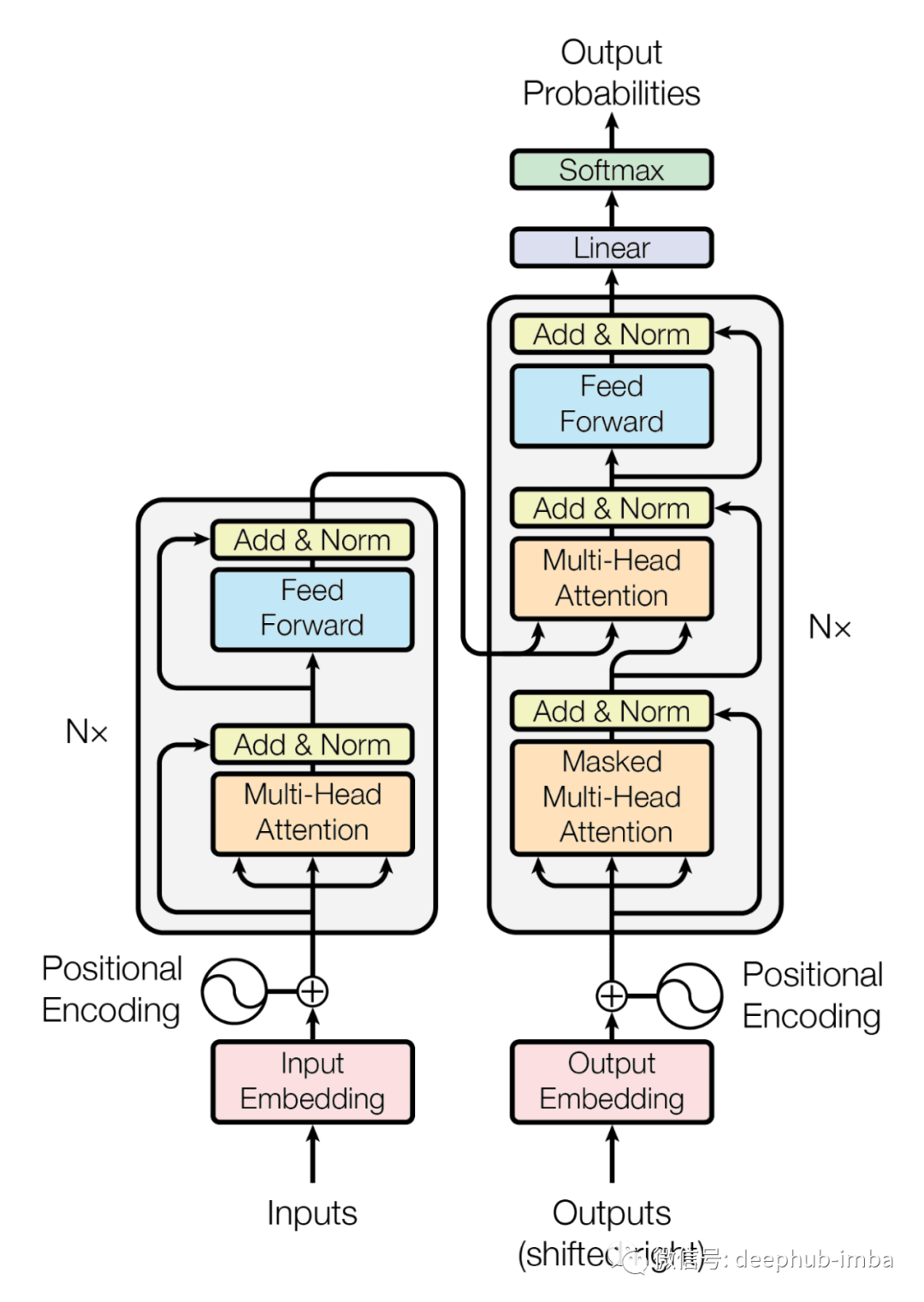
即使抽象了很多的细节,整个架构看起来还是非常庞大。这张图中每一层仍然隐藏着很多细节东西。我们在这篇文章中会介绍每一层以及它在整个架构中的作用。
Transformer 是一个用于 seq2seq 模型的编码器-解码器模型,左侧是输入,右侧是输出。在 它内部使用的注意机制已成为语言模型的首要算法。
现在我们开始详细介绍每一层的作用。我们将使用带有简单句子“I am a student”及其法语翻译形式“Je suis étudiant”的语言翻译任务示例。
Embedding layer
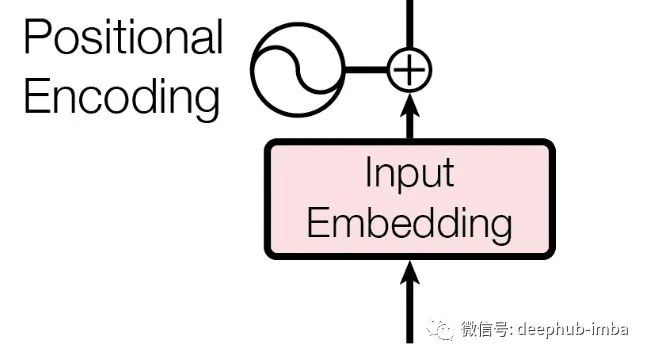
输入嵌入是Transformer 编码器和解码器的第一步。机器无法理解任何语言的单词,它只能识别数字。所以我们通过这一层得到了输入/输出中每个单词的嵌入,这些嵌入使用 GloVe 等方法很容易获得。对于这个嵌入值,我们在句子中添加该词的位置信息(基于奇数或偶数位置出现的不同值)以提供上下文信息。
Multi-Head Attention
