
Deephub
更多文章请关注公众号:Deephub-IMBA

循环编码:时间序列中周期性特征的一种常用编码方式
在深度学习或神经网络中,"循环编码"(Cyclical Encoding)是一种编码技术,其特点是能够捕捉输入或特征中的周期性或循环模式。
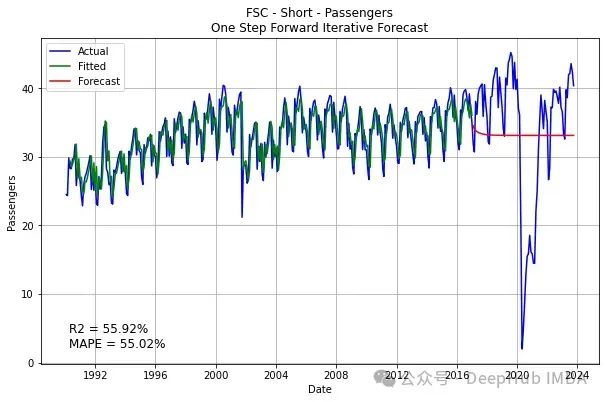
LSTM时间序列预测中的一个常见错误以及如何修正
当使用LSTM进行时间序列预测时,人们容易陷入一个常见的陷阱。
LLM2Vec介绍和将Llama 3转换为嵌入模型代码示例
通过LLM2Vec,我们可以使用LLM作为文本嵌入模型。但是简单地从llm中提取的嵌入模型往往表现不如常规嵌入模型
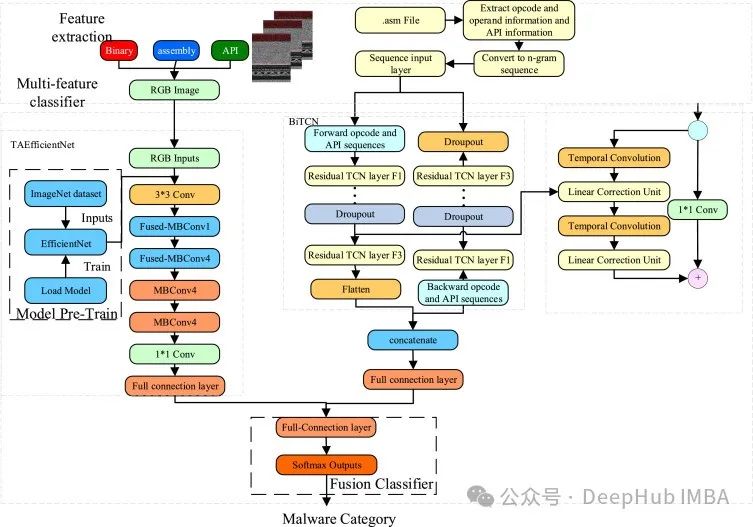
BiTCN:基于卷积网络的多元时间序列预测
在本文中,我们将详细介绍了BiTCN,提出的模型。通过利用两个时间卷积网络(TCN),该模型可以编码过去和未来的协变量,同时保持计算效率。
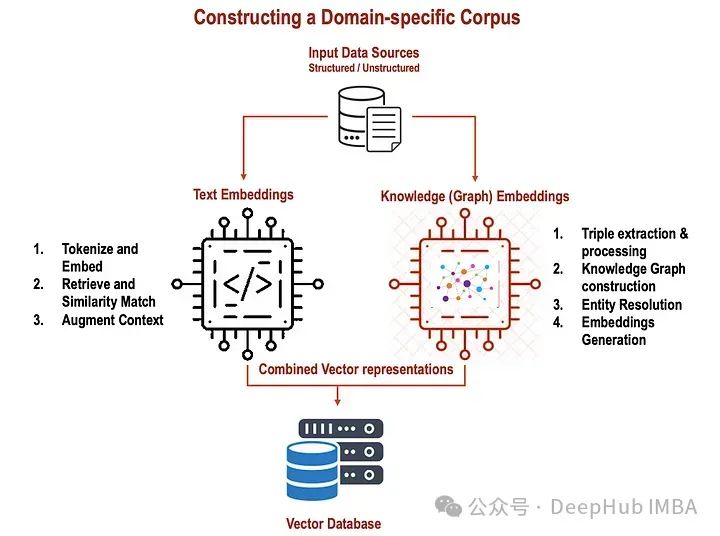
整合文本和知识图谱嵌入提升RAG的性能
在RAG模型中,文本嵌入和知识嵌入都允许对输入文本和结构化知识进行更全面、上下文更丰富的表示。这种集成增强了模型在答案检索、答案生成、对歧义的鲁棒性和结构化知识的有效结合方面的性能,最终导致更准确和信息丰富的响应。
