
Python技术哪家强?从此我是段子王!
最近正好有朋友找我问能不能把他的面试题文字转成音频文件,这还不简单?python除了不能生孩子,啥不能干?
我也就有这个想法试着鼓捣了一下,用网上的段子合成语音文件。
我们这里就用百度AI平台做演示,主要还是因为百度AI平台有很多好玩的高级的功能可以用,
这里带大家熟悉一下百度AI的使用。
我这里一共做了两个版本的一个百度AI版本的,一个pyttsx3版本的都能达到目的。
1. 创建应用
百度AI开放平台的网址:百度AI,只要注册过百度帐号就可以登录使用。
鼠标放到开放能力,
点击语音合成:
点击立即使用,
可以看到这个控制台提供各种优质的付费服务,当然,我们这里就不花钱了,直接点击领取免费资源,点击语音合成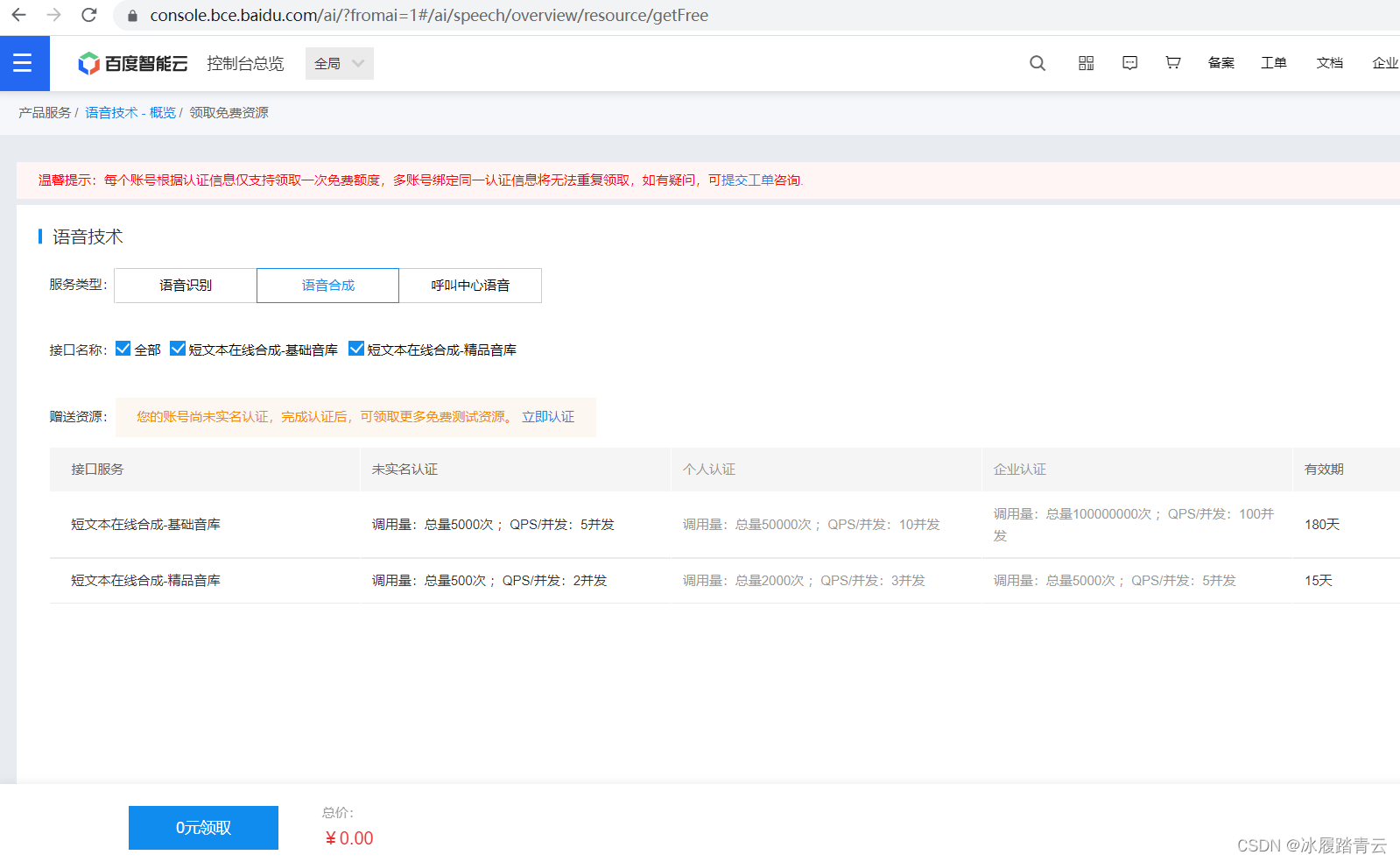
点击0元领取: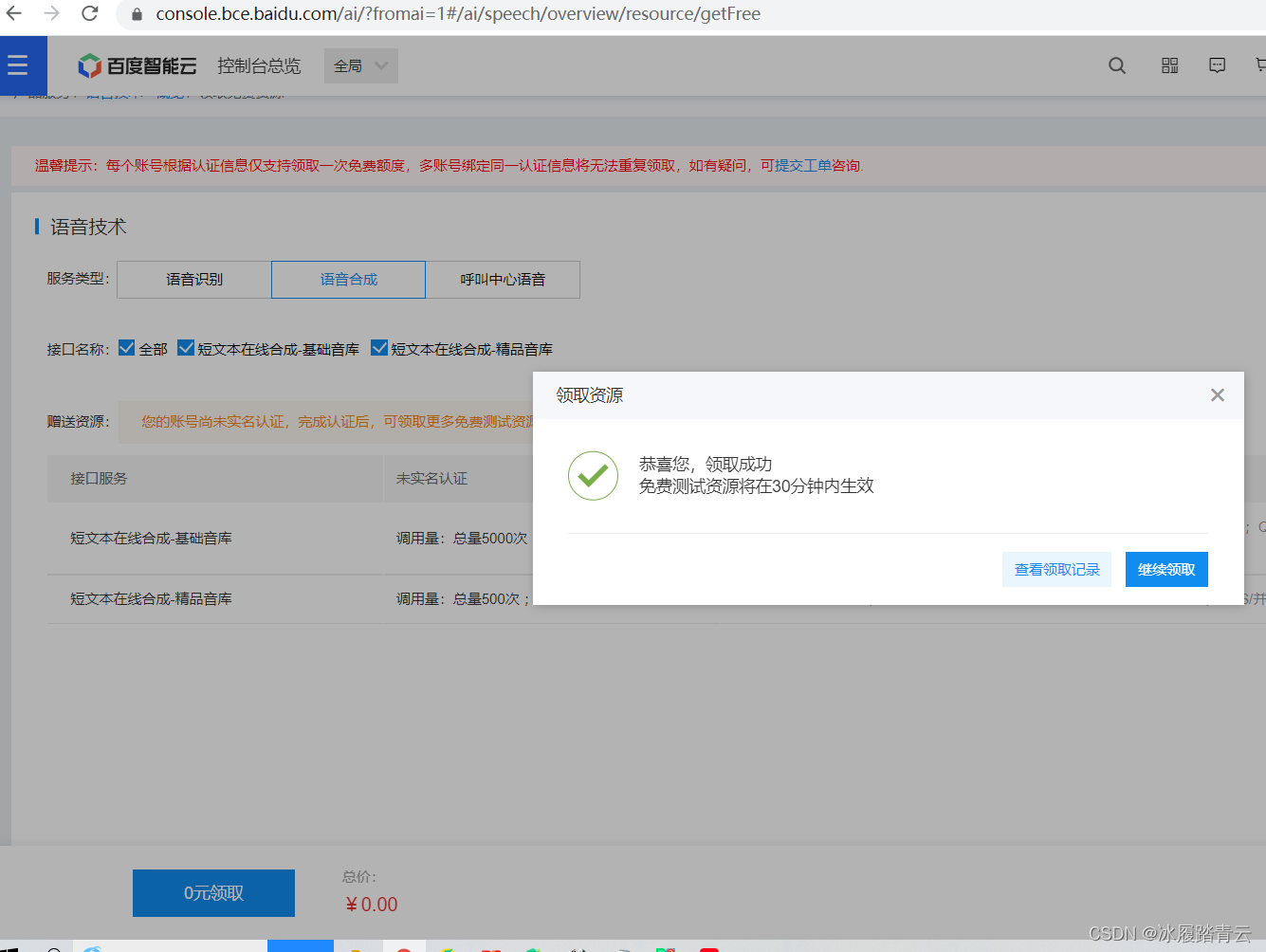
需要的都可以领,有效期大概都是半年左右,没事了自己玩玩也挺有趣的。
可能是访问者过多网站不太稳定?我这老是这样:
领完了看资源列表是这样:
它提示领取的免费测试资源预计30分钟内生效,刷了几分钟都没出现,就停下来该干啥干啥,30分钟后再来看。
听听音乐,10分钟后,我来刷一下: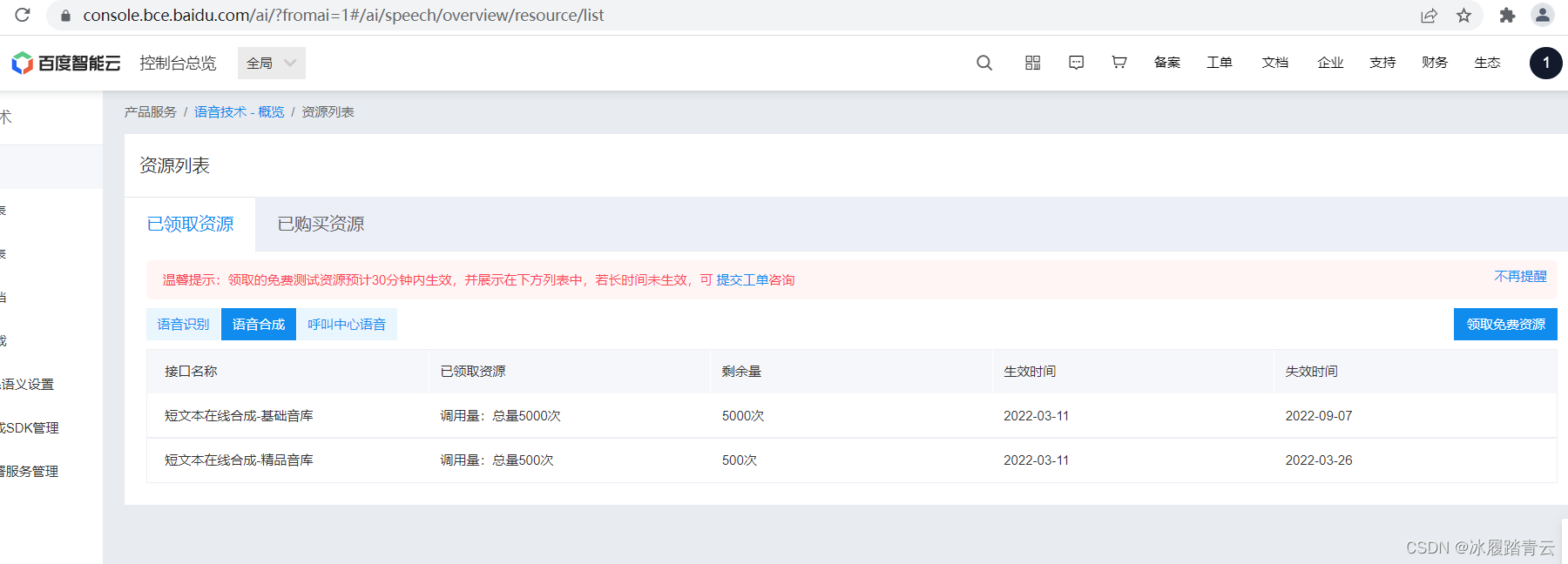