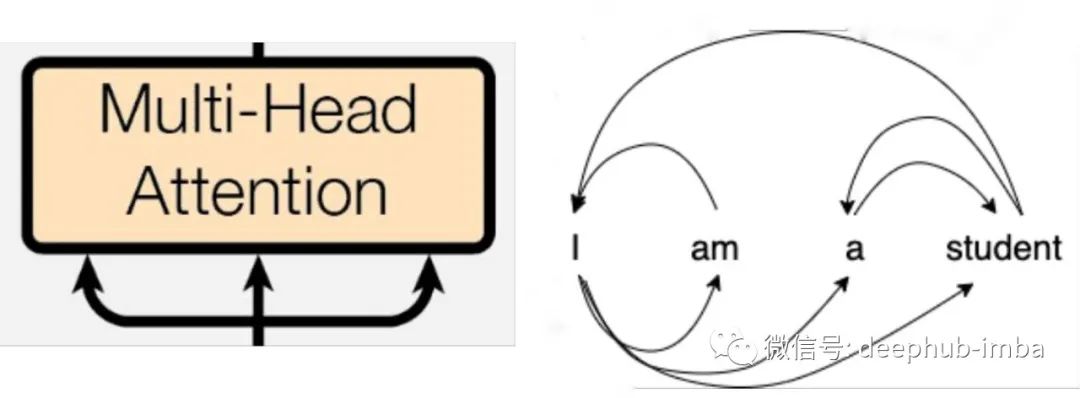
多头注意力层由组合在一起的多个自注意力层组成。注意力层的主要目的是收集有关句子中每个单词与其他单词的相关性的信息,这样可以获得其在句子中的含义。上图描述了我们句子中的每个单词如何依赖其他单词来提供含义。但要让机器理解这种依赖性和相关性并不是那么容易。
在我们的注意力层中,我们采用三个输入向量,即查询(Q)、键(K)和值(V)。简单的说:查询就像在浏览器上搜索的内容,浏览器会返回一组要匹配的页面它们就是是键,而我们得到真正需要的结果是值。对于句子中的给定词(Q),对于它中的其他词(K),我们得到它(V)对另一个词的相关性和依赖性。这种自我注意过程使用 Q、K 和 V 的不同权重矩阵进行了多次激素按。因此就是多头注意层,作为多头注意力层的结果,我们得到了多个注意力矩阵。
在架构中,我们可以看到解码器中还有另外两个注意力层。
Masked multi-head attention
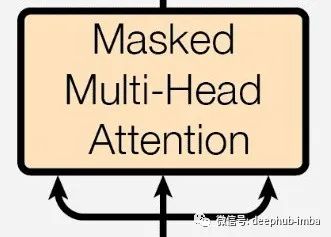
这是我们解码器端的第一层注意力。但为什么它是Masked attention?
