BraTS2021脑肿瘤分割实战
脑肿瘤分割是MICCAI所有比赛中历史最悠久的,到2021年已经连续举办了10年,参赛人数众多,是学习医学图像分割最前沿的平台之一。简介: 胶质母细胞瘤和具有胶质母细胞瘤分子特征的弥漫性星形细胞胶质瘤(WHO 4 级星形细胞瘤)是成人中枢神经系统最常见和最具侵袭性的恶性原发性肿瘤,在外观、形状和组
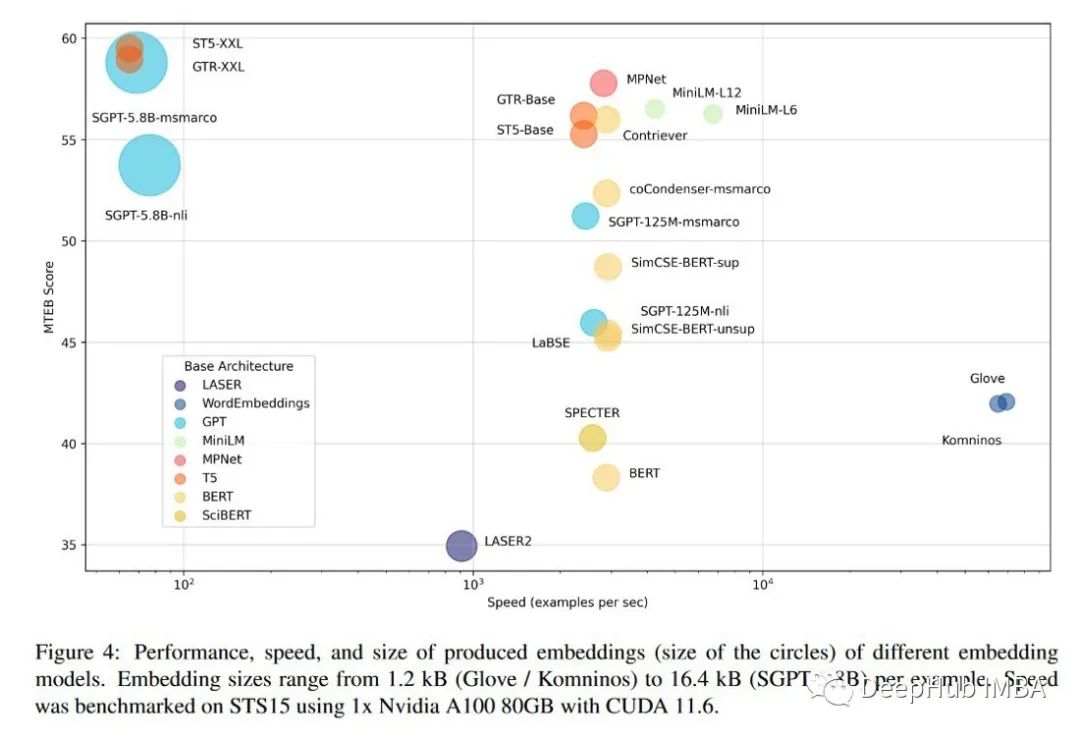
2022年11月10篇论文推荐
介绍10篇推荐的论文。这里将涵盖强化学习(RL)、扩散模型、自动驾驶、语言模型等主题。
利用yolov5实现口罩佩戴检测算法(非常详细)
帮助你快速掌握利用yolov5来训练口罩佩戴检测模型。
YOLOv7(目标检测)入门教程详解---检测,推理,训练
零基础入门yolov7,从环境配置到检测,推理,训练,再到c++预测
机器学习中的数学——距离定义(一):欧几里得距离(Euclidean Distance)
欧几里得距离或欧几里得度量是欧几里得空间中两点间的即直线距离。使用这个距离,欧氏空间成为度量空间,相关联的范数称为欧几里得范数。nnn维空间中的欧几里得距离:d(x,y)=∑i=1n(xi−yi)2=(x1−y1)2+(x2−y2)2+⋯+(xn−yn)2d(x, y)=\sqrt{\sum_{i=
MMPose姿态估计+人体关键点识别效果演示
MMPose开源姿态估计算法库,进行了人体关键点的效果演示。(包括肢体,手部和全身的关键点,还尝试了MMPose实时效果)
TensorFlow和CUDA、cudnn、Pytorch以及英伟达显卡对应版本对照表
TensorFlow和CUDA、cudnn、Pytorch以及英伟达显卡对应版本对照表CUDA下载地址CUDNN下载地址torch下载英伟达显卡下载一、TensorFlow对应版本对照表版本Python 版本编译器cuDNNCUDAtensorflow-2.9.03.7-3.108.111.2ten
swin-transformer详解及代码复现
1. swin-transformer网络结构实际上,我们在进行代码复现时应该是下图,接下来我们根据下面的图片进行分段实现2. Patch Partition & Patch Embedding首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch
coco数据集解析及读取方法
RLE所占字节的大小和边界上的像素数量是正相关的。其中size是这幅图片的宽高,然后在这幅图像中,每一个像素点要么在被分割(标注)的目标区域中,要么在背景中。每个对象(不管是iscrowd=0还是iscrowd=1)都会有一个矩形框bbox ,矩形框左上角的坐标和矩形框的长宽会以数组的形式提供,数组
超分之EDSR
这篇文章是SRResnet的升级版——EDSR,其对网络结构进行了优化(去除了BN层),省下来的空间可以用于提升模型的size来增强表现力。此外,作者提出了一种基于EDSR且适用于多缩放尺度的超分结构——MDSR。EDSR在2017年赢得了NTIRE2017超分辨率挑战赛的冠军。参考目录:①深度学习