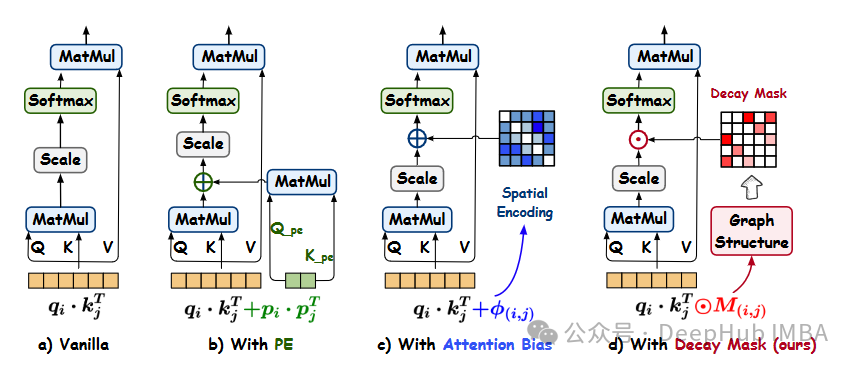
Gradformer: 通过图结构归纳偏差提升自注意力机制的图Transformer
Gradformer通过引入带有可学习约束的指数衰减掩码,为图Transformer提供了一种新的方法,有效地捕捉了图结构中的本地和全局信息。
10个使用NumPy就可以进行的图像处理步骤
本文将介绍10个使用使用NumPy就可以进行的图像处理步骤,虽然有更强大的图像处理库,但是这些简单的方法可以让我们更加熟练的掌握NumPy的操作。

贝叶斯推理导论:如何在‘任何试验之前绝对一无所知’的情况下计算概率
本文将进一步探讨如何通过匹配覆盖率来证明客观贝叶斯分析的先验;重新审视贝叶斯和拉普拉斯研究过的问题,看看如何用更现代的方法来解决这些问题。

如何准确的估计llm推理和微调的内存消耗
在本文中,我将介绍如何计算这些模型用于推理和微调的最小内存。这种方法适用于任何的llm,并且精确的计算内存总消耗。
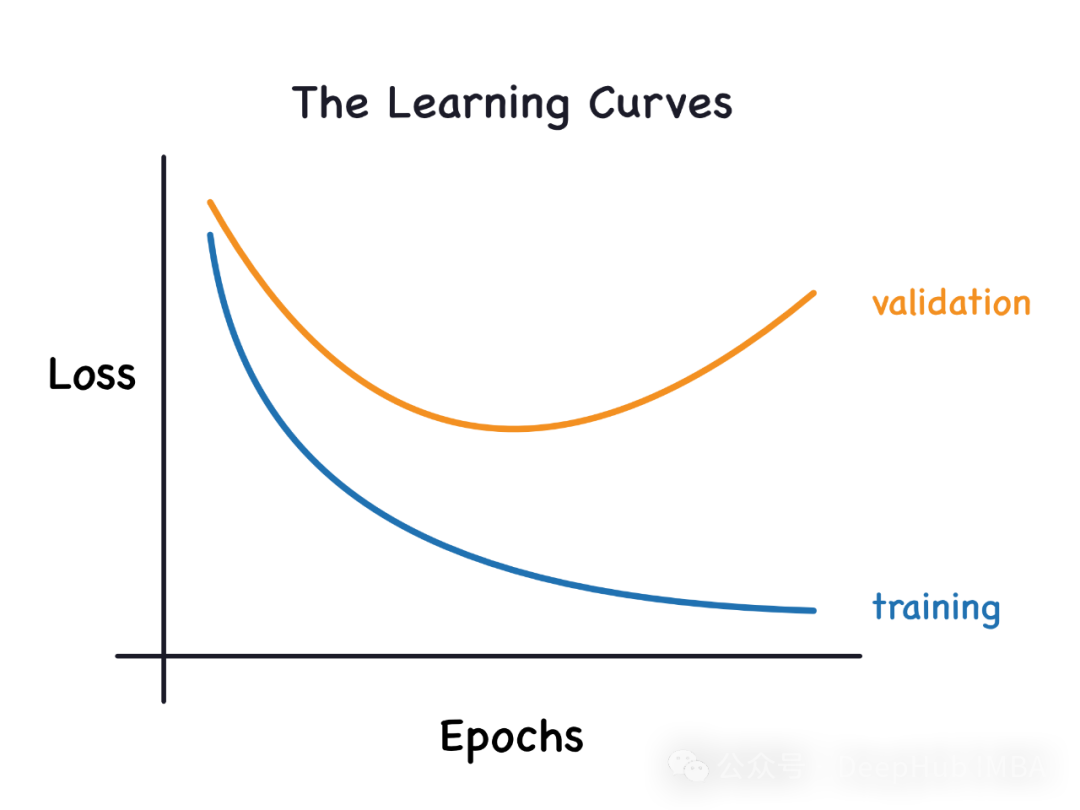
通过学习曲线识别过拟合和欠拟合
本文将介绍如何通过学习曲线来有效识别机器学习模型中的过拟合和欠拟合。