发现已经可以用了。
接下来开始创建应用: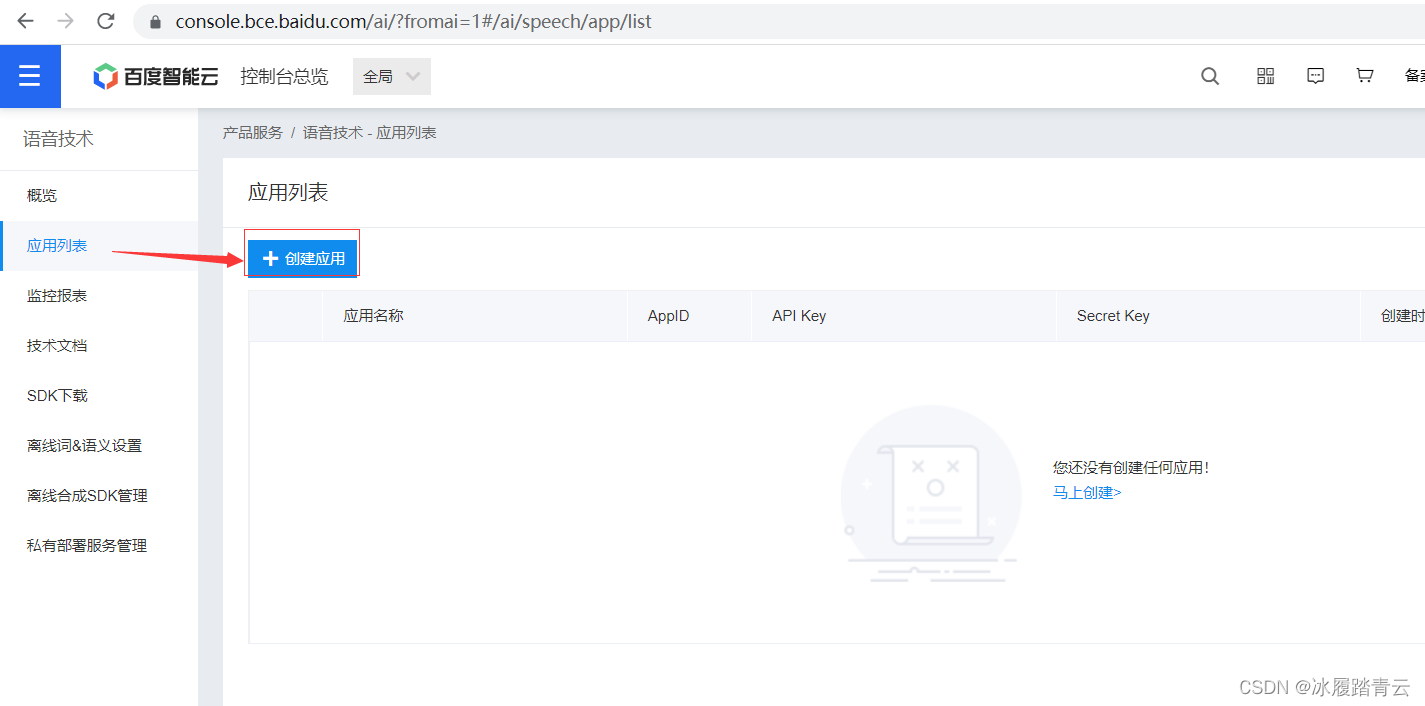
随便取个名字,我这里填了个test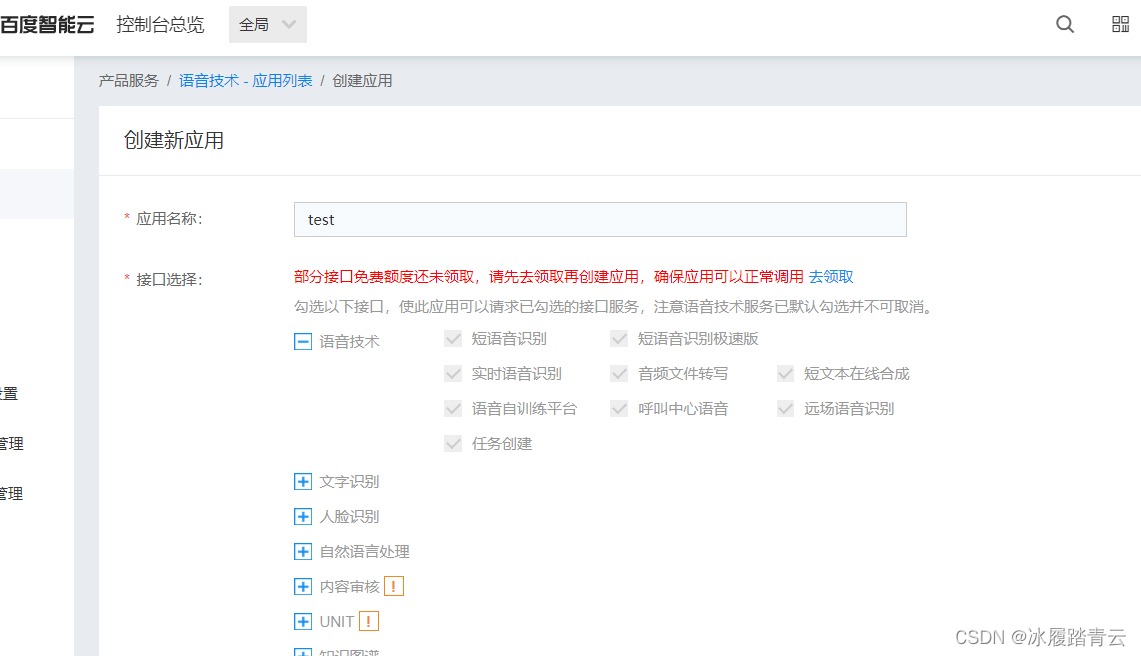
拉到最下面,把必填的信息填一下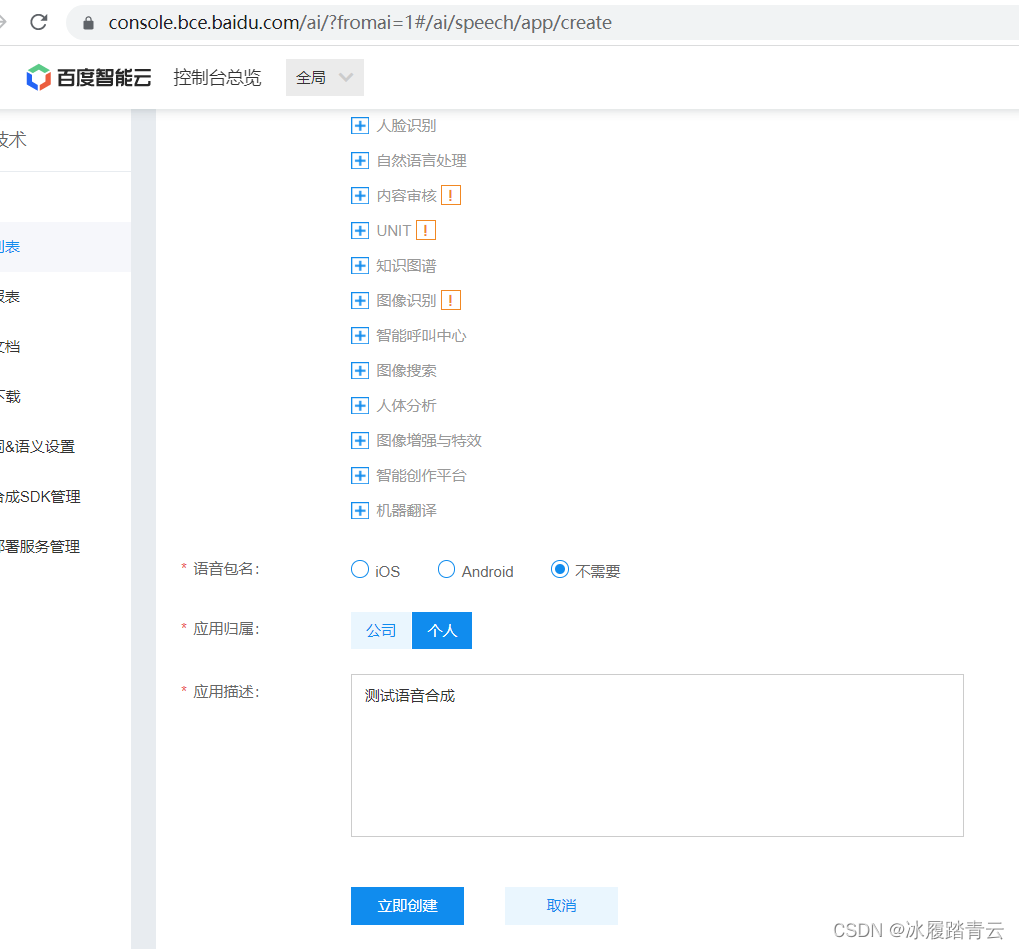
点击立即创建就🆗了。
感兴趣的可以看一下人家的应用文档,我们这里就直接开整了,看一下应用列表: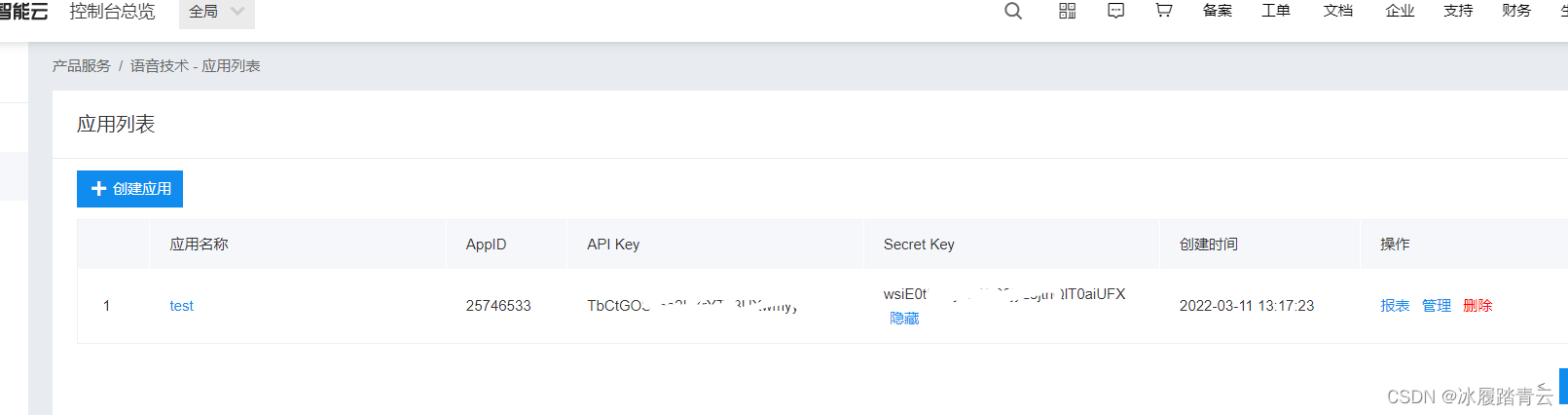
看到APIKey,SecretKey了,这两个是调用服务的必填参数。
2. 测试语音合成是否可用
上面我们已经拿到APIKey,SecretKey了,
接下来我们直接上代码,整一段话测试一下合成语音的效果:
# -*- coding: utf-8 -*-import time
import requests
import urllib.parse
import urllib.request
deffetch_token():# 提交请求,拿到token
api_key ="TbCtGOSc5xxxxxxxxxx"# 使用百度AI平台管理中心中创建的应用的API Key
secret_key ="wsiE0t8Q7xxxxxxx"# 使用百度AI平台管理中心中创建的应用的Secret Key
