语音识别芯片LD3320介绍
LD3320 芯片是一款“语音识别”芯片,集成了语音识别处理器和一些外部电路,包括AD、DA 转换器、麦克风接口、声音输出接口等。
非常全面的数字人解决方案(含源码)
数字人解决方案实际应用案例抖音虚拟主播人机交互数字站桶人首先我先给数字人重新做一个定义:“把人数字化,以行人的职责”。怎么理解呢?我举两个例子就清楚了。第一个是现在直播带货,主播成本越来越高,我们的数字人能否代替主播24小时自动带货呢?这里数字化的是主播的形象、声音、性格特质,以及商品的知识。另一个
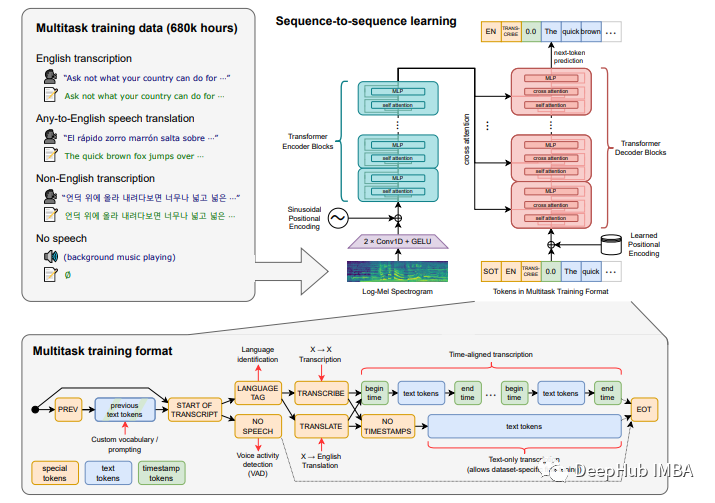
使用OpenAI的Whisper 模型进行语音识别
本文将解释用于训练的数据集的种类以及模型的训练方法,以及如何使用Whisper
人工智能:通过Python实现语音合成的案例
今天给大家介绍一下基于百度的AI语音技术SDK实现语音合成的案例,编程语言采用Python,希望对大家能有所帮助!
MS-TTS:免费微软TTS语音合成工具(一键合成导出MP3音频)
免费微软TTS语音合成工具(一键合成导出MP3音频)

从视频到音频:使用VIT进行音频分类
在本文中,我们将利用ViT - Vision Transformer的是一个Pytorch实现在音频分类数据集GTZAN数据集-音乐类型分类上训练它。
语音识别之Kaldi学习GMM-HMM
kaldi语音识别理论与实践课程学习。前面的博客介绍了语音识别的基础知识及原理。现在开始学习实战。以Kaldi框架为基础。Kaldi是一个有全套的语音识别代码的工具,由Dan Povey博士和捷克的BUT大学联合开发,最早发布于2011年,底层代码使用C++编写,接口采用shell和python,覆
人工智能:语音识别技术介绍
就是语音识别技术中的识别过程,根据输入的语音信号,然后和训练好的HMM声学模型、语言模型、发音字典建立一个搜索空间,根据搜索算法找到最合适的路径。特征提取:把要分析的信号从最原始信号提取出来,这个阶段主要是对语音的幅度标准化、频响校正、分帧、加窗、始末端点检测等预处理操作,为声学模型提供需要特征向量

谷歌AudioLM :通过歌曲片段生成后续的音乐
AudioLM 是 Google 的新模型,能够生成与提示风格相同的音乐。该模型还能够生成复杂的声音,例如钢琴音乐或人的对话。结果是它似乎与原版没有区别,这是十分让人惊讶的。
Jetson Nano python中文语音播报数字距离 基于pyttsx3
Jetson Nano 中文语音播报
分享本周所学——人工智能语音识别模型CTC、RNN-T、LAS详解
本人是一名人工智能初学者,最近一周学了一下AI语音识别的原理和三种比较早期的语音识别的人工智能模型,就想把自己学到的这些东西都分享给大家,一方面想用浅显易懂的语言让大家对这几个模型有所了解,另一方面也想让大家能够避免我所遇到的一些问题。然后因为我也只是一名小白,所以有错误的地方还希望大佬们多多指正。
(含源码和训练数据集)在Python中使用PyTorch Lightning构建自动语音识别(ASR)模型
人工智能正在推动第四次工业革命,机器可以听、看、理解、分析,然后在超人的水平上做出明智的决定。 然而,人工智能的有效性取决于底层模型的质量。 因此,无论您是学术研究人员还是数据科学家,您都希望快速构建具有各种参数的模型,并为您的解决方案确定最有效的模型。在这篇文章中,我将介绍使用 PyTorch L
python_视频中语音识别转出文本
注意:没有“stepladder”的同学建议不要看啦1. 安装需要的包1.1 安装SpeechRecognition包pip install SpeechRecognition1.2 安装 PockSphinx包在线装总是失败,采用本地安装https://www.lfd.uci.edu/~gohlk
深度学习100例 | 第41天-卷积神经网络(CNN):UrbanSound8K音频分类(语音识别)
🔗 运行环境:python3🚩 作者:K同学啊🥇 选自专栏:《深度学习100例》🔥 精选专栏:《新手入门深度学习》📚 推荐专栏:《Matplotlib教程》🧿 优秀专栏:《Python入门100题》🚀 我的环境:语言环境:Python3.6.5编译器:jupyter notebook
使用 Python 实现一个简单的智能聊天机器人
Python100行代码实现简单的智能聊天机器人

