
《The Attention is all you need》的论文彻底改变了自然语言处理的世界,基于Transformer的架构成为自然语言处理任务的的标准。
尽管基于卷积的架构在图像分类任务中仍然是最先进的技术,但论文《An image is worth 16x16 words: transformer for image recognition at scale》表明,计算机视觉中CNNs的依赖也不是必要的,直接对图像进行分块,然后使用序纯transformer可以很好地完成图像分类任务。

在ViT中,图像被分割成小块,并将这些小块的线性嵌入序列作为Transformer的输入。对图像进行补丁处理方式与NLP应用程序中的标记(单词)相同。
由于缺乏 CNN 固有的归纳偏差(如局部性),Transformers 在数据量不足的情况下不能很好地泛化。但是当在大型数据集上进行训练时,它在多个图像识别基准上确实达到或超过了最先进的水平。在深入本文之前,如果你从未听说过 Transformer 架构,我强烈建议你查看 The Illustrated Transformer。
在开始实现之前,我们先看看ViT架构
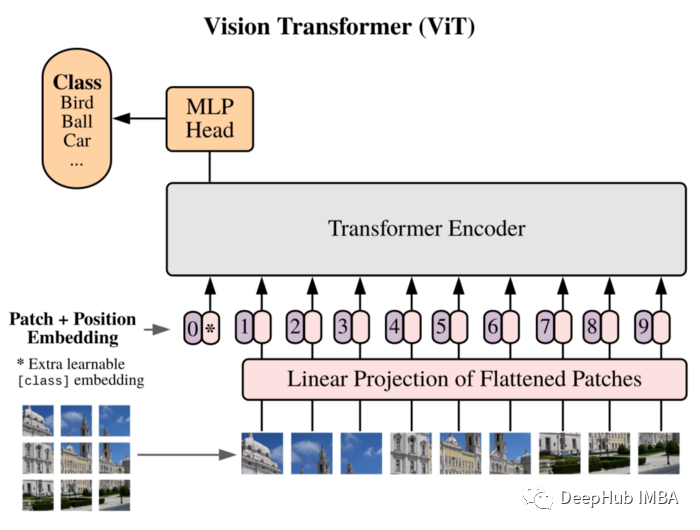
可以看到输入图像被分解成 16x16 的扁平化块,然后使用普通的全连接层对这些块进行嵌入操作,并在它们前面包含特殊的 cls token 和位置嵌入。
线性投影的张量被传递给标准的 Transformer 编码器,最后传递给 MLP 头,用于分类目的。
首先我们从导入库开始,一步一步实现论文中提到的ViT模型:
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn.functional as F
from torch import Tensor, nn
from torchsummary import summary
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
为了调试我们的模型,还需要一张图片来进行测试:
img = Image.open('penguin.jpg')
fig = plt.figure()
plt.imshow(img)
plt.show()
图片还需要一些预处理:
transform = Compose([
Resize((224, 224)),
ToTensor(),
])
x = transform(img)
x = x.unsqueeze(0)
print(x.shape)
通过上面的预处理,我们的张量大小为torch.Size([1,3,224,224])。接下来,我们开始按照论文实现ViT。
切分补丁和投影
将图像分成多个补丁,并将它们展平。
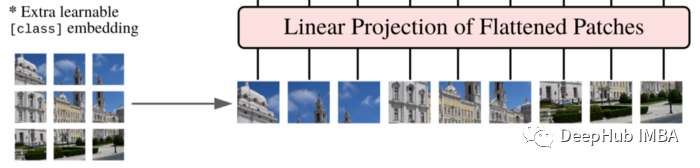
以下是论文的原话:

我们可以很容易地使用 einops 来实现它。
patch_size = 16
patches = rearrange(x, 'b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size)
下一步是对它们进行投影:这可以使用标准线性层轻松实现,但本文中使用卷积层(使用 kernel_size 和 stride 等于 patch_size 获得的,这压根以提高性能)。让我们在 PatchEmbedding 类中解决问题。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