token_url ="https://openapi.baidu.com/oauth/2.0/token"# print("fetch token begin")
params ={"grant_type":"client_credentials","client_id": api_key,"client_secret": secret_key}
r = requests.get(url=token_url, params=params)if r.status_code ==200:
rstr = r.json()# print(r.text)# print(rstr['access_token'])
tok = rstr['access_token']return(tok)else:print(r.text)print('请求错误!')if __name__ =='__main__':
token = fetch_token()
TTS_URL ="https://tsn.baidu.com/text2audio"
text ="""
小时候吃了800包德芙,我妈把我从16楼扔下去,笑死,我一路顺滑到底,根本死不了。
小时候吃了两箱士力架,我妈把我锁地下室两年,笑死,根本不饿。
小时候偷喝了我爸的红牛,被我爸追着打了三天三夜还在跑,笑死,我的能量超乎你想象。
小时候偷喝了10瓶雪碧,我妈罚我站在太阳底下,笑死,爽快的一批。
小时候偷玩真传奇,我妈罚我一年没有零花钱,笑死,根本不缺钱。
小时候一次吃了10盒炫迈,我妈罚我跑几百公里,笑死,根本停不下来。
小时候偷吃100支夏日奇兵,我妈罚我站在太阳底下暴晒2个月,笑死,太阳都给冻住。
小时候搞对象被知道了,我妈让我和对象分手,笑死,根本就分不完。。。
""".encode('utf8')# 发音人选择, 基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫,# 精品音库:5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
PER =103# 语速,取值0-15,默认为5中语速
SPD =5# 音调,取值0-15,默认为5中语调
PIT =5# 音量,取值0-9,默认为5中音量
VOL =5# 下载的文件格式, 3:mp3(default) 4: pcm-16k 5: pcm-8k 6. wav
AUE =3
FORMATS ={3:"mp3",4:"pcm",5:"pcm",6:"wav"}
FORMAT = FORMATS[AUE]