2024年4月计算机视觉论文推荐
本文将整理4月发表的计算机视觉的重要论文,重点介绍了计算机视觉领域的最新研究和进展,包括图像识别、视觉模型优化、生成对抗网络(gan)、图像分割、视频分析等各个子领域
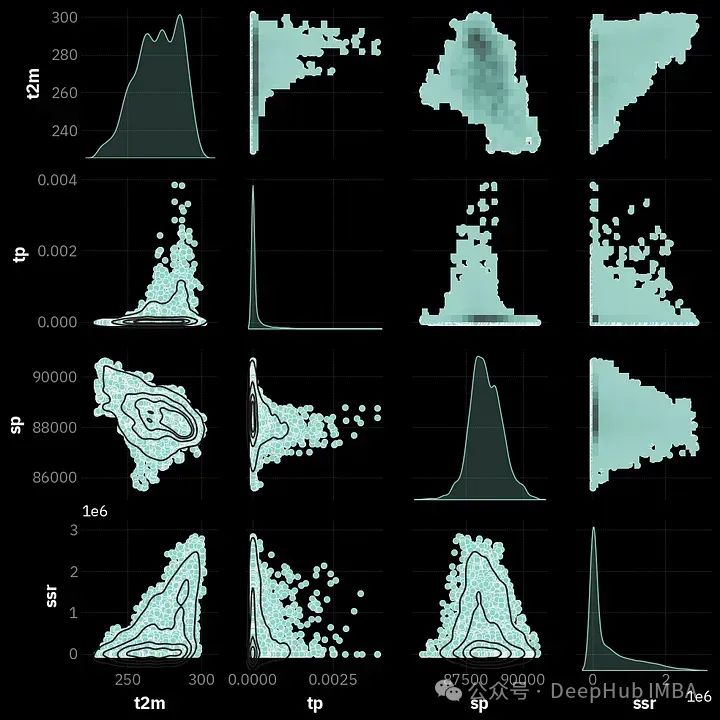
常用的时间序列分析方法总结和代码示例
在本文中将在分析时间序列时使用的常见的处理方法。这些方法可以帮助你获得有关数据本身的见解,为建模做好准备并且可以得出一些初步结论。
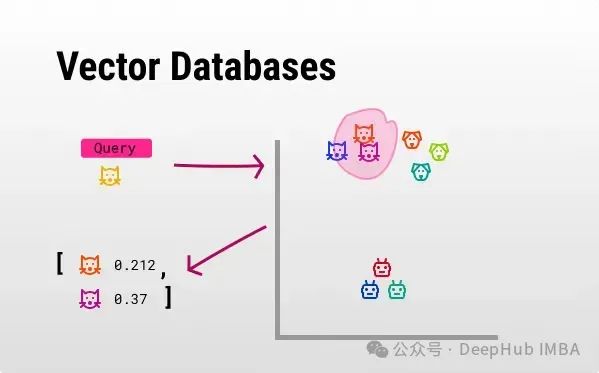
开源向量数据库比较:Chroma, Milvus, Faiss,Weaviate
本文为你提供四个重要的开源向量数据库之间的全面比较,希望你能够选择出最符合自己特定需求的数据库。

微软Phi-3,3.8亿参数能与Mixtral 8x7B和GPT-3.5相媲美,量化后还可直接在IPhone中运行
Phi-3是一系列先进的语言模型,专注于在保持足够紧凑以便在移动设备上部署的同时,实现高性能
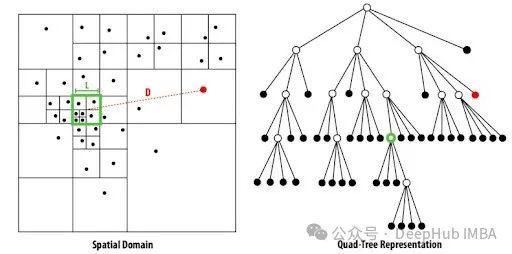
Barnes-Hut t-SNE:大规模数据的高效降维算法
