
对半监督学习的新研究表明,较少标记的数据实际上使机器学习算法更强大
我过去一直认为数据本质上是自然和有序的——可以随时处理这种整齐打包好的信息。我想大多数没有体验过现实世界混乱的人都会赞同这个观点,但专业人士(或者任何使用过数据的人)都知道数据更加流动和无规则,很少有天生就是结构化并带有一个很好的标签的数据。实际上:“数据大多数时候都是未标记的、非结构化的和混乱的”。
当今广泛使用的大多数机器学习算法在很大程度上依赖于标记数据和完全监督的算法。数据科学家和数据工程师花费大量时间和精力来对抗熵并生成这些我们已经习惯在 Kaggle 等网站上看到的干净数据集。
CMU 和 Google Brain 的这篇论文证明,带有故意噪声注入的半监督方法可能比任何监督学习方法更好,即使使用的标记数据要少得多。
半监督学习
监督学习需要大量标记数据,而半监督学习 (SSL) 是一种不同的方法,它结合了无监督学习和监督学习以利用各自的优势。下面是一个被称为“域相关数据过滤”的SSL的一个可能的过程:
- 在标记数据 (X) 和真实标签 (Y) 上训练模型 (M)。
- 计算误差。
- 将 M 应用于未标记数据 (X') 以“预测”标签 (Y')。
- 从 (2) 中取出任何高置信度的猜测,并将它们从 X' 移到 X。
- 重复上述的步骤
随着时间的推移,通过以上的步骤标记数据集的大小也会增长,并为模型提供相当多的数据来处理。未标记的数据比标记的数据更便宜且更丰富,但不能保证 SSL 是一个好的解决方案。然而一项新的研究表明,可以通过改进和增加额外的工作流程提高 SSL 的性能。
如果我告诉你最新研究的 SSL方法几乎只用一小部分必要的标记数据就胜过监督学习,你会怎么想?
无监督数据增强 (UDA)
如果你的孩子完全从你告诉他们的内容中学习,那么他们很可能会在很多情况下完全失去方向。机器学习算法也是如此,为算法提供难以处理的数据可以让它们在以后变得更加健壮。这些“棘手的数据”也可以称为“噪声”。在CMU 和 Google Brain 团队的这篇新论文中表明,加强机器学习算法的一个真正有用的技术是故意向数据中添加噪声(论文中称为“噪声注入”或“数据增强”),除此以外论文还提出了一个关心“噪声质量”的新 SSL 框架。这是框架模型的总体流程图:
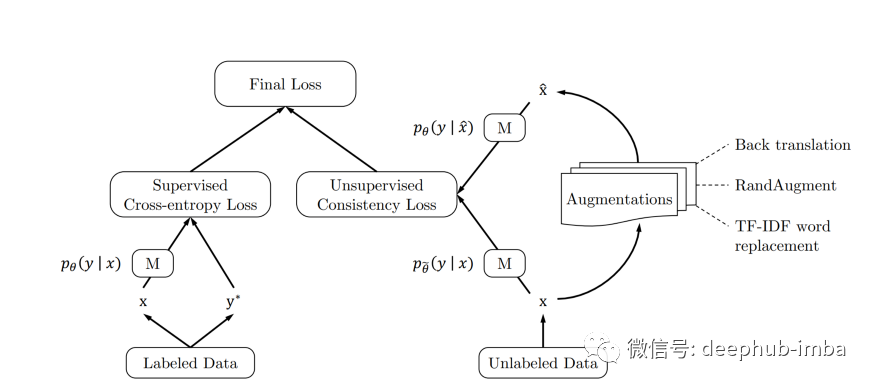
以下是上面流程图的步骤分解:
- 在标记数据 (X) 和真实标签 (Y) 上训练模型 (M)。
- 计算监督误差。
- 将 M 应用于未标记数据 (X') 以“预测”标签 (Y')。
- 以“巧妙”的方式将噪声引入 X' 以产生 X''。
- 将 M 应用于未标记的扰动数据 (X'') 以“预测”标签 (Y'')。
- 通过比较 Y' 和 Y'' 计算无监督误差。
- 使用 (2) 和 (6) 计算总误差。
- 取 (3) 中的任何高置信度猜测,并将它们从 X' 移到 X。
- 重复上述步骤
在上述步骤过程中的(4)有很多方法可以实现。其中一种有趣的方法被称为反向翻译。考虑以下句子:
“Labeled data is not as cheap as unlabeled data and therefore is a relic of the past.”
我可以将这句话转换成另一种语言,然后再转换回英语。这是我使用其他语言作为中间体时的结果。
“Marked data is not as cheap as unmarked data and is therefore a thing of the past.”
现在我们添加了噪音。细微的变化,但对算法来说却是天壤之别。
结果与标记数据的困境
前面提到的论文对上一节中概述的方法进行了压力测试。在文本分类数据集上使用谷歌的 BERT(Large)模型,结果如下:
+ — — — — + — — — — — — — — + — — — — — — — — — — — +
| Dataset | Supervised Error | Semi-Supervised Error |
+ — — — — + — — — — — — — — + — — — — — — — — — — — +
| IMDb | 4.51 (n = 20k) | 4.78 (n = 20) |
| Yelp-2 | 1.89 (n = 560k) | 2.50 (n = 20) |
| Yelp-5 | 29.32 (n = 650k) | 33.54(n = 2.5k) |
| Amazon-2| 2.63 (n = 3.6m) | 3.93 (n = 20) |
| Amazon-5| 34.17 (n = 3.0m) | 37.80(n = 2.5k) |
| DBpedia | 0.64 (n = 560k) | 1.09 (n = 140) |
+ — — — — + — — — — — — — — + — — — — — — — — — — — +
这些结果表明,这种特殊的 SSL 方法对一小部分标记数据的效果几乎与监督方法对所有标记数据的效果一样好!
至于标记数据的用处——如果标记数据可用,你就直接使用它。但是有了这方面的尝试并取得了良好的结果,任何创建整齐有序、结构化、标记数据集的理由都可能会被替代,特别是因为未标记数据广泛可用且极其便宜(计算、时间和努力方面)。未来是不可预测的(并且没有标记),但我们正在慢慢获得捕捉它所需的工具!
论文地址:
Unsupervised Data Augmentation for Consistency Training