data = urllib.parse.urlencode({'tex': text,'per': PER,'tok': token,'cuid':'20009514','ctp':1,'lan':'zh','aue': AUE})# print('test on Web Browser' + TTS_URL + '?' + data)
req = requests.post(TTS_URL, data)print(req.status_code)if req.status_code ==200:# print(req.content)
result_str = req.content
save_file = time.strftime("%Y%m%d%H%M%S", time.localtime())+'.'+ FORMAT
withopen(save_file,'wb')as of:
of.write(result_str)print('success!')else:print('has error!')
执行一下,看一下效果: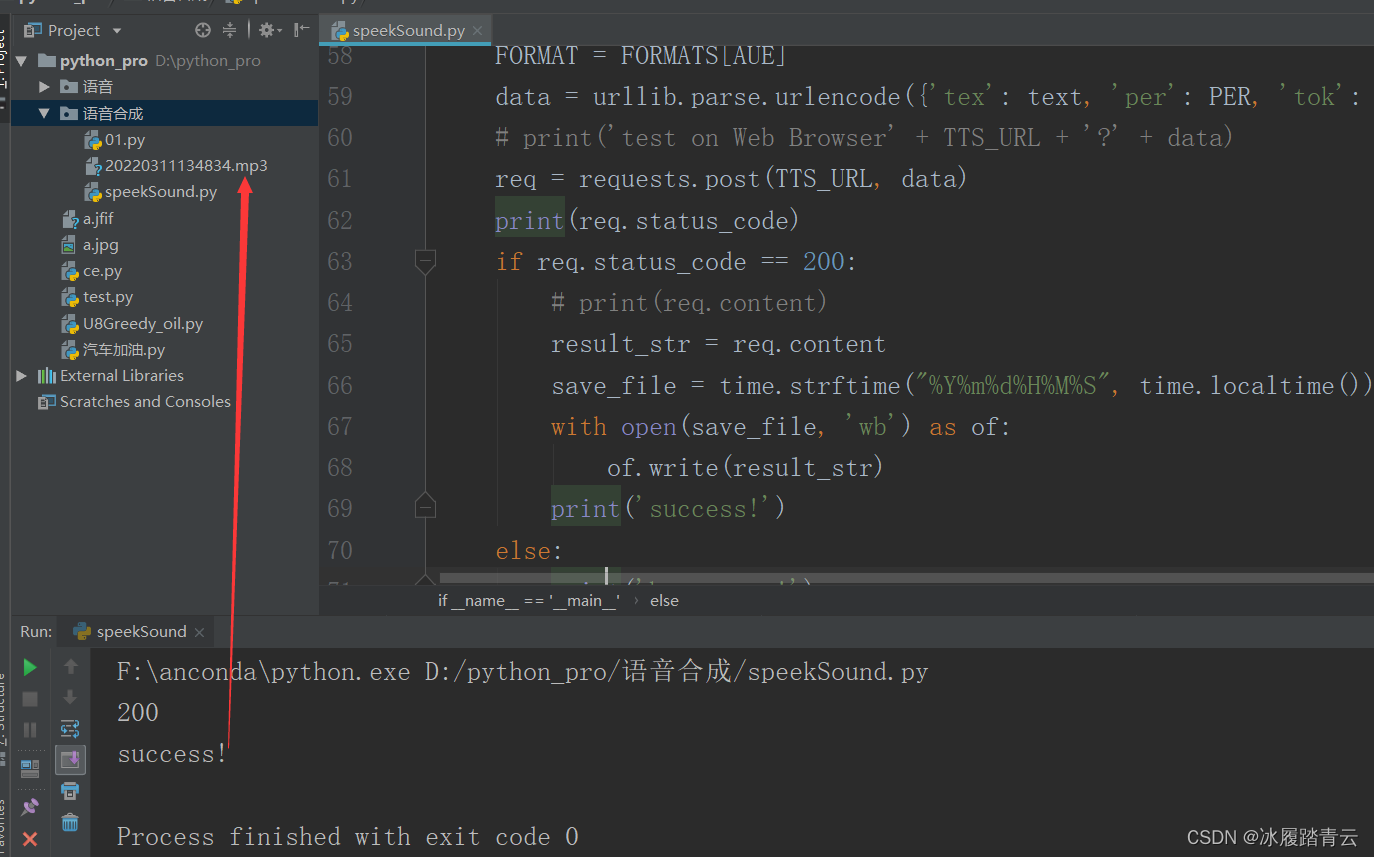
成功生成mp3文件,听一下效果还可以。
以上代码小伙伴如果要测试,只需要把自己的APIKey,SecretKey这两个参数替换上就可以用了,想换声音的话就看注释改PER参数。
3. 工具人的觉悟——调个包,造个轮儿?