在输出的情况下,如果当前单词可以访问它之后的所有单词,那么它不会学到任何东西。它会直接继续并建议输出这个词。但是通过掩蔽我们可以隐藏当前单词之后的单词,它将有空间来预测到目前为止对给定单词和句子来说什么单词是有意义的。它已经有了当前单词的嵌入和位置信息,所以我们使用它之前使用 Q、K 和 V 向量看到的所有单词让它变得有意义并找出最可能的下一个单词。
Encoder-Decoder attention
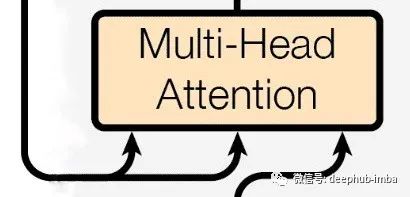
解码器端的下一个多头注意力层从编码器端获取两个输入(K,V),从解码器的前一个注意力层获取另一个(Q),它可以访问来自输入和输出的注意力值。基于来自输入和输出的当前注意力信息,它在两种语言之间进行交互并学习输入句子中每个单词与输出句子之间的关系。
Residual layer
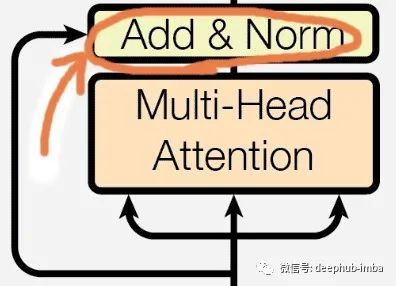
这些注意力层将返回一组注意力矩阵,这些矩阵将与实际输入进行合并,并且将执行层/批量标准化。这种归一化有助于平滑损失,因此在使用更大的学习率时很容易优化
Feed Forward Layer
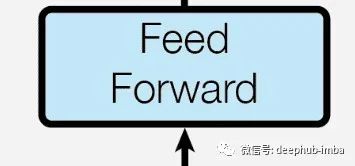
在编码器块中前馈网络是一个简单的模块,它取出平均的注意力值并将它们转换为下一层更容易处理的形式。它可以是顶部的另一个编码器层,也可以传递到解码器端的编码器-解码器注意力层。
在解码器块中,我们还有另一个前馈网络,它执行相同的工作并将转换后的注意力值传递到顶部的下一个解码器层或线性层。
Transformer 的一个主要的特征就发生在这一层, 与传统的RNN不同,由于每个单词都可以通过其注意力值独立地通过神经网络,因此这一层是并行化激素按的。我们可以同时传递输入句子中的所有单词,编码器可以并行处理所有单词并给出编码器输出。
Output
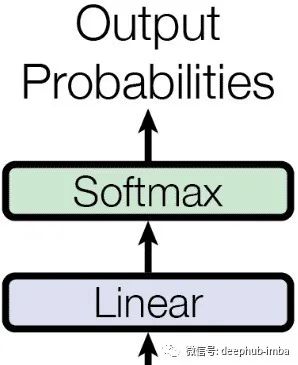
