
什么是BERT?
BERT(Bidirectional Encoder Representations from Transformers)在各种自然语言处理任务中提供了最前沿的结果在深度学习社区引起了轰动。德夫林等人。2018 年在 Google 使用英文维基百科和 BookCorpus 开发了 BERT,从那时起,类似的架构被修改并用于各种 NLP 应用程序。XL.net 是建立在 BERT 之上的示例之一,它在 20 种不同任务上的表现优于 BERT。在理解基于 BERT 构建的不同模型之前,我们需要更好地了解 Transformer 和注意力模型。
BERT 的基本技术突破是使用双向训练的 Transformer 和注意力模型来执行语言建模。与早期从左到右或双向训练相结合的文本序列的研究相比,BERT 论文的发现表明,双向训练的语言模型可以更好地理解语言上下文。
BERT 使用注意力机制以及学习单词之间上下文关系的Transformer 。Transformer 由两个独立的部分组成 - 编码器和解码器。编码器读取输入文本,解码器为任务生成预测。与顺序读取输入文本的传统定向模型相比,transformer 的编码器一次读取整个单词序列。由于 BERT 的这种特殊结构,它可以用于许多文本分类任务、主题建模、文本摘要和问答。
在本文中,我们将尝试微调用于文本分类的 BERT 模型,使用 IMDB 电影评论数据集检测电影评论的情绪。
BERT 目前有两种可用的变体:
- BERT Base:12层,12个注意力头,768个隐藏和110M参数
- BERT Large:24 层,16 个注意力头,1024 隐藏和 340M 参数
以下是 Devlin 等人的 BERT 架构图。
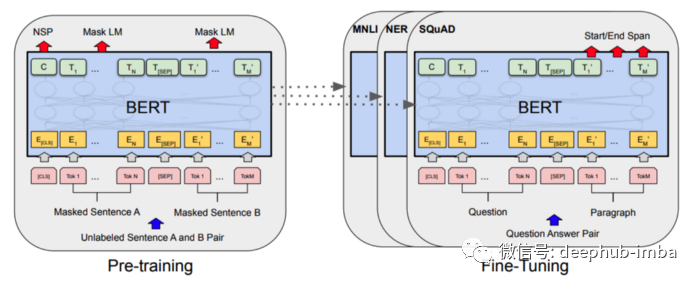
我们已经快速了解了什么是BERT ,下面开始对 BERT 模型进行微调以进行情感分析。我们将使用 IMDB 电影评论数据集来完成这项任务。
微调前准备
首先,我们需要从 Hugging Face 安装Transformer 库。
pip install transformers
现在让我们导入我们在整个实现过程中需要的所有库。
from transformers import BertTokenizer, TFBertForSequenceClassification
from transformers import InputExample, InputFeatures
import numpy as np
import pandas as pd
import tensorflow as tf
import os
import shutil
我们需要导入 BERT 的预训练分词器和序列分类器以及输入模块。
model = TFBertForSequenceClassification.from_pretrained("bert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
有很多方法可以对文本序列进行向量化,例如使用词袋 (BoW)、TF-IDF、Keras 的 Tokenizers 等。在这个实现中,我们将使用预训练的“bert-base-uncase”标记器类.
让我们看看分词器是如何工作的。
example = 'This is a blog post on how to do sentiment analysis with BERT'
tokens = tokenizer.tokenize(example)
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(tokens)
print(token_ids)
--Output--
['this', 'is', 'a', 'blog', 'post', 'on', 'how', 'to', 'do', 'sentiment', 'analysis', 'with', 'bert']
[2023, 2003, 1037, 9927, 2695, 2006, 2129, 2000, 2079, 15792, 4106, 2007, 14324]
由于 BERT 词汇表的大小固定为 30K 个标记,因此词汇表中不存在的词将表示为子词和字符。分词器检查输入的句子并决定是否将每个单词作为一个完整的单词保留,将其拆分为子单词或将其分解为个别字符作为补充。通过分词器总是可以将一个单词表示为其组成字符的集合。
我们将使用预训练的“bert-base-uncased”模型和序列分类器进行微调。为了更好地理解,让我们看看模型是如何构建的。
model.summary()
--Output--
Model: "tf_bert_for_sequence_classification"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (TFBertMainLayer) multiple 109482240
_________________________________________________________________
dropout_37 (Dropout) multiple 0
_________________________________________________________________
classifier (Dense) multiple 1538
=================================================================
Total params: 109,483,778
Trainable params: 109,483,778
Non-trainable params: 0
我们的主要 BERT 模型由一个用于防止过度拟合的 dropout 层和一个用于实现分类任务的密集层组成。
读取数据
dataset = pd.read_csv("IMDB Dataset.csv")
dataset.head()
--Output--
review | sentiment
0 |One of the other reviewers has mentioned that ... | positive
1 |A wonderful little production. <br /><br />The... | positive
2 |I thought this was a wonderful way to spend ti... | positive
3 |Basically there's a family where a little boy ... | negative
4 |Petter Mattei's "Love in the Time of Money" is... | positive
从上面的输出中可以看出,数据集的情绪使用正面和负面标签进行了注释。因此,我们需要将标签更改为数值。
def convert2num(value):
if value=='positive':
return 1
else:
return 0
df['sentiment'] = df['sentiment'].apply(convert2num)
train = df[:45000]
test = df[45000:]
数据预处理
使用 BERT 训练模型时,需要完成一些额外的预处理任务。
添加特殊令牌:
[SEP] - 标记句子的结尾
[CLS] - 为了让 BERT 理解我们正在做一个分类,我们在每个句子的开头添加这个标记
[PAD] - 用于填充的特殊标记
[UNK] - 当分词器无法理解句子中表示的单词时,我们将包含此标记而不是单词
引入填充 - 等长传递序列
创建注意力掩码 - 1(真实标记)和 0(填充标记)的数组
微调模型
创建输入序列
使用InputExample函数,我们可以将df转换为适合 BERT 模型的对象。为了做到这一点,我将创建两个函数。一个函数将接受训练和测试数据集作为输入并将每一行转换为 InputExample 对象,另一个函数将标记 InputExample 对象。