上面我们已经实现了语音合成的测试,但代码毕竟还是通用性有点低,你想想,以后总不能有这需求咱们都这样写一遍吧,即使是复制粘贴也不雅观,代码过度冗余就显得太low了。
想要做个好的工具人,那就尽量让自己整的东西用起来不费力,这样才能更好的摸鱼!
那接下来咱们就自己动手,把上面的代码改造的具有通用性一点,想想咱们的需求也就是把文本转成语音而已,那我们需要的大概就是把文本内容传进去,然后它给我门生成mp3音频,最好带个标题给音频取个名字,想到咱就干,开整:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2022/3/11 18:15# @Author : 冰履踏青云# @File : speekSound.pyimport requests
import urllib.parse
import urllib.request
deffetch_token():# 提交请求,拿到token
api_key ="TbCtGOSc5exxxxxx"# 使用百度AI平台管理中心中创建的应用的API Key
secret_key ="wsiE0t8Q7xxxxxxxxxx"# 使用百度AI平台管理中心中创建的应用的Secret Key
token_url ="https://openapi.baidu.com/oauth/2.0/token"# print("fetch token begin")
params ={"grant_type":"client_credentials","client_id": api_key,"client_secret": secret_key}
r = requests.get(url=token_url, params=params)if r.status_code ==200:
rstr = r.json()# print(r.text)# print(rstr['access_token'])
tok = rstr['access_token']return(tok)else:print(r.text)print('网络请求出错,无法获取token!')defgen_speech(content,title):
token = fetch_token()
TTS_URL ="https://tsn.baidu.com/text2audio"
text = content.encode('utf8')# 发音人选择, 基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫,# 精品音库:5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
PER =103# 语速,取值0-15,默认为5中语速
SPD =5# 音调,取值0-15,默认为5中语调
PIT =5# 音量,取值0-9,默认为5中音量
VOL =5# 下载的文件格式, 3:mp3(default) 4: pcm-16k 5: pcm-8k 6. wav
AUE =3
FORMATS ={3:"mp3",4:"pcm",5:"pcm",6:"wav"}
FORMAT = FORMATS[AUE]
data = urllib.parse.urlencode({'tex': text,'per': PER,'tok': token,'cuid':'20009514','ctp':1,'lan':'zh','aue': AUE})# print('test on Web Browser' + TTS_URL + '?' + data)
req = requests.post(TTS_URL, data)# print(req.status_code)if req.status_code ==200:# print(req.content)
result_str = req.content
save_file = title +'.'+ FORMAT
withopen('./音频文件//'+ save_file,'wb')as of:
of.write(result_str)# print('%s合成成功!'%title)else:print('合成语音时,网络请求出错!!!')
这样就简单的封装好合成语音模块了,下次再用就直接调speekSound.py里面的gen_speech方法就可以了。
整合好目录,把合成后的音频文件统一放入音频文件夹里,目录结构:
4. 找段子素材合成音频(百度AI版本)
接下来我们写个请求程序获取段子网素材在线合成音频。
找个段子网站,咱直接开干:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2022/3/11 18:30# @Author : 冰履踏青云# @File : duanzi.pyfrom gen_sound.speekSound import gen_speech
import requests
from lxml import etree
from requests.packages.urllib3.exceptions import InsecureRequestWarning
#关闭安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
url ='https://ishuo.cn/duanzi'
headers ={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
res = requests.get(url,headers=headers,verify=False).text
# print(res)
html = etree.HTML(res)
li_list = html.xpath("//div[@id='content']/div[@id='list']/ul/li")[:20]# 取前20个for li in li_list:
content = li.xpath('./div[1]/text()')[0]
title = li.xpath('./div[2]/a/text()')[0]# print(content,title)
gen_speech(content,title)print(title,'合成音频成功...')