在所有解码器端处理完成后,数据就被传送到带有线性层和 softmax 层的输出处理层。线性层用于将来自神经网络的注意力值扁平化,然后应用 softmax 来找到所有单词的概率,从中我们得到最可能的单词, 模型其实就是预测下一个可能的单词作为解码器层输出的概率。
整体总结
现在让我们快速浏览一下整个过程。
编码器Encoder
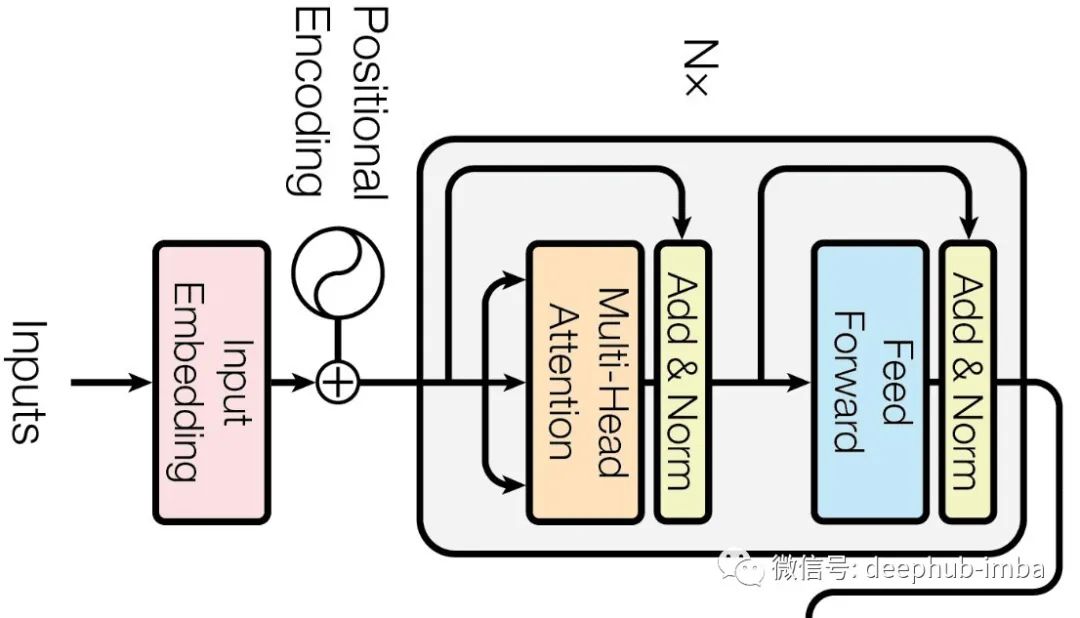
将输入句子中的每个单词并行传递。采用词嵌入并添加位置信息以提供上下文。然后有多头注意力层它学习与其他单词的相关性,从而产生多个注意力向量。然后将这些向量平均化并应用归一化层以简化优化。这些向量又被传递到前馈网络,该网络将值转换为下一个编码器或编码器-解码器注意力层可读的维度。
解码器Decoder
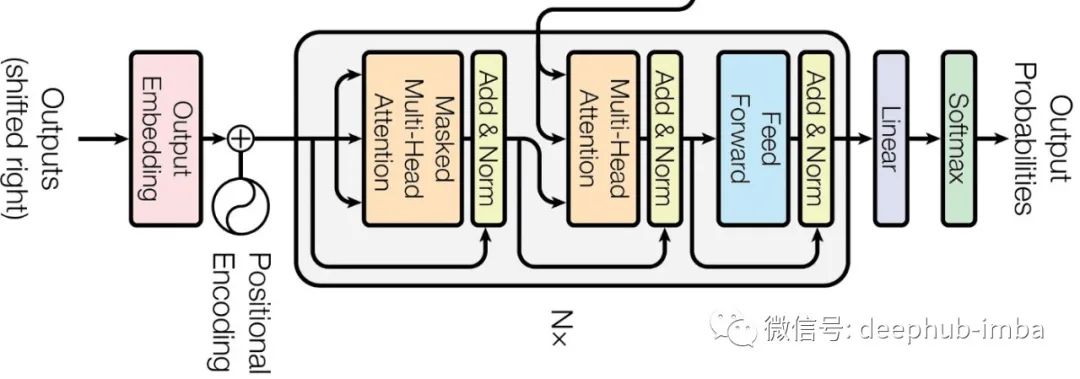
首先是一个类似的词嵌入和添加上下文的预处理步骤。然后通过一个带有掩蔽的注意力层,它可以学习输出句子的当前单词和它之前看到的所有单词之间的注意力并且不允许即将出现的单词。然后通过残差连接的加和归一化层进行归一化操作,将编码器层的输出作为键、值向量到下一个注意层,解码器下一层将使用的注意力的值(V)作为查询(Q)。输入和输出语言之间的在这里进行了实际交互,这样使得算法更好地理解语言翻译。
最后是另一个前馈网络,它将转换后的输出传递到一个线性层,使注意力值变扁平,然后通过softmax层来获取输出语言中所有单词下一次出现的概率。概率最高的单词将成为输出。
编码器和解码器的堆叠
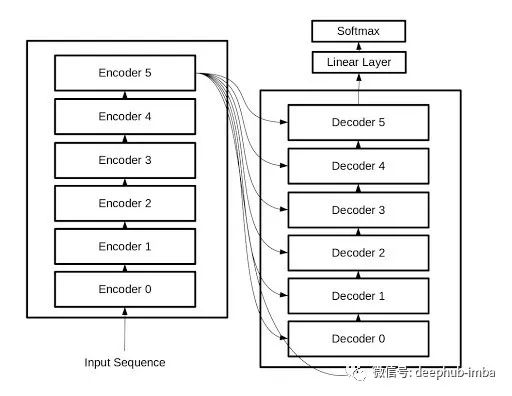
堆叠编码器和解码器也很有效,因为它可以更好地学习任务并提高算法的预测能力。在实际论文中,Google 堆叠了 6 个编码器和解码器。但也要确保它不会过度拟合并使训练过程变得昂贵。
最后总结
自从 Google 推出 Transformers 以来,它在 NLP 领域就一直是革命性的。它被用于开发各种语言模型,包括备受赞誉的 BERT、GPT2 和 GPT3,在所有语言任务中都优于以前的模型。了解基础架构肯定会让你在游戏中处于领先地位。
感谢您阅读本文!我希望这篇文章能让你对 Transformer 的整体架构有所了解。
作者:Logeshvar L