def convert2inputexamples(train, test, review, sentiment):
trainexamples = train.apply(lambda x:InputExample(
guid=None, text_a = x[review],
label = x[sentiment]), axis = 1) validexamples = test.apply(lambda x: InputExample(
guid=None, text_a = x[review],
label = x[sentiment]), axis = 1)
return trainexamples, validexamplestrainexamples, validexamples = convert2inputexamples(train, test, 'review', 'sentiment')
从上面的函数可以看出,它将训练和测试数据集作为输入,并将数据集的每一行转换为 InputExamples。
def convertexamples2tf(examples, tokenizer, max_length=128):
features = []
for i in tqdm(examples):
input_dict = tokenizer.encode_plus(
i.text_a,
add_special_tokens=True, # Add 'CLS' and 'SEP'
max_length=max_length, # truncates if len(s) > max_length
return_token_type_ids=True,
return_attention_mask=True,
pad_to_max_length=True, # pads to the right by default # CHECK THIS for pad_to_max_length
truncation=True
)
input_ids, token_type_ids, attention_mask = (input_dict["input_ids"],input_dict["token_type_ids"], input_dict['attention_mask'])
features.append(InputFeatures( input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, label=i.label) )
def generate():
for f in features:
yield (
{
"input_ids": f.input_ids,
"attention_mask": f.attention_mask,
"token_type_ids": f.token_type_ids,
},
f.label,
)
return tf.data.Dataset.from_generator(
generate,
({"input_ids": tf.int32, "attention_mask": tf.int32, "token_type_ids": tf.int32}, tf.int64),
(
{
"input_ids": tf.TensorShape([None]),
"attention_mask": tf.TensorShape([None]),
"token_type_ids": tf.TensorShape([None]),
},
tf.TensorShape([]),
),
)
DATA_COLUMN = 'review'
LABEL_COLUMN = 'sentiment'
上面的函数将转换后的输入 Example 对象作为输入,它将标记化和重新格式化输入以适合提供给模型。
train_data = convertexamples2tf(list(trainexamples), tokenizer)
train_data = train_data.shuffle(100).batch(32).repeat(2)
validation_data = convertexamples2tf(list(validexamples), tokenizer)
validation_data = validation_data.batch(32)
上面的代码片已经将转换后的 InputExample 传递给了我们之前创建的函数。执行此过程最多可能需要 2-3 分钟。
现在我们的数据集被处理成输入序列,我们可以使用处理过的数据来提供我们的模型。
训练微调BERT模型
在开始训练模型之前,请确保已启用 GPU 运行时加速。否则,训练模型可能需要一些时间。
model.compile(optimizer=tf.keras.optimizers.Adam(
learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=[tf.keras.metrics.SparseCategoricalAccuracy('accuracy')])
model.fit(train_data, epochs=2, validation_data=validation_data)
上面的代码使用 Adam 作为优化器使用 Categorical Cross Entropy 作为损失函数,因为我们只有两个标签,而且这个函数可以量化两个概率分布之间的差异,并且使用稀疏分类准确度计算模型的准确度。
训练完成后,我们可以继续预测电影评论的情绪。
预测情绪
我创建了一个包含两个评论的列表,一个是正面的,第二个是负面的。
sentences = ['This was a good movie. I would watch it again', 'I cannot believe I have wasted time on this movie, it is the worst movie I have ever seen']
在我们将上述句子列表应用到模型中之前,我们需要使用 BERT Tokenizer 对评论进行标记。在对句子列表进行分词后,我们输入模型并运行 softmax 来预测情绪。为了确定预测情绪的极性,我们将使用 argmax 函数将情绪正确分类为“负面”或“正面”标签。
tokenized_sentences = tokenizer(sentences, max_length=128, padding=True, truncation=True, return_tensors='tf')
outputs = model(tokenized_sentences)
predictions = tf.nn.softmax(outputs[0], axis=-1)
labels = ['Negative','Positive']
label = tf.argmax(predictions, axis=1)
label = label.numpy()
for i in range(len(sentences)):
print(sentences[i], ": ", labels[label[i]])
--Output--
This was a good movie. I would watch it again : Positive
I cannot believe I have wasted time on this movie, it is the worst movie I have ever seen : Negative
从上面的预测中可以看出,我们已经成功地微调了基于 Transformer 的预训练 BERT 模型来预测电影评论的情绪。
总结
这就是这篇关于使用 IMDB 电影评论数据集微调预训练 BERT 模型以预测给定评论的情绪的文章的全部内容。如果您对其他微调技术有兴趣,请参考 Hugging Face 的 BERT 文档。
作者:Ashish Kumar Singh