云GPU(恒源云)训练的具体操作流程
主要介绍一下如何使用云服务器平台训练网络,包括pycharm配置、数据传输、服务器如何使用等
深度学习之BP神经网络
算法是神经网络深度学习中最重要的算法之一,是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的神经网络模型之一。基本结构如图:其主要包含三部分(由左到右)1:输入层:输入数据2:隐含层:输入与输出之间的数据分析加工厂,通过各种参数(权重,偏差值)以及激活函数等其他数据处理方法与两边建立联

Stable Diffusion的入门介绍和使用教程
Stable Diffusion是一个文本到图像的潜在扩散模型,本文将介绍如何使用Stable Diffusion以及它具体工作的原理
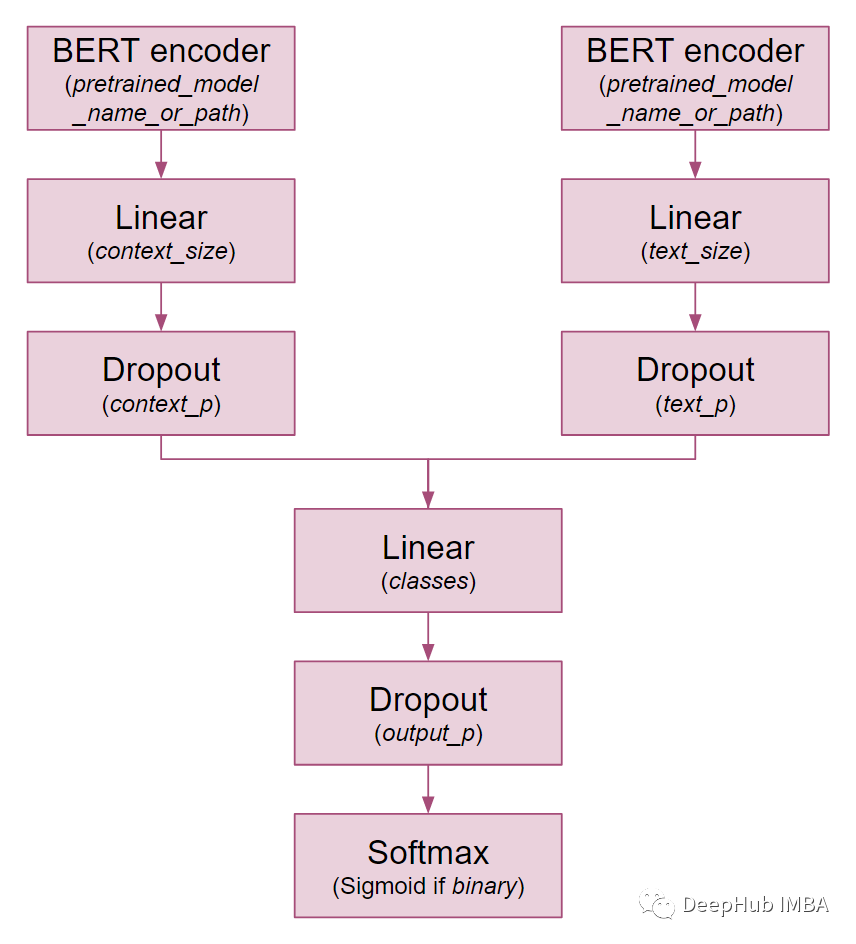
TwoModalBERT进行角色分类
魔改模型,不一定有用,但很好玩
学习Transformer:自注意力与多头自注意力的原理及实现
自从Transformer[3]模型在NLP领域问世后,基于Transformer的深度学习模型性能逐渐在NLP和CV领域(Vision Transformer)取得了令人惊叹的提升。本文的主要目的是介绍经典Transformer模型和Vision Transformer的技术细节及基本原理,以方便
pytorch训练模型时出现nan原因整合
常见原因-1一般来说,出现NaN有以下几种情况:相信很多人都遇到过训练一个deep model的过程中,loss突然变成了NaN。在这里对这个问题做一个总结:1.如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为你的学习率过高,需要降低学习率。可以不断降低学习率直至不出现NaN为止,一般来
BertTokenizer 使用方法
BertTokenizer 使用方法,BertTokenizer 函数详解,tokenizer使用方法
Transformer框架时间序列模型Informer内容与代码解读
Transformer框架时间序列模型Informer内容与代码解读。详细介绍概括了顶会论文AAAI‘21 Best Paper的核心内容。
DDPM代码详细解读(1):数据集准备、超参数设置、loss设计、关键参数计算
Diffusion Models专栏文章汇总:入门与实战前言:大部分DDPM相关的论文代码都是基于《Denoising Diffusion Probabilistic Models》和《Diffusion Models Beat GANs on Image Synthesis》贡献代码基础上小改动的
Vision Transformer 论文 + 详解( ViT )
Vision Transformer 论文 + 详解