这里我做测试,只取了前20条段子,执行结果: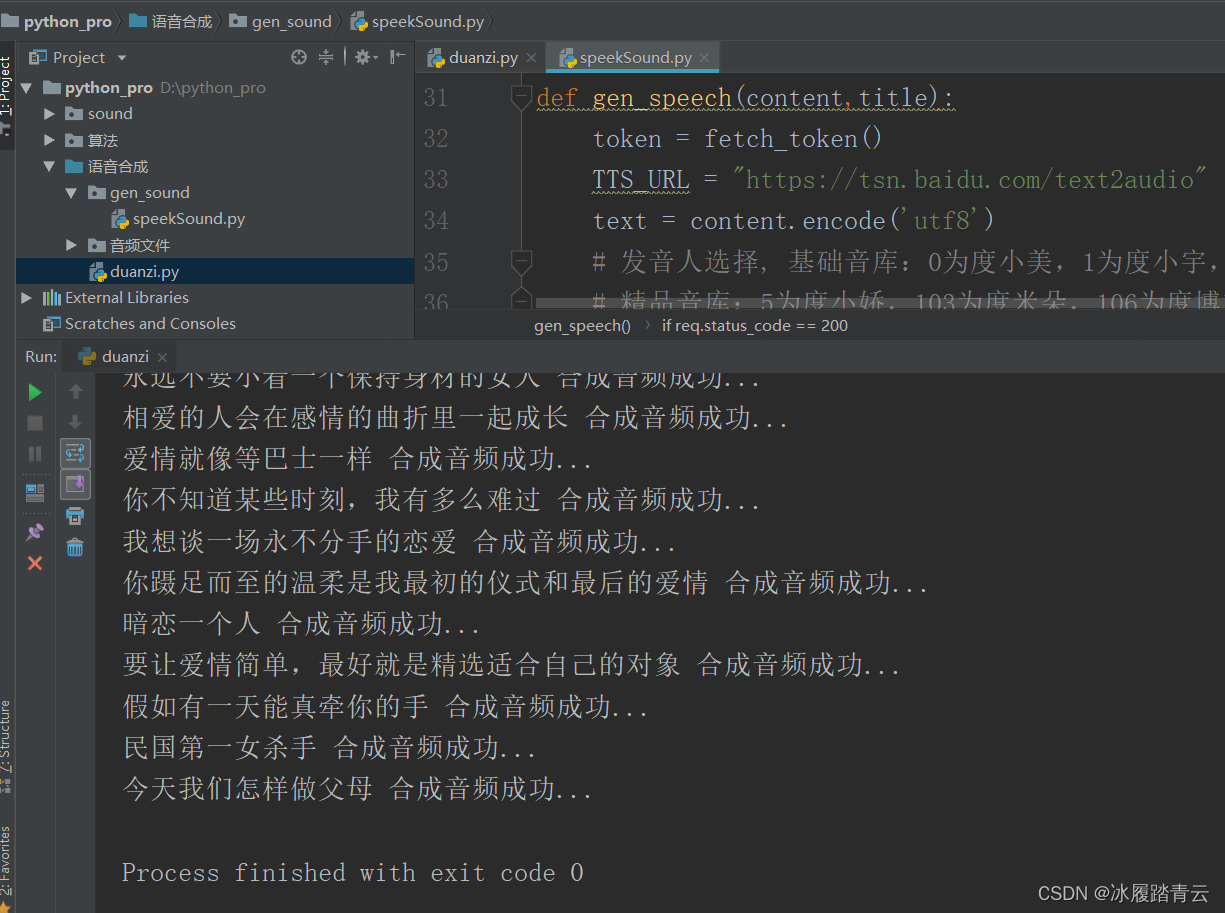
看一下音频文件夹:
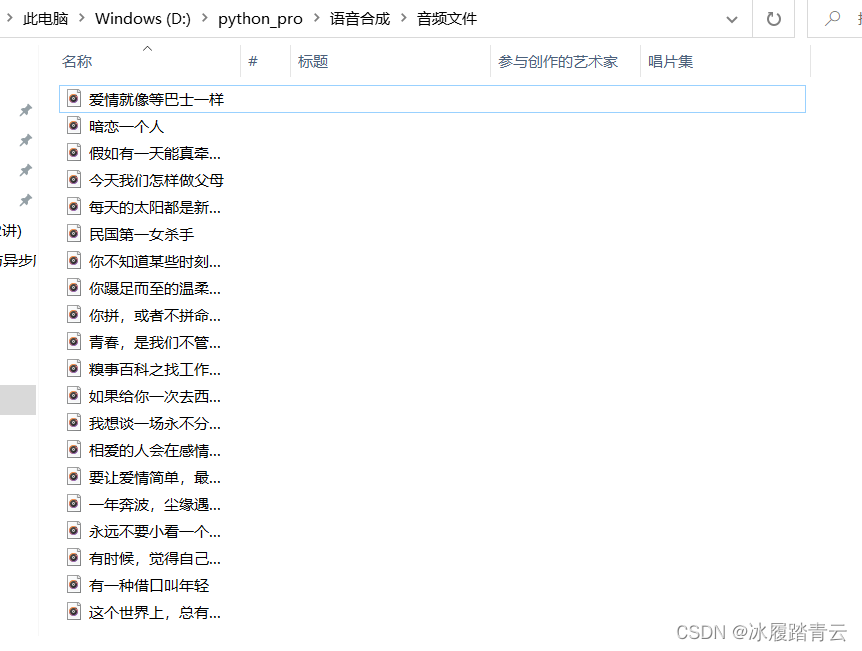
至此我们的目的就达到了。
5. 整个简单的——pyttsx3版本
有人就说了,我就不想用百度AI,想更省事儿,那也很简单,
python本身就有一个pyttsx3模块可以实现这个功能,使用之前需要安装一下这个模块:
pip install pyttsx3
工具整好,准备开干:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2022/3/11 19:51# @Author : 冰履踏青云# @File : pyttsx3合成语音.pyimport pyttsx3
engine = pyttsx3.init()# 模块初始化str='唉,这个世界对修仙者太不走好了,我去医院看病,医生非得打了我的金丹,说那是结石,刚出门诊就看到一个女孩子,年纪轻轻,就拥有着恐怖的修为,可被一帮人扭送着摘掉了她的元婴,旁边的旅馆,还有两位合体期的大神被抓进了大牢,向前走,有位出窍期的巨擘被烧掉了肉身,唉'
outFile ='xiu.mp3'# 输出格式
rate = engine.getProperty('rate')# 获取语速
engine.setProperty('rate',rate-10)# 调整语速
engine.save_to_file(str,outFile)# 这个位置必须放在播报Unicode字符串前面,# engine.say(str) # 设置要播报的Unicode字符串
engine.runAndWait()# 等待语音播报完毕
执行一下,感觉效果还可以。然后需要把朋友面试题的pdf或者其他形式的文档用python读取,替换掉str就完事了。
本来是不想写的,想想那么简单怎么还有人不会?