) # this breaks down the image in s1xs2 patches, and then flat them
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return x
为了测试我们的代码,可以调用 PatchEmbedding()(x).shape ,得到:
torch.Size([1, 196, 768])
CLS 令牌和位置嵌入
与 BERT 的分类令牌类似,一个可学习的嵌入被预先添加到嵌入补丁的序列中。然后将位置嵌入添加到补丁嵌入中以保留位置信息。这里使用标准可学习的一维位置嵌入。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
) # this breaks down the image in s1xs2 patches, and then flat them
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
x = torch.cat([cls_tokens, x], dim=1) #prepending the cls token
x += self.positions
return x
这样生成的嵌入向量序列用将作编码器的输入。
Transformer 编码器 (Vaswani et al., 2017) 由多头自注意力和 MLP 块的交替层组成。在每个块之前应用Layer Norm (LN),并在每个块之后添加残差连接。
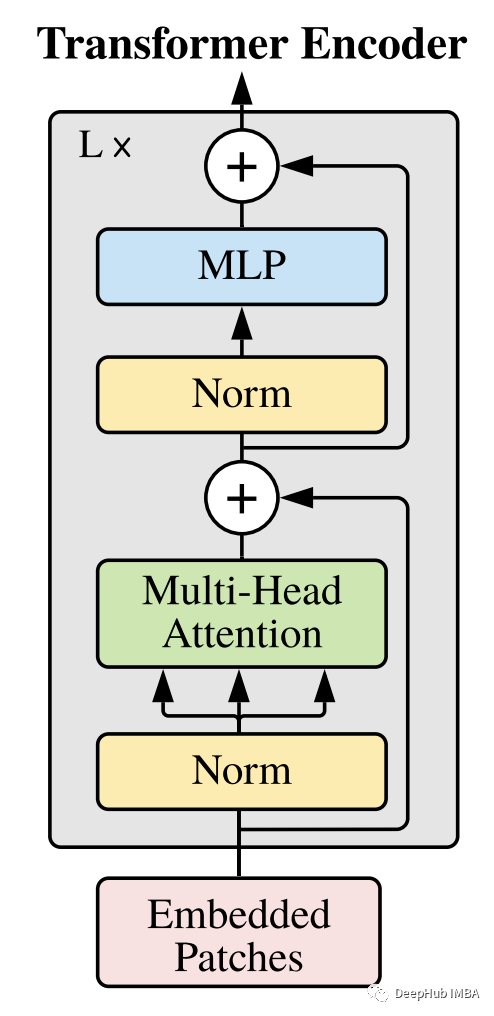
注意力机制
注意力机制需要三个输入:查询、键和值。然后它使用查询和键计算注意力矩阵。
这里将实现一个多头注意力机制,主要概念是使用查询和键之间的乘积来了解序列中的每个元素对其余元素的重要性。稍后将使用这些信息对值进行缩放。可以为查询、键和值矩阵使用 3 个不同的线性层,也可以将它们融合为一个。
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.qkv = nn.Linear(emb_size, emb_size * 3) # queries, keys and values matrix
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
out = torch.einsum('bhal, bhlv -> bhav ', att, values) # sum over the third axis
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
残差连接
从上图中可以看出,transformer 块有残差连接。
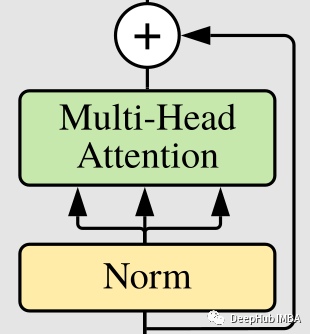
我们可使用一个包装器来执行残差加法,这样可以复用:
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
注意力块的输出被传递到一个全连接层。最后一层由两层组成,它们通过因子 L 进行上采样:
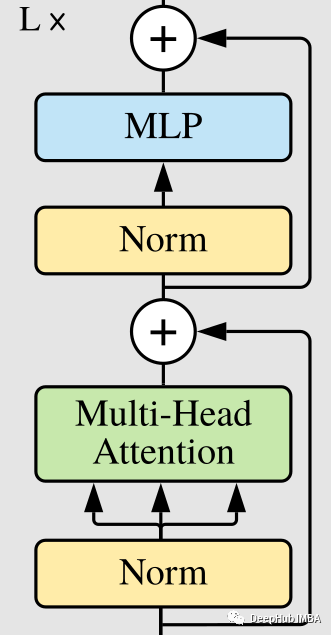
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, L: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, L * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(L * emb_size, emb_size),