TensorFlow和Pytorch中的音频增强
本文将介绍TF和Pytorch这两个非常流行的深度学习框架中进行音频数据增强的方法
Python实现文字合成音频文件
Python技术哪家强?从此我是段子王!1. 创建应用2. 测试语音合成是否可用3. 工具人的觉悟——调个包,造个轮儿?4. 找段子素材合成音频(百度AI版本)5. 整个简单的——pyttsx3版本我将月亮缝入躯体,葬自我于山谷,如果那一天野花疯长,那便是我在讲最近正好有朋友找我问能不能把他的面试题
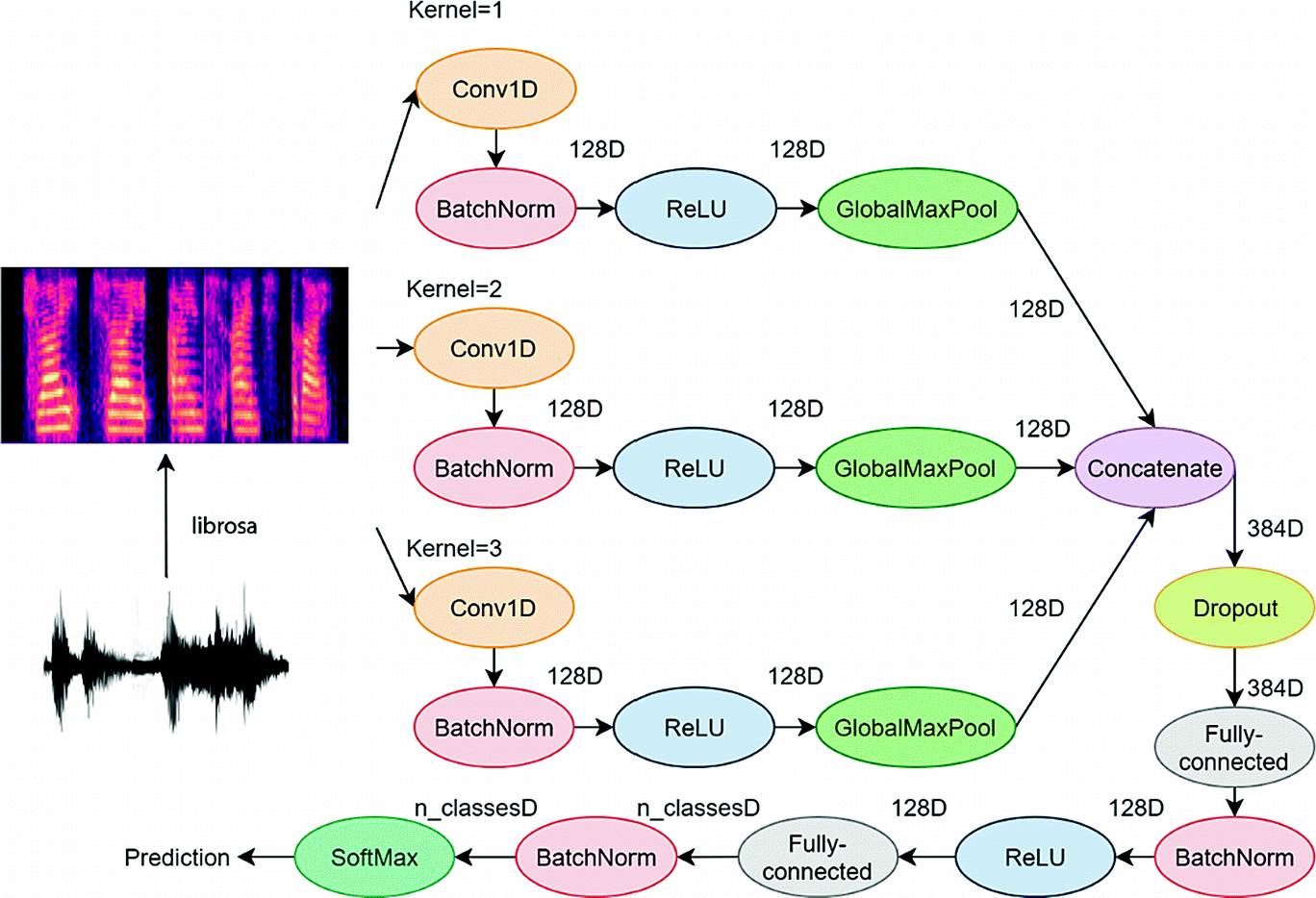
音频数据建模全流程代码示例:通过讲话人的声音进行年龄预测
从EDA、音频预处理到特征工程和数据建模的完整源代码演示
服务机器人语音对话的实现
基于语音的人机交互是服务机器人交互的最主要表现形式之一,它主要解决以语音作为信息载体,让机器人具有像人一样的“能听会说”的能力,降低使用门槛,且能够解放双手双眼的问题。所以把对话交互功能做好,是服务机器人的基础。交互功能实现步骤包括:麦克风数据采集、麦克风音频降噪和定向、功放声音回馈、关键词唤醒、语