但是我怕万一呀,这里我也顺带写一份pyttsx3版本的吧,没啥难度,直接上代码:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2022/3/11 20:06# @Author : 冰履踏青云# @File : daunzi2.pyimport requests
from lxml import etree
from requests.packages.urllib3.exceptions import InsecureRequestWarning
import pyttsx3
#关闭安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)defcompound_sound(content,title):'''
合成音频模块
:param content:
:param title:
:return:
'''try:
engine = pyttsx3.init()# 模块初始化str= content
outFile ='./音频文件夹//{}.mp3'.format(title)# 输出格式
rate = engine.getProperty('rate')# 获取语速
engine.setProperty('rate', rate -10)# 调整语速
engine.save_to_file(str, outFile)# 这个位置必须放在播报Unicode字符串前面,# engine.say(str) # 设置要播报的Unicode字符串
engine.runAndWait()# 等待语音播报完毕except Exception as e:print('合成出错!!!')print(e)defstart_make():'''发送请求获取段子,并合成音频'''
url ='https://ishuo.cn/duanzi'
headers ={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
res = requests.get(url,headers=headers,verify=False).text
# print(res)
html = etree.HTML(res)
li_list = html.xpath("//div[@id='content']/div[@id='list']/ul/li")[:10]for li in li_list:
content = li.xpath('./div[1]/text()')[0]
title = li.xpath('./div[2]/a/text()')[0]# print(content,title)
compound_sound(content,title)print(title,'合成音频成功...')if __name__ =='__main__':
start_make()
效果和百度AI一样(就是声音没有百度AI的度米朵好听):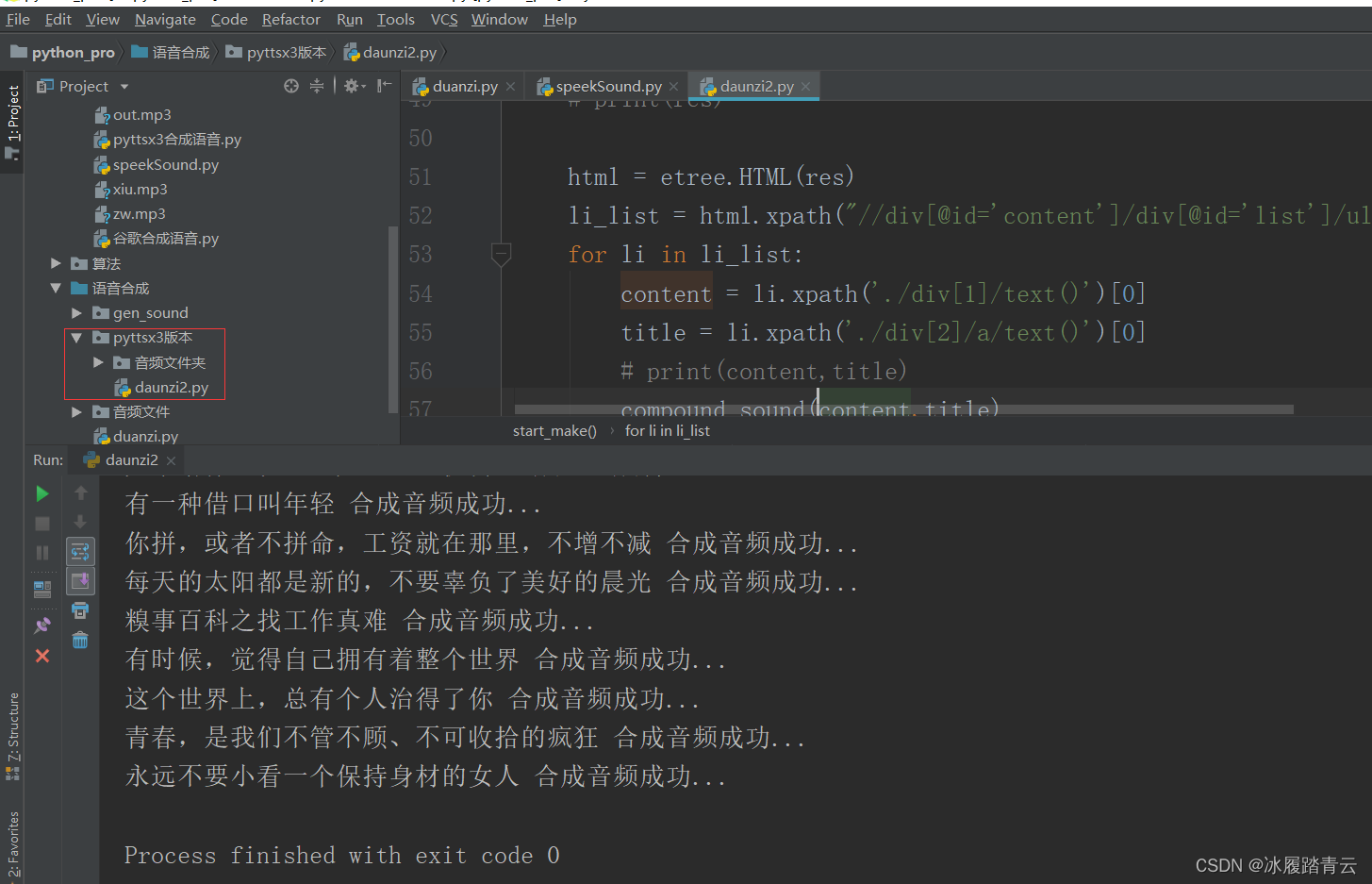
我将月亮缝入躯体,葬自我于山谷,如果那一天野花疯长,那便是我在讲
文章到此结束,欢迎一键三连,点个赞,收个藏啥的,我有故事你有酒,好好交流不分手!哈哈哈!下次见!
版权归原作者 冰履踏青云 所有, 如有侵权,请联系我们删除。