Barnes-Hut t-SNE优化了原始 t-SNE 算法的计算效率,使其能够在实际应用中更为广泛地使用。
5种搭建LLM服务的方法和代码示例
在这篇文章中,我们将总结5种搭建开源大语言模型服务的方法,每种都附带详细的操作步骤,以及各自的优缺点。

使用ORPO微调Llama 3
ORPO是一种新的微调技术,它将传统的监督微调和偏好对齐阶段结合到一个过程中。我们将使用ORPO和TRL库对新的Llama 3 8b模型进行微调。
掌握时间序列特征工程:常用特征总结与 Feature-engine 的应用
本文将通过使用feature-engine来简化这些特征的提取
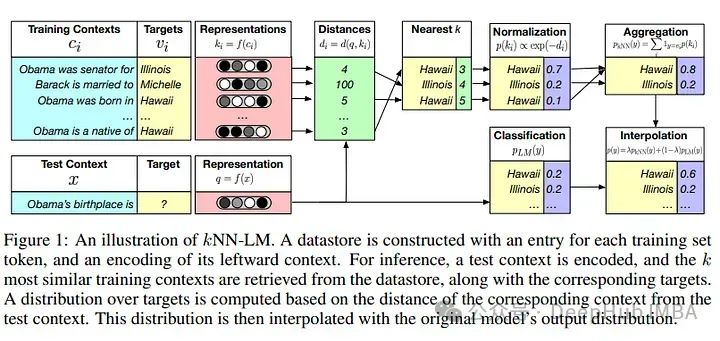
RAG 2.0架构详解:构建端到端检索增强生成系统
当前RAG的问题在于各个子模块之间并没有完全协调,就像一个缝合怪一样,虽然能够工作但各部分并不和谐,所以我们这里介绍RAG 2.0的概念来解决这个问题。
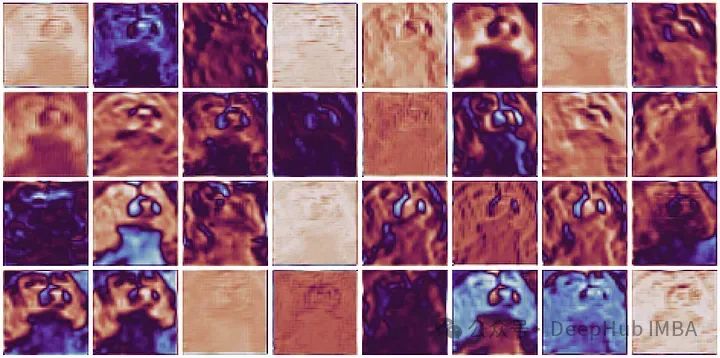
PyTorch小技巧:使用Hook可视化网络层激活(各层输出)
这篇文章将演示如何可视化PyTorch激活层。可视化激活,即模型内各层的输出,对于理解深度神经网络如何处理视觉信息至关重要,这有助于诊断模型行为并激发改进。