)
Transformer 编码器块
上面的分块步骤都已经完成了,下面我们将这些块整合成编码器:
class TransformerEncoderBlock(nn.Sequential):
def __init__(self, emb_size: int = 768, drop_p: float = 0., forward_expansion: int = 4,
forward_drop_p: float = 0.,
**kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, L=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
要测试这部分代码,可以直接调用:
patches_embedded = PatchEmbedding()(x)
print(TransformerEncoderBlock()(patches_embedded).shape)
这样会返回 torch.Size([1,197,768])
Transformer编码器
因为只需要编码器,所以可以使用上面编写的 TransformerEncoderBlock 进行构建
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
分类头
因为ViT是分类任务,所以最后要有一个进行分类人物的分类头,这个非常简单:计算整个序列的简单平均值之后是一个标准的全连接,它给出了类概率。
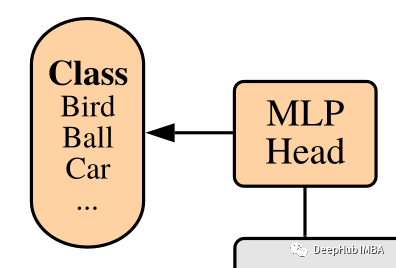
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
整合所有的组件——VisionTransformer
将我们上面构建的所有内容整合,最终就可以得到 ViT 了。
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
查看我们构建的模型,可以使用 torchsummary 来检查结果:
print(summary(ViT(), (3,224,224), device='cpu'))
将得到:
================================================================
Total params: 86,415,592
Trainable params: 86,415,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 364.33
Params size (MB): 329.65
Estimated Total Size (MB): 694.56
----------------------------------------------------------------
总结
本篇文章使用 Pytorch 中实现 Vision Transformer,通过我们自己的手动实现可以更好的理解ViT的架构,为了加深印象我们再看下论文中提供的与现有技术的比较:
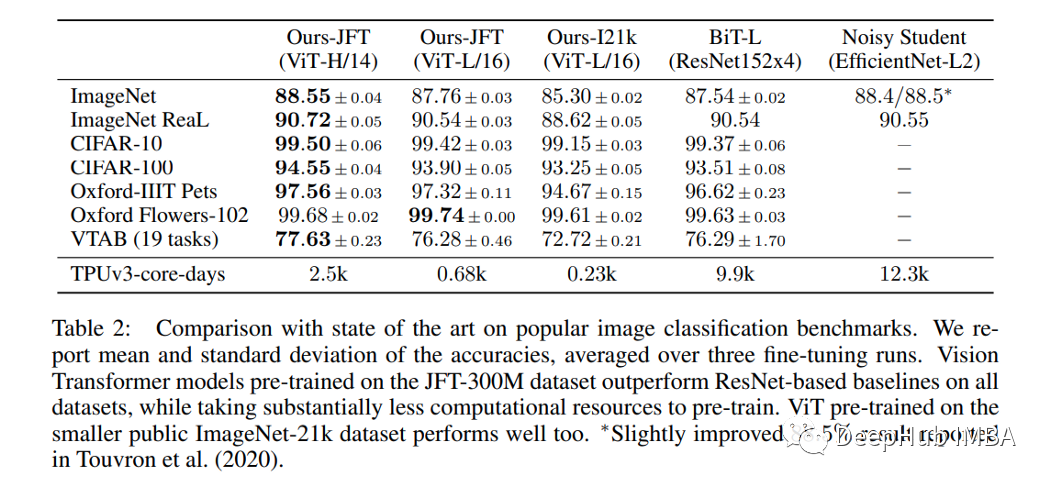
本文代码:https://github.com/alessandrolamberti/ViT
作者:Alessandro Lamberti